CountFormer: A Transformer Framework for Learning Visual Repetition and Structure in Class-Agnostic Object Counting
作者: Md Tanvir Hossain, Akif Islam, Mohd Ruhul Ameen
分类: cs.CV, cs.AI
发布日期: 2025-10-27
备注: 6 pages, 2 tables, 6 figures. Submitted to IEEE 5th International Conference on Electrical, Computer and Telecommunication Engineering (ICECTE 2025)
💡 一句话要点
CountFormer:基于Transformer的无类别物体计数,学习视觉重复与结构
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 物体计数 Transformer DINOv2 自监督学习 视觉重复 结构感知 密度图 无类别计数
📋 核心要点
- 现有计数模型难以处理复杂形状、内部对称或重叠的物体,无法有效模仿人类的视觉重复和结构关系感知能力。
- CountFormer利用DINOv2提取更丰富的空间特征,并通过位置嵌入融合保留几何关系,从而学习视觉重复和结构连贯性。
- 实验表明,CountFormer在FSC-147数据集上表现出与SOTA方法相当的性能,并在结构复杂场景中表现出更高的准确性。
📝 摘要(中文)
本文提出CountFormer,一个基于Transformer的框架,用于学习视觉重复和结构连贯性,从而实现与类别无关的物体计数。该模型基于CounTR架构,并用自监督预训练模型DINOv2替换了其视觉编码器,以产生更丰富和空间一致的特征表示。此外,模型还结合了位置嵌入融合,以保留几何关系,然后通过轻量级卷积解码器将这些特征解码为密度图。在FSC-147数据集上的评估结果表明,该模型在结构复杂或密集场景中表现出卓越的准确性,性能与当前最先进的方法相当。研究结果表明,集成DINOv2等基础模型使计数系统能够接近人类般的结构感知,从而朝着真正通用和无样本的计数范例迈进。
🔬 方法详解
问题定义:现有的物体计数模型在处理具有复杂形状、内部对称性或相互重叠的物体时,往往表现不佳。它们无法有效地捕捉到人类在计数时所依赖的视觉重复模式和结构关系。因此,如何设计一个能够学习视觉重复和结构信息,从而实现更准确、更鲁棒的物体计数模型,是一个重要的研究问题。
核心思路:CountFormer的核心思路是利用Transformer架构强大的特征提取能力,特别是自监督预训练模型DINOv2所提供的丰富和空间一致的特征表示,来学习物体之间的视觉重复和结构关系。通过将DINOv2的特征与位置嵌入融合,模型能够更好地理解场景的几何结构,从而更准确地预测物体的数量。
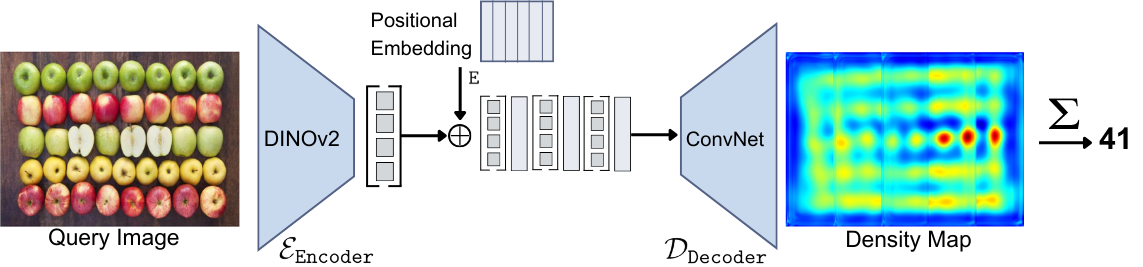
技术框架:CountFormer的整体架构基于CounTR模型,主要包含以下几个模块:1) DINOv2视觉编码器:用于提取输入图像的视觉特征。2) 位置嵌入融合:将位置信息融入到视觉特征中,以保留几何关系。3) 轻量级卷积解码器:将融合后的特征解码为密度图,密度图的每个像素值代表该位置的物体密度。整个流程是,输入图像首先通过DINOv2提取特征,然后与位置嵌入融合,最后通过卷积解码器生成密度图,并通过密度图积分得到最终的计数结果。
关键创新:CountFormer的关键创新在于将自监督预训练模型DINOv2引入到物体计数任务中。DINOv2能够提供更丰富、更具有空间一致性的特征表示,从而使模型能够更好地学习物体之间的视觉重复和结构关系。此外,位置嵌入融合也是一个重要的创新点,它能够有效地保留场景的几何信息,从而提高计数的准确性。与现有方法相比,CountFormer更侧重于学习视觉结构,而不是依赖于物体的类别信息。
关键设计:DINOv2采用ViT架构,并使用自监督学习方法进行预训练。位置嵌入采用可学习的位置编码。卷积解码器采用轻量级设计,以减少计算量。损失函数采用密度图预测常用的均方误差损失函数。具体的参数设置和网络结构细节可以参考原始论文和DINOv2的论文。
🖼️ 关键图片


📊 实验亮点
CountFormer在FSC-147数据集上取得了与当前最先进方法相当的性能。特别是在结构复杂或密集场景中,CountFormer表现出卓越的准确性,优于其他方法。这表明CountFormer能够有效地学习视觉重复和结构关系,从而提高计数的准确性。具体性能数据需要在论文中查找。
🎯 应用场景
CountFormer在许多领域具有广泛的应用前景,例如人群计数、细胞计数、车辆计数等。该模型可以应用于智能监控、医学图像分析、自动驾驶等领域,提高相关任务的自动化程度和准确性。此外,该研究对于开发更通用、更鲁棒的物体计数系统具有重要的理论价值和实际意义。
📄 摘要(原文)
Humans can effortlessly count diverse objects by perceiving visual repetition and structural relationships rather than relying on class identity. However, most existing counting models fail to replicate this ability; they often miscount when objects exhibit complex shapes, internal symmetry, or overlapping components. In this work, we introduce CountFormer, a transformer-based framework that learns to recognize repetition and structural coherence for class-agnostic object counting. Built upon the CounTR architecture, our model replaces its visual encoder with the self-supervised foundation model DINOv2, which produces richer and spatially consistent feature representations. We further incorporate positional embedding fusion to preserve geometric relationships before decoding these features into density maps through a lightweight convolutional decoder. Evaluated on the FSC-147 dataset, our model achieves performance comparable to current state-of-the-art methods while demonstrating superior accuracy on structurally intricate or densely packed scenes. Our findings indicate that integrating foundation models such as DINOv2 enables counting systems to approach human-like structural perception, advancing toward a truly general and exemplar-free counting paradigm.