DogMo: A Large-Scale Multi-View RGB-D Dataset for 4D Canine Motion Recovery
作者: Zan Wang, Siyu Chen, Luya Mo, Xinfeng Gao, Yuxin Shen, Lebin Ding, Wei Liang
分类: cs.CV
发布日期: 2025-10-28
备注: 19 pages
💡 一句话要点
DogMo:用于四足动物运动恢复的大规模多视角RGB-D数据集
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 犬类运动恢复 多视角RGB-D数据集 SMAL模型 动物行为建模 计算机视觉
📋 核心要点
- 现有犬类运动数据集缺乏多视角信息、真实3D数据,且规模和多样性有限,阻碍了相关研究的进展。
- DogMo数据集通过多视角RGB-D视频捕捉不同犬类的运动,并提出三阶段优化流程拟合SMAL模型,实现精确运动恢复。
- 该数据集建立了四个运动恢复基准,支持不同输入类型的系统评估,为犬类运动恢复研究提供基础。
📝 摘要(中文)
本文提出了DogMo,一个大规模多视角RGB-D视频数据集,用于捕捉各种犬类运动,旨在从图像中恢复运动。DogMo包含来自10只不同犬类的1.2k个运动序列,在运动和品种上提供了丰富的变化。它解决了现有犬类运动数据集的关键局限性,包括缺乏多视角和真实3D数据,以及有限的规模和多样性。利用DogMo,我们建立了四个运动恢复基准设置,支持单目和多视角、RGB和RGB-D输入之间的系统评估。为了促进准确的运动恢复,我们进一步引入了一个三阶段、特定实例的优化流程,将SMAL模型拟合到运动序列。我们的方法通过粗略对齐、密集对应监督和时间正则化逐步细化身体形状和姿势。我们的数据集和方法为推进犬类运动恢复研究提供了原则性基础,并在计算机视觉、计算机图形学和动物行为建模的交叉领域开辟了新的方向。
🔬 方法详解
问题定义:现有犬类运动数据集在规模、多样性、视角和3D信息上存在不足,难以支持复杂场景下的精确运动恢复。缺乏高质量的数据集阻碍了相关算法的开发和评估。
核心思路:通过构建大规模多视角RGB-D数据集,提供丰富的运动和品种变化,克服现有数据集的局限性。同时,设计实例特定的优化流程,利用SMAL模型进行运动序列的拟合,从而实现精确的犬类运动恢复。
技术框架:该方法包含三个主要阶段:1) 粗略对齐:使用初始姿势估计对SMAL模型进行粗略对齐。2) 密集对应监督:利用RGB-D数据建立密集对应关系,优化模型形状和姿势。3) 时间正则化:通过时间一致性约束,平滑运动序列,提高运动恢复的稳定性。
关键创新:该方法的关键创新在于构建了大规模多视角RGB-D犬类运动数据集,并提出了一个三阶段的实例特定优化流程,该流程结合了粗略对齐、密集对应监督和时间正则化,能够有效地拟合SMAL模型,实现精确的运动恢复。
关键设计:数据集包含1.2k个运动序列,来自10只不同的犬类。优化流程使用SMAL模型作为先验知识,通过最小化形状和姿势误差、对应关系误差和时间不一致性误差来优化模型参数。时间正则化采用平滑损失函数,鼓励相邻帧之间的运动平滑过渡。
🖼️ 关键图片

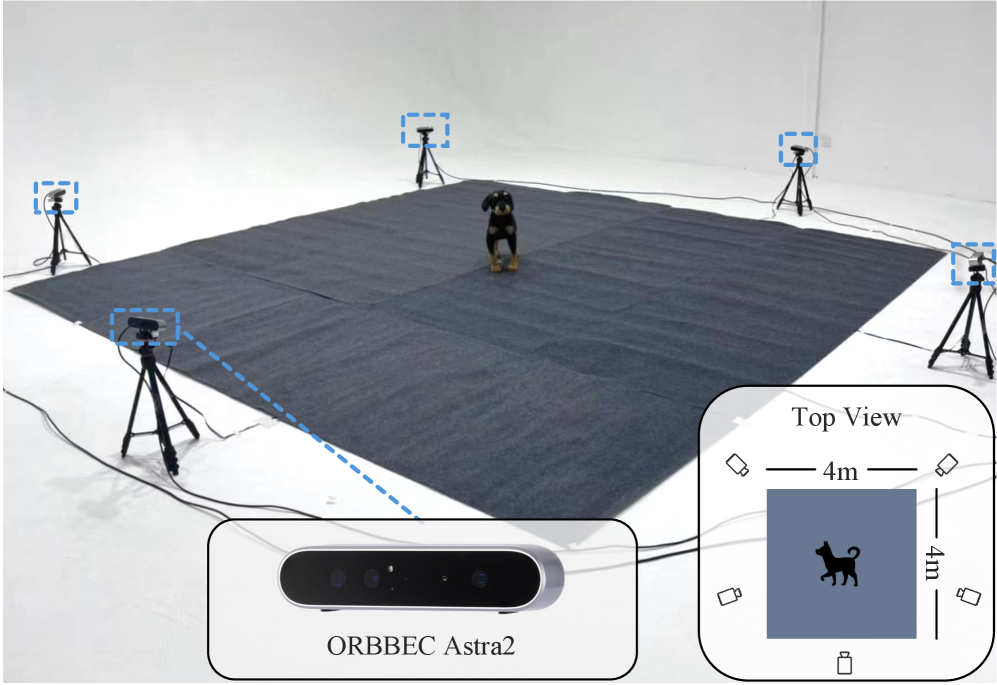

📊 实验亮点
论文构建了包含1.2k个运动序列的大规模DogMo数据集,并提出了三阶段优化流程。实验结果表明,该方法在运动恢复任务上取得了显著的性能,为后续研究奠定了基础。该数据集和方法为犬类运动恢复研究提供了新的基准和方向。
🎯 应用场景
该研究成果可应用于动物行为分析、虚拟现实、游戏开发、机器人控制等领域。例如,可以用于创建更逼真的犬类动画,训练机器人犬完成特定任务,或者帮助兽医分析犬类的运动模式,从而诊断疾病或评估康复效果。该数据集和方法为相关领域的研究提供了宝贵的资源和基础。
📄 摘要(原文)
We present DogMo, a large-scale multi-view RGB-D video dataset capturing diverse canine movements for the task of motion recovery from images. DogMo comprises 1.2k motion sequences collected from 10 unique dogs, offering rich variation in both motion and breed. It addresses key limitations of existing dog motion datasets, including the lack of multi-view and real 3D data, as well as limited scale and diversity. Leveraging DogMo, we establish four motion recovery benchmark settings that support systematic evaluation across monocular and multi-view, RGB and RGB-D inputs. To facilitate accurate motion recovery, we further introduce a three-stage, instance-specific optimization pipeline that fits the SMAL model to the motion sequences. Our method progressively refines body shape and pose through coarse alignment, dense correspondence supervision, and temporal regularization. Our dataset and method provide a principled foundation for advancing research in dog motion recovery and open up new directions at the intersection of computer vision, computer graphics, and animal behavior modeling.