Improving Visual Discriminability of CLIP for Training-Free Open-Vocabulary Semantic Segmentation
作者: Jinxin Zhou, Jiachen Jiang, Zhihui Zhu
分类: cs.CV
发布日期: 2025-10-27
备注: 23 pages, 10 figures, 14 tables
💡 一句话要点
提出LHT-CLIP,无需训练即可提升CLIP在开放词汇语义分割中的视觉区分性
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇语义分割 CLIP模型 视觉区分性 无需训练 注意力机制
📋 核心要点
- CLIP预训练目标与像素级语义分割存在偏差,导致直接应用效果不佳。
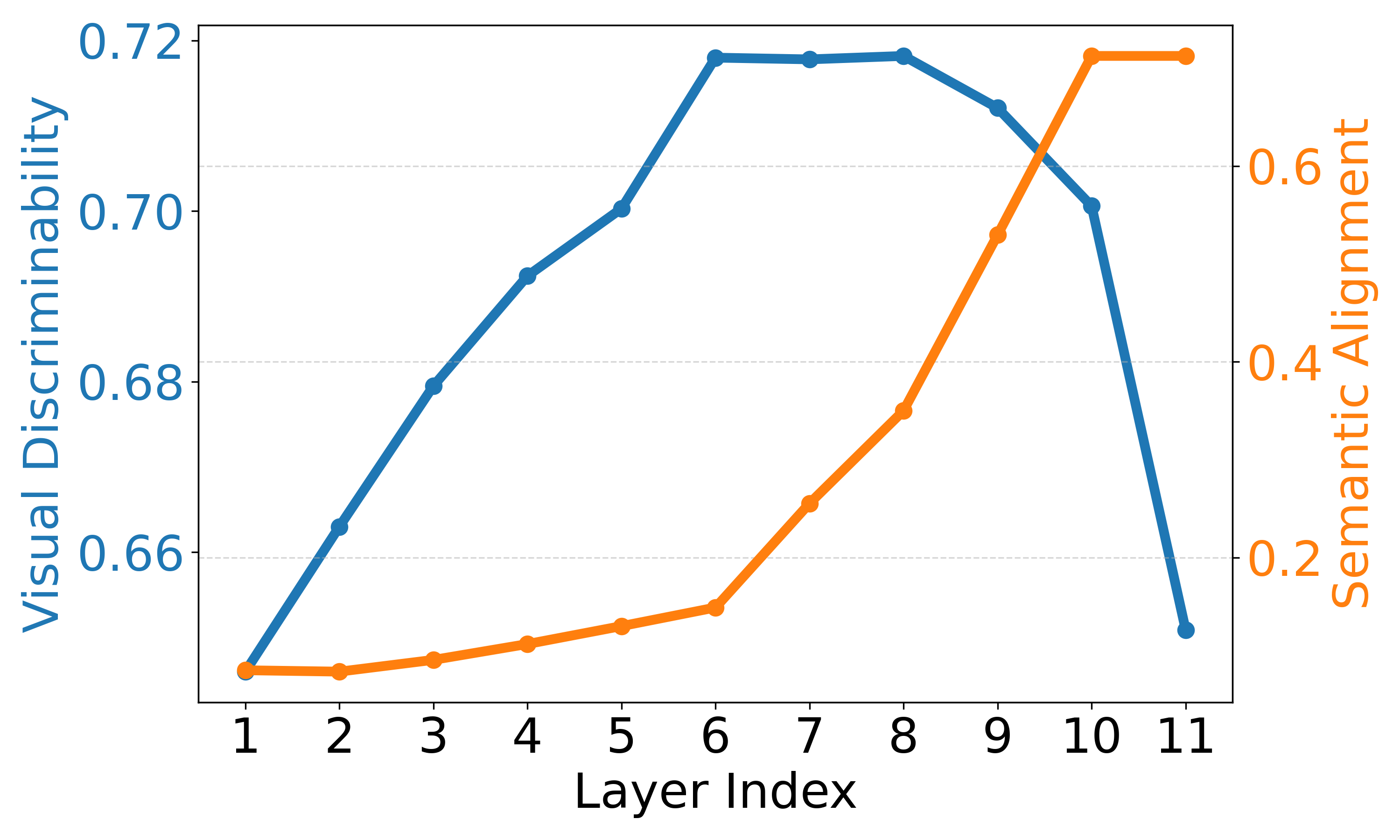
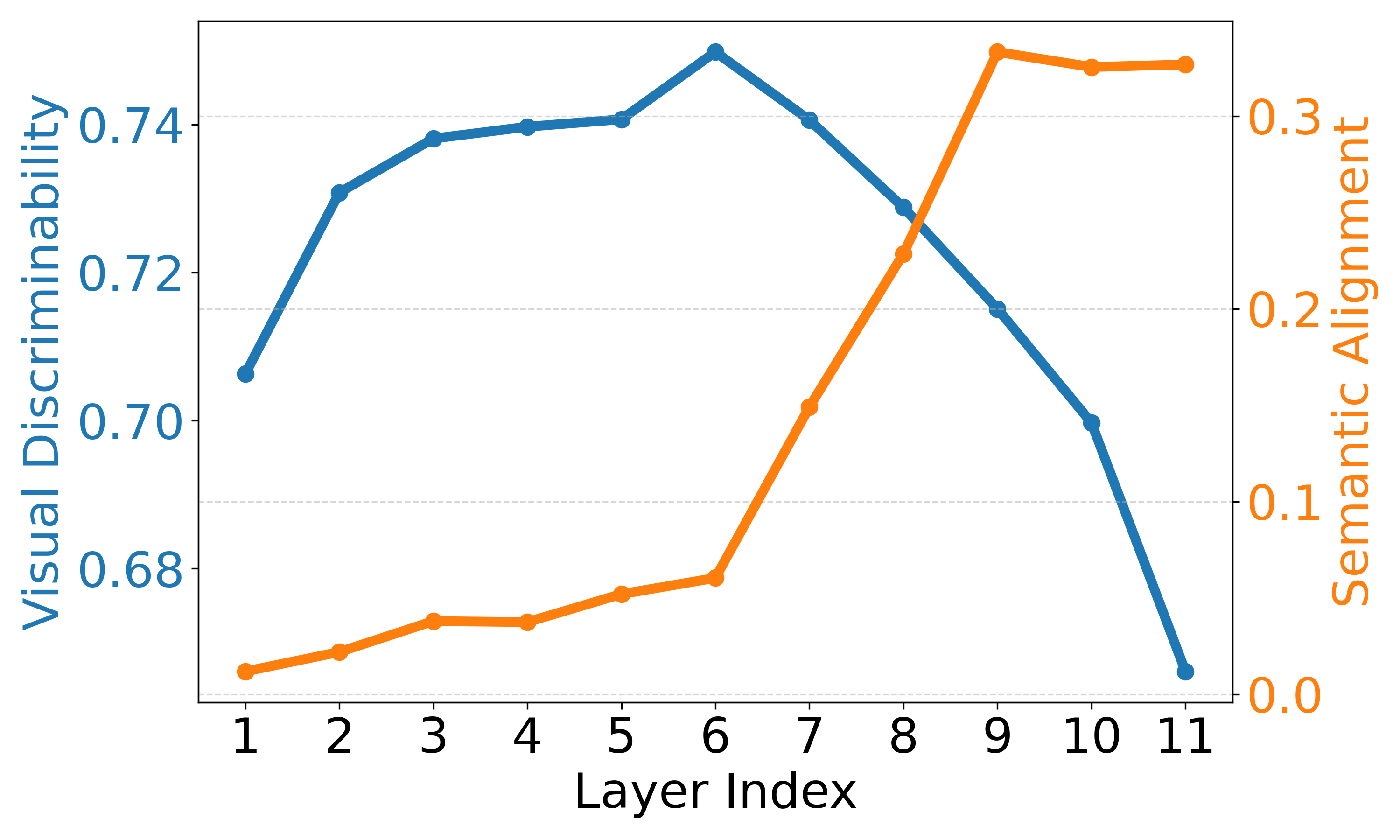
- LHT-CLIP通过分析CLIP各层、头、token的视觉区分性,提出针对性增强策略。
- LHT-CLIP无需额外训练,在多个语义分割数据集上达到SOTA性能。
📝 摘要(中文)
将CLIP模型扩展到语义分割仍然具有挑战性,因为其图像级别的预训练目标与密集预测所需的像素级别视觉理解不一致。虽然之前的工作通过重组最后一层和特征取得了令人鼓舞的结果,但它们通常继承了前面层的全局对齐偏差,导致次优的分割性能。本文提出了LHT-CLIP,一种新颖的无需训练的框架,系统地利用CLIP在层、头和token级别的视觉区分性。通过全面的分析,我们揭示了三个关键见解:(i)最后一层主要加强图像-文本对齐,牺牲了视觉区分性(例如,ViT-B/16中的最后3层和ViT-L/14中的8层),部分原因是异常token的出现;(ii)一部分注意力头(例如,ViT-B/16中的144个头中的10个)在数据集上表现出一致的强视觉区分性;(iii)与正常token相比,异常token显示出稀疏且一致的激活模式。基于这些发现,我们提出了三种互补技术:语义-空间重加权、选择性头增强和异常token替换,以有效地恢复视觉区分性并提高分割性能,而无需任何额外的训练、辅助预训练网络或广泛的超参数调整。在8个常见的语义分割基准上的大量实验表明,LHT-CLIP在各种场景中实现了最先进的性能,突出了其有效性和实际部署性。
🔬 方法详解
问题定义:现有的CLIP模型在图像级别的预训练目标与像素级别的语义分割任务存在不匹配,导致直接应用CLIP模型进行语义分割的效果不佳。即使通过重组CLIP的最后一层和特征,也难以克服前面层存在的全局对齐偏差,从而限制了分割性能的提升。现有方法需要额外的训练或者微调,增加了计算成本和部署难度。
核心思路:本文的核心思路是充分挖掘CLIP模型内部各层、各个注意力头以及各个token的视觉区分能力。通过分析发现,CLIP的最后一层为了更好地进行图像-文本对齐,牺牲了视觉区分性;部分注意力头具有更强的视觉区分能力;以及存在一些异常token,影响了分割性能。因此,通过有针对性地增强具有视觉区分能力的层和头,并抑制异常token的影响,可以提升CLIP在语义分割任务中的性能。
技术框架:LHT-CLIP框架主要包含三个模块:语义-空间重加权(Semantic-Spatial Reweighting)、选择性头增强(Selective Head Enhancement)和异常token替换(Abnormal Token Replacement)。首先,语义-空间重加权模块用于抑制最后一层对视觉区分性的负面影响。其次,选择性头增强模块用于增强具有更强视觉区分能力的注意力头。最后,异常token替换模块用于抑制异常token对分割结果的影响。这三个模块是互补的,共同作用以提升CLIP在语义分割任务中的性能。
关键创新:LHT-CLIP的关键创新在于其对CLIP模型内部视觉区分性的深入分析和利用。与以往方法不同,LHT-CLIP不是简单地重组CLIP的最后一层和特征,而是深入挖掘CLIP各层、头和token的视觉区分能力,并提出针对性的增强策略。此外,LHT-CLIP无需额外的训练,降低了计算成本和部署难度。
关键设计:语义-空间重加权模块通过对不同层输出的特征进行加权融合,降低最后一层特征的权重。选择性头增强模块通过分析不同注意力头的视觉区分能力,选择性地增强具有更强视觉区分能力的注意力头。异常token替换模块通过识别异常token,并用其他token的特征进行替换,从而抑制异常token的影响。具体实现细节包括:使用余弦相似度来衡量注意力头的视觉区分能力,使用阈值来识别异常token等。
🖼️ 关键图片

📊 实验亮点
LHT-CLIP在8个常见的语义分割基准上取得了state-of-the-art的性能,证明了其有效性。例如,在ADE20K数据集上,LHT-CLIP的mIoU指标超过了现有最佳方法,且无需任何额外的训练或微调。实验结果表明,LHT-CLIP能够有效地恢复CLIP的视觉区分性,并显著提升语义分割性能。
🎯 应用场景
该研究成果可应用于自动驾驶、遥感图像分析、医学图像分割等领域。通过提升CLIP在语义分割任务中的性能,可以提高这些应用场景中对图像的理解和分析能力,从而实现更精确的目标识别、场景理解和决策支持。无需训练的特性也使得该方法更易于部署和应用。
📄 摘要(原文)
Extending CLIP models to semantic segmentation remains challenging due to the misalignment between their image-level pre-training objectives and the pixel-level visual understanding required for dense prediction. While prior efforts have achieved encouraging results by reorganizing the final layer and features, they often inherit the global alignment bias of preceding layers, leading to suboptimal segmentation performance. In this work, we propose LHT-CLIP, a novel training-free framework that systematically exploits the visual discriminability of CLIP across layer, head, and token levels. Through comprehensive analysis, we reveal three key insights: (i) the final layers primarily strengthen image-text alignment with sacrifice of visual discriminability (e.g., last 3 layers in ViT-B/16 and 8 layers in ViT-L/14), partly due to the emergence of anomalous tokens; (ii) a subset of attention heads (e.g., 10 out of 144 in ViT-B/16) display consistently strong visual discriminability across datasets; (iii) abnormal tokens display sparse and consistent activation pattern compared to normal tokens. Based on these findings, we propose three complementary techniques: semantic-spatial reweighting, selective head enhancement, and abnormal token replacement to effectively restore visual discriminability and improve segmentation performance without any additional training, auxiliary pre-trained networks, or extensive hyperparameter tuning. Extensive experiments on 8 common semantic segmentation benchmarks demonstrate that LHT-CLIP achieves state-of-the-art performance across diverse scenarios, highlighting its effectiveness and practicality for real-world deployment.