UHKD: A Unified Framework for Heterogeneous Knowledge Distillation via Frequency-Domain Representations
作者: Fengming Yu, Haiwei Pan, Kejia Zhang, Jian Guan, Haiying Jiang
分类: cs.CV
发布日期: 2025-10-28 (更新: 2025-11-14)
备注: 14 pages, 10 figures
💡 一句话要点
提出UHKD,通过频域特征统一异构模型知识蒸馏框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 异构模型 频域表示 模型压缩 特征对齐
📋 核心要点
- 现有知识蒸馏方法在异构模型上效果不佳,尤其是在利用中间层特征时,架构差异导致语义鸿沟。
- UHKD框架通过频域表示捕获全局语义知识,缓解异构师生模型间的表示差异,实现有效知识迁移。
- 实验结果表明,UHKD在CIFAR-100和ImageNet-1K数据集上显著优于现有异构蒸馏方法,性能提升明显。
📝 摘要(中文)
知识蒸馏(KD)是一种有效的模型压缩技术,它将高性能教师模型的知识传递给轻量级学生模型,从而降低计算和存储成本,同时保持具有竞争力的准确性。然而,现有的大多数KD方法都是为同构模型量身定制的,在异构设置中表现不佳,尤其是在涉及中间特征时。架构之间的语义差异阻碍了教师模型中间表示的有效利用,而先前的异构KD研究主要集中在logits空间,未能充分利用中间层中丰富的语义信息。为了解决这个问题,本文提出了统一异构知识蒸馏(UHKD),该框架利用频域中的中间特征进行跨架构迁移。频域表示用于捕获全局语义知识,并减轻异构师生对之间的表示差异。具体来说,特征变换模块(FTM)生成教师特征的紧凑频域表示,而可学习的特征对齐模块(FAM)投影学生特征并通过多级匹配对齐它们。训练由中间特征上的均方误差和logits上的Kullback-Leibler散度的联合目标引导。在CIFAR-100和ImageNet-1K上的大量实验证明了该方法的有效性,在这两个数据集上分别实现了比最新的异构蒸馏方法的最大增益5.59%和0.83%。代码即将发布。
🔬 方法详解
问题定义:现有知识蒸馏方法在异构模型上进行知识迁移时,由于不同架构的网络结构和特征表示存在差异,导致中间层特征的语义鸿沟问题,使得学生模型难以有效地学习教师模型的知识。以往的异构知识蒸馏方法主要关注logits层的知识迁移,忽略了中间层特征中丰富的语义信息。
核心思路:UHKD的核心思路是利用频域表示来弥合异构模型之间的语义鸿沟。通过将中间层特征转换到频域,可以捕获全局语义信息,减少不同架构模型在特征表示上的差异。然后,通过特征对齐模块,将学生模型的特征与教师模型的频域特征进行对齐,从而实现有效的知识迁移。
技术框架:UHKD框架主要包含两个模块:特征变换模块(FTM)和特征对齐模块(FAM)。FTM负责将教师模型的中间层特征转换到频域,生成紧凑的频域表示。FAM负责将学生模型的中间层特征进行投影,并通过多级匹配的方式与教师模型的频域特征进行对齐。整个训练过程由一个联合目标函数引导,该目标函数结合了中间层特征上的均方误差损失和logits层上的Kullback-Leibler散度损失。
关键创新:UHKD的关键创新在于利用频域表示来解决异构模型之间的知识蒸馏问题。通过频域转换,可以有效地捕获全局语义信息,减少不同架构模型在特征表示上的差异。此外,FAM模块通过多级匹配的方式,进一步提高了特征对齐的精度。
关键设计:FTM模块的具体实现方式未知,但其目标是生成教师特征的紧凑频域表示。FAM模块可能包含可学习的线性层或卷积层,用于投影学生特征。损失函数由两部分组成:中间层特征上的均方误差损失用于对齐特征表示,logits层上的Kullback-Leibler散度损失用于迁移分类知识。具体的网络结构和参数设置未知,需要在代码发布后进一步分析。
🖼️ 关键图片
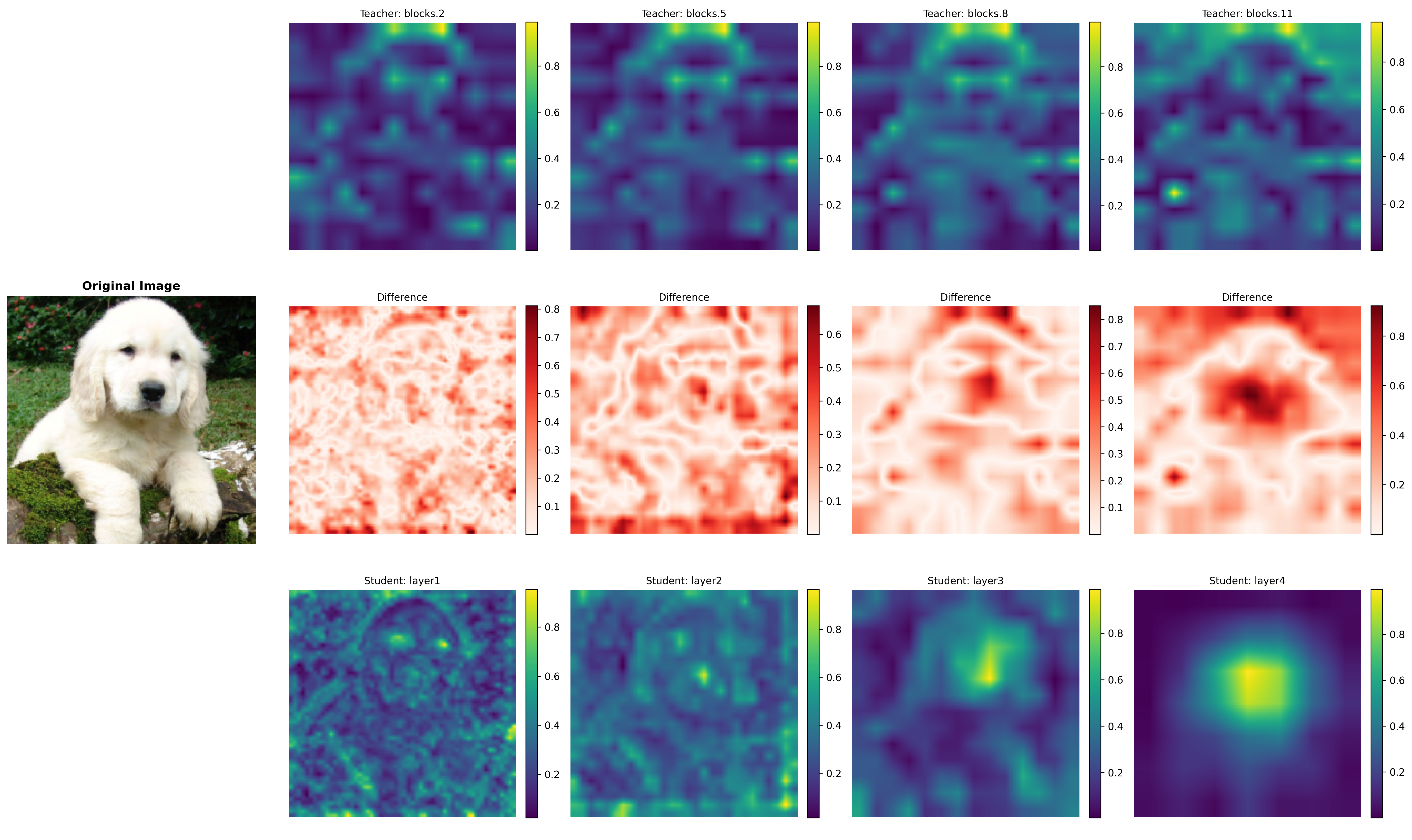


📊 实验亮点
UHKD在CIFAR-100和ImageNet-1K数据集上进行了广泛的实验,结果表明UHKD显著优于现有的异构知识蒸馏方法。在CIFAR-100数据集上,UHKD取得了高达5.59%的性能提升;在ImageNet-1K数据集上,UHKD取得了0.83%的性能提升。这些结果表明,UHKD能够有效地解决异构模型之间的知识蒸馏问题。
🎯 应用场景
UHKD框架可应用于各种需要模型压缩和加速的场景,例如移动设备上的图像识别、自动驾驶中的目标检测等。通过将大型教师模型的知识迁移到小型学生模型,可以在保证模型性能的同时,降低计算和存储成本,从而实现更高效的部署和应用。该研究对于推动深度学习模型在资源受限环境中的应用具有重要意义。
📄 摘要(原文)
Knowledge distillation (KD) is an effective model compression technique that transfers knowledge from a high-performance teacher to a lightweight student, reducing computational and storage costs while maintaining competitive accuracy. However, most existing KD methods are tailored for homogeneous models and perform poorly in heterogeneous settings, particularly when intermediate features are involved. Semantic discrepancies across architectures hinder effective use of intermediate representations from the teacher model, while prior heterogeneous KD studies mainly focus on the logits space, underutilizing rich semantic information in intermediate layers. To address this, Unified Heterogeneous Knowledge Distillation (UHKD) is proposed, a framework that leverages intermediate features in the frequency domain for cross-architecture transfer. Frequency-domain representations are leveraged to capture global semantic knowledge and mitigate representational discrepancies between heterogeneous teacher-student pairs. Specifically, a Feature Transformation Module (FTM) generates compact frequency-domain representations of teacher features, while a learnable Feature Alignment Module (FAM) projects student features and aligns them via multi-level matching. Training is guided by a joint objective combining mean squared error on intermediate features with Kullback-Leibler divergence on logits. Extensive experiments on CIFAR-100 and ImageNet-1K demonstrate the effectiveness of the proposed approach, achieving maximum gains of 5.59% and 0.83% over the latest heterogeneous distillation method on the two datasets, respectively. Code will be released soon.