EgoThinker: Unveiling Egocentric Reasoning with Spatio-Temporal CoT
作者: Baoqi Pei, Yifei Huang, Jilan Xu, Yuping He, Guo Chen, Fei Wu, Yu Qiao, Jiangmiao Pang
分类: cs.CV
发布日期: 2025-10-27
备注: Accepted at NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
EgoThinker:利用时空CoT增强MLLM的自我中心视角推理能力
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自我中心视频理解 多模态大语言模型 思维链 时空推理 具身智能
📋 核心要点
- 现有多模态大语言模型在可见事件推理方面表现出色,但在具身、第一人称视角理解方面存在不足,限制了其在自我中心视频推理中的应用。
- EgoThinker框架通过引入时空思维链监督和两阶段学习课程,使MLLM具备更强的自我中心推理能力,从而弥补了现有方法的不足。
- 实验结果表明,EgoThinker在多个自我中心基准测试中超越了现有方法,并在细粒度时空定位任务中取得了显著的性能提升。
📝 摘要(中文)
本文提出EgoThinker框架,旨在提升多模态大语言模型(MLLM)在自我中心视频推理方面的能力。自我中心视频推理的核心挑战在于推断相机背后不可见代理的意图,并识别细粒度的交互。为了解决这一问题,EgoThinker通过时空思维链(CoT)监督和两阶段学习课程,赋予MLLM强大的自我中心推理能力。首先,构建了大规模自我中心问答数据集EgoRe-5M,该数据集包含来自1300万个多样化自我中心视频片段,并标注了详细的CoT推理过程和密集的手-物体定位信息。其次,在EgoRe-5M上采用监督微调(SFT)来灌输推理技能,然后进行强化微调(RFT)以进一步增强时空定位能力。实验结果表明,EgoThinker在多个自我中心基准测试中优于现有方法,并在细粒度的时空定位任务中取得了显著改进。
🔬 方法详解
问题定义:自我中心视频推理需要理解隐藏的意图和细粒度的交互,这对于现有的多模态大语言模型(MLLM)来说是一个挑战。现有的MLLM擅长处理可见事件,但缺乏具身和第一人称视角的理解能力,因此无法很好地处理自我中心视频推理任务。
核心思路:EgoThinker的核心思路是通过引入时空思维链(CoT)监督,引导MLLM学习如何像人类一样进行推理,从而提升其在自我中心视频推理方面的能力。通过显式地提供推理步骤,模型可以更好地理解视频中的事件和交互,并做出更准确的预测。
技术框架:EgoThinker框架包含两个主要阶段:监督微调(SFT)和强化微调(RFT)。在SFT阶段,模型在大规模自我中心问答数据集EgoRe-5M上进行训练,学习如何生成CoT推理过程。在RFT阶段,模型通过强化学习进一步优化其时空定位能力。EgoRe-5M数据集包含多分钟的视频片段,并标注了详细的CoT推理过程和密集的手-物体定位信息。
关键创新:EgoThinker的关键创新在于引入了时空CoT监督,这使得模型能够学习如何进行显式的推理,从而更好地理解自我中心视频中的事件和交互。此外,EgoRe-5M数据集的大规模和多样性也为模型的训练提供了充足的数据支持。与现有方法相比,EgoThinker能够更好地处理细粒度的时空定位任务。
关键设计:EgoRe-5M数据集包含1300万个视频片段,并标注了详细的CoT推理过程和密集的手-物体定位信息。在SFT阶段,使用交叉熵损失函数来训练模型生成CoT推理过程。在RFT阶段,使用奖励函数来鼓励模型进行准确的时空定位。具体的网络结构细节和超参数设置在论文中有详细描述。
🖼️ 关键图片


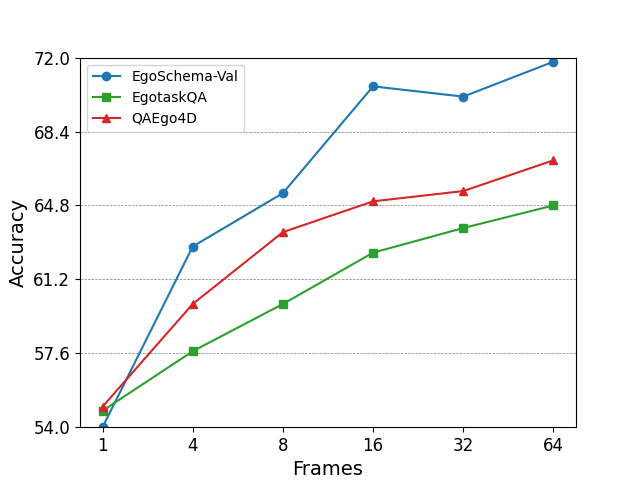
📊 实验亮点
EgoThinker在多个自我中心基准测试中取得了显著的性能提升。例如,在细粒度的时空定位任务中,EgoThinker的性能优于现有方法。具体的数据指标和对比结果可以在论文的实验部分找到。EgoThinker的成功表明,时空CoT监督是一种有效的提升MLLM在自我中心视频推理能力的方法。
🎯 应用场景
EgoThinker具有广泛的应用前景,例如在机器人辅助、虚拟现实、人机交互等领域。它可以帮助机器人更好地理解人类的意图,从而进行更有效的协作。在虚拟现实中,EgoThinker可以提供更真实的沉浸式体验。此外,EgoThinker还可以用于开发更智能的监控系统和安全系统,从而提高安全性和效率。
📄 摘要(原文)
Egocentric video reasoning centers on an unobservable agent behind the camera who dynamically shapes the environment, requiring inference of hidden intentions and recognition of fine-grained interactions. This core challenge limits current multimodal large language models MLLMs, which excel at visible event reasoning but lack embodied, first-person understanding. To bridge this gap, we introduce EgoThinker, a novel framework that endows MLLMs with robust egocentric reasoning capabilities through spatio-temporal chain-of-thought supervision and a two-stage learning curriculum. First, we introduce EgoRe-5M, a large-scale egocentric QA dataset constructed from 13M diverse egocentric video clips. This dataset features multi-minute segments annotated with detailed CoT rationales and dense hand-object grounding. Second, we employ SFT on EgoRe-5M to instill reasoning skills, followed by reinforcement fine-tuning RFT to further enhance spatio-temporal localization. Experimental results show that EgoThinker outperforms existing methods across multiple egocentric benchmarks, while achieving substantial improvements in fine-grained spatio-temporal localization tasks. Full code and data are released at https://github.com/InternRobotics/EgoThinker.