TeleEgo: Benchmarking Egocentric AI Assistants in the Wild
作者: Jiaqi Yan, Ruilong Ren, Jingren Liu, Shuning Xu, Ling Wang, Yiheng Wang, Xinlin Zhong, Yun Wang, Long Zhang, Xiangyu Chen, Changzhi Sun, Jixiang Luo, Dell Zhang, Hao Sun, Chi Zhang, Xuelong Li
分类: cs.CV
发布日期: 2025-10-28 (更新: 2025-12-10)
💡 一句话要点
TeleEgo:构建真实场景下自我中心AI助手的长时程、流式多模态评测基准
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 自我中心视觉 AI助手 多模态学习 长时程记忆 流式数据 评测基准 实时推理
📋 核心要点
- 现有自我中心AI助手评测缺乏真实流式场景,且通常孤立地评估各项能力,难以反映真实应用中的挑战。
- TeleEgo通过构建长时程、流式、全模态数据集,并定义多个诊断子任务,来全面评估AI助手的记忆、理解和推理能力。
- 论文提出了实时准确率(RTA)和记忆持久时间(MPT)等新指标,并提供了基线模型在TeleEgo上的性能表现。
📝 摘要(中文)
本文提出了TeleEgo,一个用于评估真实日常场景中自我中心AI助手的长时程、流式、全模态评测基准。该数据集包含每位参与者超过14小时的同步自我中心视频、音频和文本数据,涵盖工作学习、生活日常、社交活动和郊游文化四个领域。所有数据都对齐到统一的全局时间线,并包含高质量的视觉叙述和语音转录,这些都经过人工优化。TeleEgo定义了跨越记忆、理解和跨记忆推理三个核心能力的12个诊断子任务。它包含3291个经过人工验证的问答条目,涵盖多种问题格式,并在严格的流式设置中进行评估。本文提出了实时准确率(RTA)来共同捕捉在严格决策窗口下的正确性和响应性,以及记忆持久时间(MPT)作为连续流中长期保留的前瞻性指标。本文报告了当前模型的RTA结果,并发布TeleEgo以及MPT评估框架,作为一个现实且可扩展的基准,用于未来具有更强流式记忆的自我中心助手,从而能够系统地研究实时行为和长时程记忆。
🔬 方法详解
问题定义:现有自我中心AI助手的评测基准通常关注孤立的能力,缺乏对真实世界中长时程、流式多模态数据的处理能力评估。现有方法难以模拟真实场景下AI助手需要实时响应并长期记忆的挑战。
核心思路:TeleEgo的核心思路是构建一个更贴近真实场景的评测基准,包含长时间的同步多模态数据流,并设计相应的评估指标,以全面衡量AI助手在记忆、理解和跨记忆推理方面的能力。通过模拟真实世界的复杂性和连续性,更有效地评估AI助手的性能。
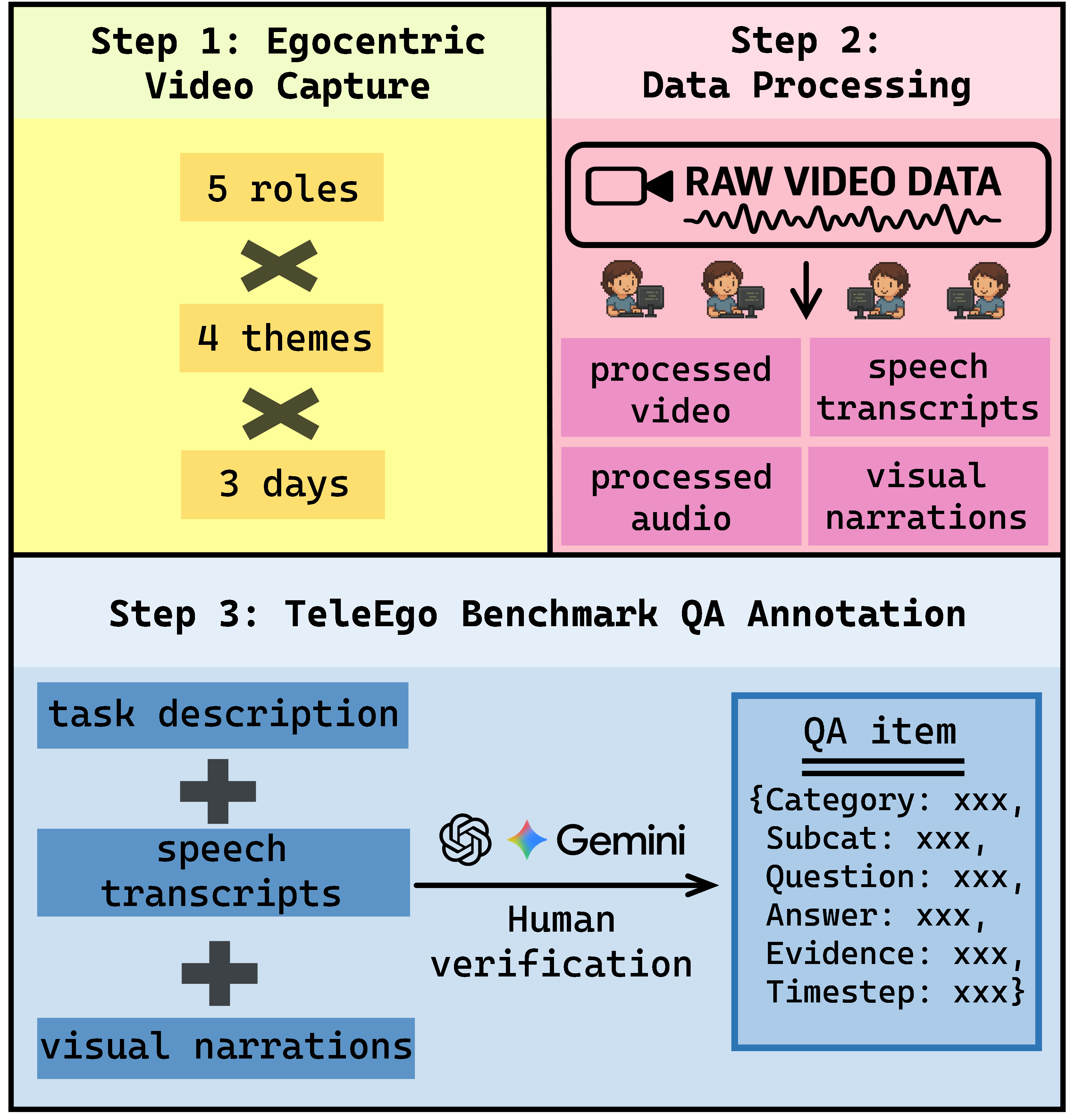
技术框架:TeleEgo数据集包含同步的自我中心视频、音频和文本数据,涵盖四个领域。数据经过人工校正,保证了高质量的视觉叙述和语音转录。基于此,定义了12个诊断子任务,涵盖记忆(回忆过去事件)、理解(解释当前时刻)和跨记忆推理(连接遥远事件)三个核心能力。评估过程采用流式设置,即模型需要根据时间顺序处理数据并做出决策。
关键创新:TeleEgo的关键创新在于其数据集的真实性和全面性,以及评估指标的针对性。数据集模拟了真实世界中AI助手需要处理的复杂、连续的多模态数据流。提出的实时准确率(RTA)和记忆持久时间(MPT)指标,能够更全面地评估AI助手在实时性和长期记忆方面的性能。与现有方法相比,TeleEgo更注重评估AI助手在真实场景下的综合能力。
关键设计:TeleEgo数据集包含超过14小时/人的数据,涵盖四个领域。数据集中的数据经过人工校正,保证了高质量。评估指标RTA考虑了正确性和响应时间,MPT则评估了模型长期记忆的能力。具体来说,RTA的计算方式未知,MPT的计算方式也未知,但其核心思想是评估模型在多长时间后还能准确回忆起相关信息。
🖼️ 关键图片
📊 实验亮点
TeleEgo数据集包含超过14小时/人的多模态数据,涵盖四个领域,并定义了12个诊断子任务。论文提出了实时准确率(RTA)和记忆持久时间(MPT)等新指标,并提供了基线模型在TeleEgo上的RTA结果。具体性能数据未知,但该基准为未来自我中心AI助手的研究提供了一个现实且可扩展的平台。
🎯 应用场景
TeleEgo的研究成果可应用于开发更智能、更实用的自我中心AI助手,例如智能家居助手、可穿戴设备助手等。这些助手可以帮助用户更好地管理日常生活、提高工作效率、改善社交体验。此外,该基准也可促进多模态理解、长期记忆和实时推理等相关技术的发展。
📄 摘要(原文)
Egocentric AI assistants in real-world settings must process multi-modal inputs (video, audio, text), respond in real time, and retain evolving long-term memory. However, existing benchmarks typically evaluate these abilities in isolation, lack realistic streaming scenarios, or support only short-term tasks. We introduce \textbf{TeleEgo}, a long-duration, streaming, omni-modal benchmark for evaluating egocentric AI assistants in realistic daily contexts. The dataset features over 14 hours per participant of synchronized egocentric video, audio, and text across four domains: work \& study, lifestyle \& routines, social activities, and outings \& culture. All data is aligned on a unified global timeline and includes high-quality visual narrations and speech transcripts, curated through human refinement.TeleEgo defines 12 diagnostic subtasks across three core capabilities: Memory (recalling past events), Understanding (interpreting the current moment), and Cross-Memory Reasoning (linking distant events). It contains 3,291 human-verified QA items spanning multiple question formats (single-choice, binary, multi-choice, and open-ended), evaluated strictly in a streaming setting. We propose Real-Time Accuracy (RTA) to jointly capture correctness and responsiveness under tight decision windows, and Memory Persistence Time (MPT) as a forward-looking metric for long-term retention in continuous streams. In this work, we report RTA results for current models and release TeleEgo, together with an MPT evaluation framework, as a realistic and extensible benchmark for future egocentric assistants with stronger streaming memory, enabling systematic study of both real-time behavior and long-horizon memory.