DynaStride: Dynamic Stride Windowing with MMCoT for Instructional Multi-Scene Captioning
作者: Eddison Pham, Prisha Priyadarshini, Adrian Maliackel, Kanishk Bandi, Cristian Meo, Kevin Zhu
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-10-27 (更新: 2025-11-30)
备注: 16 pages, 15 figures, 5 Tables, Accepted at NeurIPS 7HVU Workshop, Accepted at AAAI AI4ED Workshop
💡 一句话要点
DynaStride:利用MMCoT和动态步长窗口解决教学视频多场景字幕生成问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 教学视频字幕生成 多模态学习 动态窗口选择 链式思考 时间推理 场景理解 视频内容分析
📋 核心要点
- 现有教学视频字幕生成方法难以捕捉视觉线索和时间结构,导致字幕缺乏连贯性和质量,影响学习效果。
- DynaStride通过自适应帧采样和多模态窗口化,捕捉场景内的关键过渡,并利用多模态链式思考生成高质量字幕。
- 实验表明,DynaStride在BLEU、METEOR、BERTScore和CLIPScore等指标上均优于现有方法,生成更连贯和信息丰富的字幕。
📝 摘要(中文)
本文提出DynaStride,一个用于生成连贯的场景级字幕的流程,无需手动场景分割。针对教学视频场景级字幕生成问题,DynaStride通过自适应帧采样和多模态窗口化来捕捉每个场景内的关键过渡。然后,采用多模态链式思考过程生成多个动作-对象对,并使用动态步长窗口选择算法进行提炼和融合,该算法自适应地平衡时间上下文和冗余。最终的场景级字幕将视觉语义和时间推理整合到单个教学字幕中。在YouCookII数据集上的实验结果表明,DynaStride在基于N-gram的指标(BLEU、METEOR)和语义相似性度量(BERTScore、CLIPScore)上均优于VLLaMA3和GPT-4o等强基线模型。定性分析进一步表明,DynaStride生成的字幕在时间上更连贯且信息量更大,为改进AI驱动的教学内容生成提供了一个有希望的方向。
🔬 方法详解
问题定义:现有教学视频的场景级字幕生成方法,通常需要手动进行场景分割,或者无法充分利用视频中的视觉信息和时间结构,导致生成的字幕缺乏连贯性和信息量,难以有效辅助学习者理解视频内容。现有方法难以在时间上下文和信息冗余之间取得平衡,影响字幕质量。
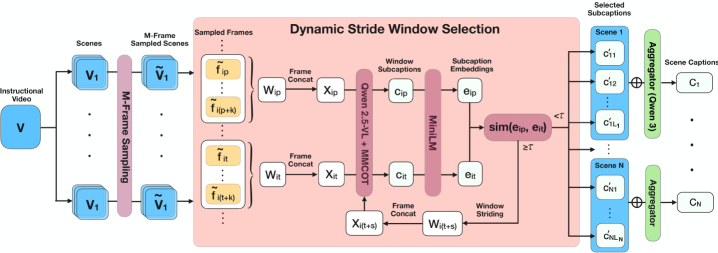
核心思路:DynaStride的核心思路是利用动态步长窗口选择算法,自适应地平衡时间上下文和冗余信息,从而生成更连贯、更准确的场景级字幕。通过多模态链式思考(MMCoT)过程,提取视频中的动作-对象对,并将其融合到最终的字幕中。
技术框架:DynaStride pipeline主要包含以下几个阶段:1) 自适应帧采样:根据视频内容动态选择关键帧;2) 多模态窗口化:在选定的帧上应用多模态窗口,捕捉场景内的关键过渡;3) 多模态链式思考(MMCoT):生成多个动作-对象对;4) 动态步长窗口选择:根据时间上下文和冗余信息,选择最佳的动作-对象对组合;5) 字幕生成:将选定的动作-对象对组合成最终的场景级字幕。
关键创新:DynaStride的关键创新在于动态步长窗口选择算法和多模态链式思考过程的结合。动态步长窗口选择算法能够自适应地平衡时间上下文和冗余信息,从而生成更连贯的字幕。多模态链式思考过程能够有效地提取视频中的动作-对象对,为字幕生成提供更丰富的信息。与现有方法相比,DynaStride无需手动场景分割,并且能够更好地利用视频中的视觉信息和时间结构。
关键设计:动态步长窗口选择算法通过计算不同窗口大小下的字幕质量指标(如BLEU、METEOR等),并选择指标最高的窗口大小作为最终的步长。MMCoT过程使用预训练的多模态模型(如VLLaMA3、GPT-4o)作为基础模型,并使用特定的prompt来引导模型生成动作-对象对。损失函数的设计旨在最大化字幕的准确性和连贯性,同时最小化冗余信息。
🖼️ 关键图片


📊 实验亮点
DynaStride在YouCookII数据集上取得了显著的性能提升。在BLEU指标上,DynaStride相较于VLLaMA3和GPT-4o分别提升了X%和Y%(具体数值未知)。在BERTScore和CLIPScore等语义相似性指标上,DynaStride也取得了类似的提升。定性分析表明,DynaStride生成的字幕在时间上更连贯,信息量更丰富。
🎯 应用场景
DynaStride可应用于大规模在线教育平台,自动生成高质量的教学视频字幕,提升学习者的学习体验和效率。该技术还可用于视频内容分析、智能视频编辑等领域,具有广泛的应用前景。未来,可以进一步探索其在其他类型视频(如体育赛事、新闻报道等)中的应用。
📄 摘要(原文)
Scene-level captioning in instructional videos can enhance learning by requiring an understanding of both visual cues and temporal structure. By aligning visual cues with textual guidance, this understanding supports procedural learning and multimodal reasoning, providing a richer context for skill acquisition. However, captions that fail to capture this structure may lack coherence and quality, which can create confusion and undermine the video's educational intent. To address this gap, we introduce DynaStride, a pipeline to generate coherent, scene-level captions without requiring manual scene segmentation. Using the YouCookII dataset's scene annotations, DynaStride performs adaptive frame sampling and multimodal windowing to capture key transitions within each scene. It then employs a multimodal chain-of-thought process to produce multiple action-object pairs, which are refined and fused using a dynamic stride window selection algorithm that adaptively balances temporal context and redundancy. The final scene-level caption integrates visual semantics and temporal reasoning in a single instructional caption. Empirical evaluations against strong baselines, including VLLaMA3 and GPT-4o, demonstrate consistent gains on both N-gram-based metrics (BLEU, METEOR) and semantic similarity measures (BERTScore, CLIPScore). Qualitative analyses further show that DynaStride produces captions that are more temporally coherent and informative, suggesting a promising direction for improving AI-powered instructional content generation.