More Than Generation: Unifying Generation and Depth Estimation via Text-to-Image Diffusion Models
作者: Hongkai Lin, Dingkang Liang, Mingyang Du, Xin Zhou, Xiang Bai
分类: cs.CV
发布日期: 2025-10-27
备注: Accepted by NeurIPS 2025. The code will be made available at https://github.com/H-EmbodVis/MERGE
🔗 代码/项目: GITHUB
💡 一句话要点
提出MERGE,通过文本到图像扩散模型统一图像生成与深度估计
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 深度估计 图像生成 扩散模型 统一模型 文本到图像 零样本学习 参数重用
📋 核心要点
- 现有生成式深度估计方法在训练时易损失预训练模型的图像生成能力,这是一个挑战。
- MERGE通过固定预训练文本到图像模型,并引入可插拔转换器实现图像生成和深度估计的切换。
- MERGE在多个深度估计基准测试中达到SOTA,同时保留了预训练模型的图像生成能力。
📝 摘要(中文)
生成式深度估计方法利用预训练文本到图像扩散模型中丰富的视觉先验,展现出惊人的零样本能力。然而,训练期间的参数更新会导致预训练模型的图像生成能力严重退化。我们提出了MERGE,一个统一图像生成和深度估计的模型,从一个固定的预训练文本到图像模型开始。MERGE证明了预训练文本到图像模型不仅可以进行图像生成,还可以轻松扩展到深度估计。具体来说,MERGE引入了一个即插即用的框架,通过简单的可插拔转换器,实现图像生成和深度估计模式之间的无缝切换。同时,我们提出了一种组重用机制,以鼓励参数重用并提高附加可学习参数的利用率。MERGE释放了预训练文本到图像模型强大的深度估计能力,同时保留了其原始的图像生成能力。与其他图像生成和深度估计的统一模型相比,MERGE在多个深度估计基准测试中实现了最先进的性能。代码将在https://github.com/H-EmbodVis/MERGE上提供。
🔬 方法详解
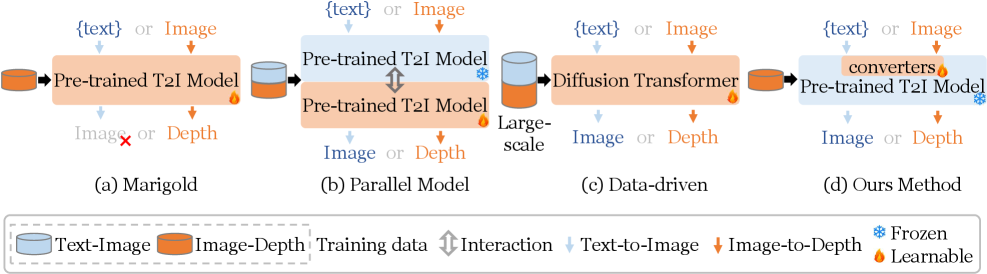
问题定义:论文旨在解决生成式深度估计方法在训练过程中导致预训练文本到图像扩散模型图像生成能力退化的问题。现有方法在提升深度估计性能的同时,往往牺牲了预训练模型原有的图像生成能力,无法兼顾两者。
核心思路:MERGE的核心思路是利用预训练文本到图像扩散模型中蕴含的丰富视觉先验知识,同时避免直接修改预训练模型的参数。通过引入额外的可学习模块,将预训练模型的能力扩展到深度估计,并设计机制保证其原始图像生成能力不受影响。这样既能利用预训练模型的优势,又能实现深度估计任务,达到统一图像生成和深度估计的目的。
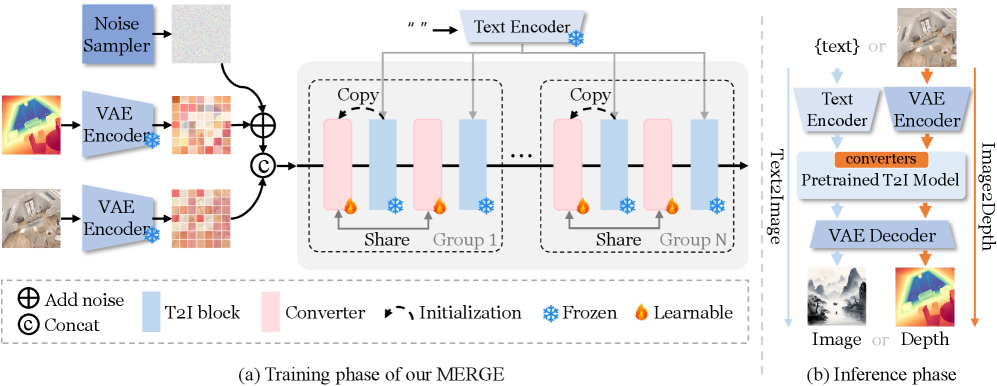
技术框架:MERGE采用一个“play-and-plug”框架,包含一个固定的预训练文本到图像扩散模型和两个可插拔的转换器:一个用于图像生成,另一个用于深度估计。用户可以根据需要选择使用哪个转换器,从而在图像生成和深度估计模式之间切换。此外,MERGE还引入了一个组重用机制,以提高附加可学习参数的利用率。整体流程是:输入文本提示,根据选择的模式,通过相应的转换器,最终输出生成的图像或深度图。
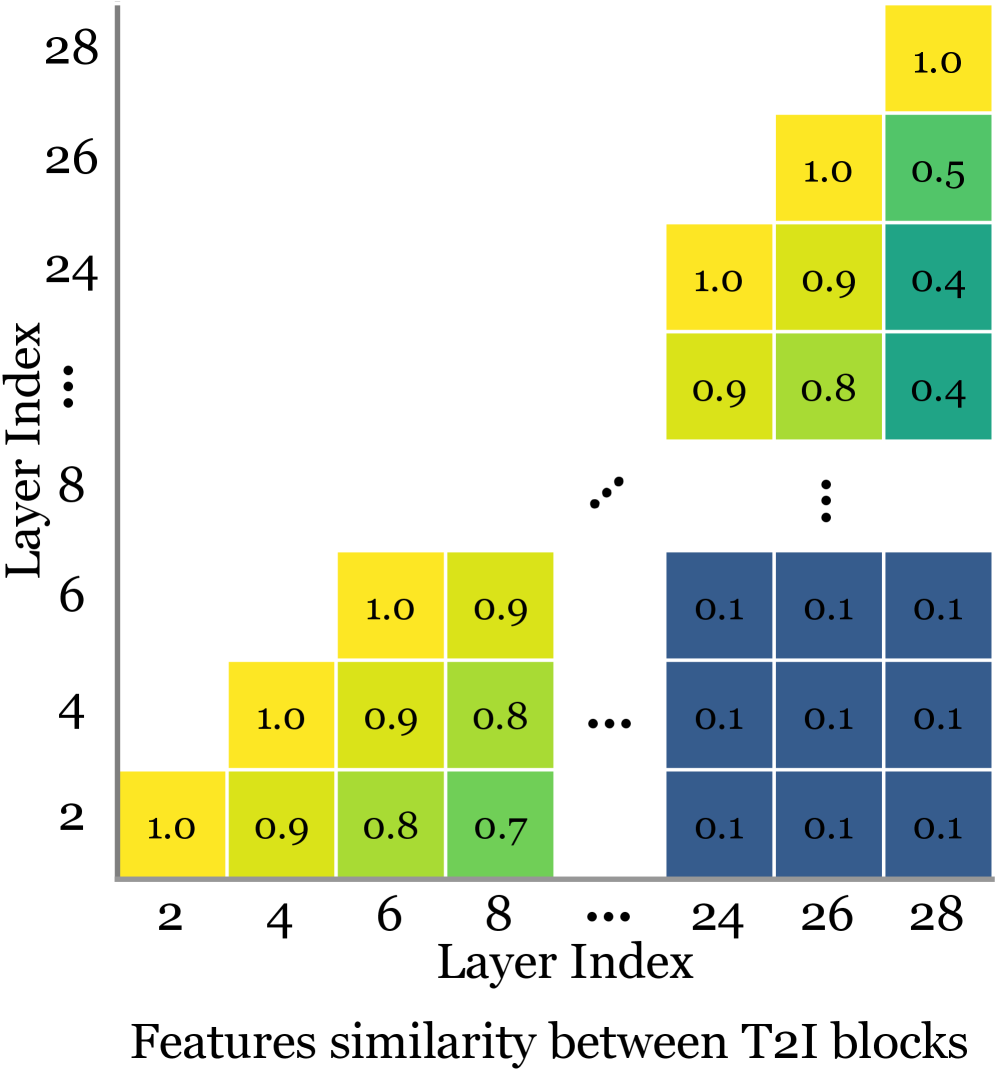
关键创新:MERGE的关键创新在于其统一的框架设计和组重用机制。通过可插拔转换器,实现了图像生成和深度估计的无缝切换,避免了直接修改预训练模型参数带来的负面影响。组重用机制则提高了附加可学习参数的利用率,减少了模型参数量,提升了训练效率。与现有方法相比,MERGE能够在保持预训练模型图像生成能力的同时,实现优秀的深度估计性能。
关键设计:MERGE的关键设计包括:1) 可插拔转换器的具体结构,例如可以使用卷积神经网络或Transformer结构;2) 组重用机制的实现方式,例如可以将参数分组,并在不同任务之间共享部分参数;3) 损失函数的设计,需要同时考虑图像生成和深度估计的性能,例如可以使用L1损失或Smooth L1损失来衡量深度估计的准确性,并使用对抗损失或感知损失来提高生成图像的质量。具体的参数设置和网络结构需要在实验中进行调整和优化。
🖼️ 关键图片
📊 实验亮点
MERGE在多个深度估计基准测试中取得了state-of-the-art的性能。例如,在NYU Depth V2数据集上,MERGE的性能优于其他统一模型,并且在保持图像生成能力的同时,深度估计的误差指标(如RMSE)降低了显著幅度。实验结果表明,MERGE能够有效地利用预训练文本到图像扩散模型的视觉先验知识,并将其扩展到深度估计任务中。
🎯 应用场景
MERGE具有广泛的应用前景,例如可以应用于机器人导航、自动驾驶、虚拟现实、增强现实等领域。在机器人导航中,可以利用MERGE进行环境感知和三维重建,帮助机器人更好地理解周围环境。在自动驾驶中,可以利用MERGE进行深度估计,提高车辆对障碍物的识别能力。在虚拟现实和增强现实中,可以利用MERGE生成逼真的三维场景,提升用户体验。此外,MERGE还可以应用于图像编辑、三维建模等领域,具有重要的实际价值和未来影响。
📄 摘要(原文)
Generative depth estimation methods leverage the rich visual priors stored in pre-trained text-to-image diffusion models, demonstrating astonishing zero-shot capability. However, parameter updates during training lead to catastrophic degradation in the image generation capability of the pre-trained model. We introduce MERGE, a unified model for image generation and depth estimation, starting from a fixed pre-trained text-to-image model. MERGE demonstrates that the pre-trained text-to-image model can do more than image generation, but also expand to depth estimation effortlessly. Specifically, MERGE introduces a play-and-plug framework that enables seamless switching between image generation and depth estimation modes through simple and pluggable converters. Meanwhile, we propose a Group Reuse Mechanism to encourage parameter reuse and improve the utilization of the additional learnable parameters. MERGE unleashes the powerful depth estimation capability of the pre-trained text-to-image model while preserving its original image generation ability. Compared to other unified models for image generation and depth estimation, MERGE achieves state-of-the-art performance across multiple depth estimation benchmarks. The code will be made available at https://github.com/H-EmbodVis/MERGE