Concerto: Joint 2D-3D Self-Supervised Learning Emerges Spatial Representations
作者: Yujia Zhang, Xiaoyang Wu, Yixing Lao, Chengyao Wang, Zhuotao Tian, Naiyan Wang, Hengshuang Zhao
分类: cs.CV
发布日期: 2025-10-27
备注: NeurIPS 2025, produced by Pointcept, project page: https://pointcept.github.io/Concerto
期刊: Neural Information Processing Systems 2025
💡 一句话要点
Concerto:融合2D-3D自监督学习,涌现空间表征
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 自监督学习 跨模态学习 3D场景理解 空间表征 点云处理
📋 核心要点
- 现有2D和3D自监督学习方法在空间表征学习方面存在局限性,未能充分利用跨模态信息。
- Concerto通过模拟人类多感官协同学习机制,结合3D自蒸馏和2D-3D跨模态联合嵌入,学习更连贯的空间特征。
- 实验表明,Concerto在3D场景理解任务中显著优于现有方法,并在多个基准测试中取得了SOTA结果。
📝 摘要(中文)
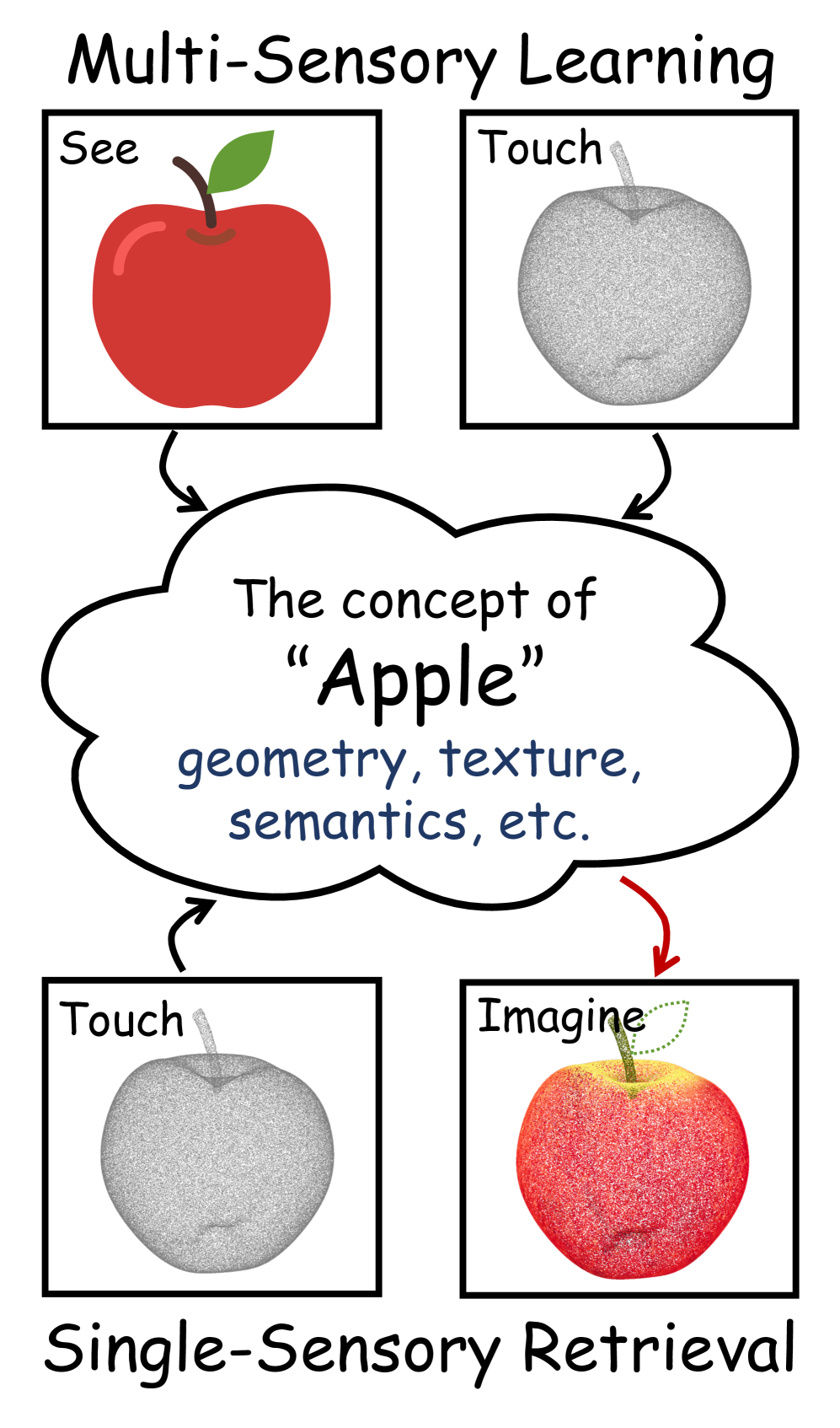
本文提出Concerto,一个模拟人类空间认知概念学习的极简框架,它结合了3D模内自蒸馏和2D-3D跨模态联合嵌入。Concerto学习到更连贯和信息丰富的空间特征,这可以通过零样本可视化来证明。在3D场景感知的线性探测任务中,Concerto优于独立的SOTA 2D和3D自监督模型,分别提升了14.2%和4.8%,也优于它们的特征拼接。通过完全微调,Concerto在多个场景理解基准测试中取得了新的SOTA结果(例如,在ScanNet上达到80.7%的mIoU)。此外,本文还提出了Concerto的一个变体,专门用于视频提升点云的空间理解,以及一个将Concerto表征线性投影到CLIP语言空间的转换器,从而实现开放世界感知。这些结果表明,Concerto涌现的空间表征具有卓越的细粒度几何和语义一致性。
🔬 方法详解
问题定义:现有方法在学习空间表征时,通常孤立地处理2D图像和3D点云数据,忽略了它们之间的互补信息。这导致学习到的表征缺乏几何和语义一致性,限制了模型在复杂场景理解任务中的性能。此外,如何有效地利用无标签数据进行自监督学习,也是一个重要的挑战。
核心思路:Concerto的核心思想是模拟人类通过多感官协同学习抽象概念的过程。通过将2D图像和3D点云数据进行联合嵌入,并利用3D模内自蒸馏,促使模型学习到更具几何和语义一致性的空间表征。这种跨模态学习方式能够弥补单一模态的不足,从而提升模型的泛化能力。
技术框架:Concerto框架包含两个主要组成部分:3D模内自蒸馏和2D-3D跨模态联合嵌入。首先,3D模内自蒸馏利用教师-学生网络结构,通过最小化教师网络和学生网络输出之间的差异,来提升3D表征的质量。然后,2D-3D跨模态联合嵌入将2D图像和3D点云数据映射到同一个特征空间,并通过对比学习的方式,促使模型学习到跨模态的对应关系。
关键创新:Concerto的关键创新在于其跨模态联合学习策略,它能够有效地融合2D图像和3D点云数据的信息,从而学习到更具几何和语义一致性的空间表征。此外,3D模内自蒸馏进一步提升了3D表征的质量,使得模型能够更好地理解场景的几何结构。
关键设计:在3D模内自蒸馏中,教师网络通常是学生网络的指数移动平均(EMA),以保证教师网络的稳定性。在2D-3D跨模态联合嵌入中,通常使用InfoNCE损失函数来最大化正样本对之间的相似度,并最小化负样本对之间的相似度。此外,网络结构的选择也会影响模型的性能,例如可以使用PointNet++作为3D编码器,ResNet作为2D编码器。
🖼️ 关键图片


📊 实验亮点
Concerto在ScanNet数据集上取得了80.7%的mIoU,刷新了SOTA记录。在3D场景感知的线性探测任务中,Concerto优于独立的SOTA 2D和3D自监督模型,分别提升了14.2%和4.8%。这些结果表明,Concerto能够有效地学习到更具几何和语义一致性的空间表征,并在多个场景理解任务中取得了显著的性能提升。
🎯 应用场景
Concerto在机器人导航、自动驾驶、增强现实等领域具有广泛的应用前景。通过学习更具几何和语义一致性的空间表征,Concerto可以帮助机器人更好地理解周围环境,从而实现更安全、更高效的导航和交互。此外,Concerto还可以应用于三维场景重建、物体识别等任务,为相关领域的研究提供新的思路。
📄 摘要(原文)
Humans learn abstract concepts through multisensory synergy, and once formed, such representations can often be recalled from a single modality. Inspired by this principle, we introduce Concerto, a minimalist simulation of human concept learning for spatial cognition, combining 3D intra-modal self-distillation with 2D-3D cross-modal joint embedding. Despite its simplicity, Concerto learns more coherent and informative spatial features, as demonstrated by zero-shot visualizations. It outperforms both standalone SOTA 2D and 3D self-supervised models by 14.2% and 4.8%, respectively, as well as their feature concatenation, in linear probing for 3D scene perception. With full fine-tuning, Concerto sets new SOTA results across multiple scene understanding benchmarks (e.g., 80.7% mIoU on ScanNet). We further present a variant of Concerto tailored for video-lifted point cloud spatial understanding, and a translator that linearly projects Concerto representations into CLIP's language space, enabling open-world perception. These results highlight that Concerto emerges spatial representations with superior fine-grained geometric and semantic consistency.