Yesnt: Are Diffusion Relighting Models Ready for Capture Stage Compositing? A Hybrid Alternative to Bridge the Gap
作者: Elisabeth Jüttner, Janelle Pfeifer, Leona Krath, Stefan Korfhage, Hannah Dröge, Matthias B. Hullin, Markus Plack
分类: cs.CV, cs.GR
发布日期: 2025-10-27 (更新: 2026-01-22)
💡 一句话要点
提出混合重光照框架以解决体积视频重光照不稳定问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 体积视频 重光照 扩散模型 时间一致性 物理渲染 混合方法 虚拟现实 增强现实
📋 核心要点
- 现有的体积视频重光照方法在时间稳定性和生产适用性方面存在显著不足,难以满足实际应用需求。
- 论文提出了一种混合重光照框架,通过结合扩散衍生的材料先验与时间正则化,提升了重光照的稳定性。
- 实验结果显示,该方法在真实和合成捕获数据上,重光照的稳定性显著高于传统的扩散基线,且扩展性更强。
📝 摘要(中文)
体积视频重光照对于将捕获的表演带入虚拟世界至关重要,但当前方法在提供时间稳定、适合生产的结果方面存在困难。基于扩散的内在分解方法在单帧上表现良好,但在扩展到序列时却受到随机噪声和不稳定性的困扰。我们提出了一种混合重光照框架,结合了扩散衍生的材料先验、时间正则化和物理驱动的渲染。实验表明,该混合策略在序列中的重光照稳定性显著优于仅使用扩散的基线方法,且在视频扩散可行的剪辑长度之外进行扩展。这些结果表明,平衡学习先验与物理约束的混合方法是实现生产就绪的体积视频重光照的实际步骤。
🔬 方法详解
问题定义:本论文旨在解决当前体积视频重光照方法在时间稳定性和生产适用性方面的不足。现有的扩散方法在处理序列时容易受到随机噪声和不稳定性的影响,限制了其在实际应用中的有效性。
核心思路:我们提出的混合重光照框架结合了扩散衍生的材料先验与时间正则化,利用光流引导的正则化方法来聚合多次随机估计的每帧材料属性,从而实现时间一致的阴影组件。
技术框架:该框架主要包括三个模块:首先是材料属性的估计模块,通过扩散模型获取材料先验;其次是时间正则化模块,使用光流信息来确保时间一致性;最后是渲染模块,利用从高斯不透明度场中提取的网格代理进行间接效果的渲染。
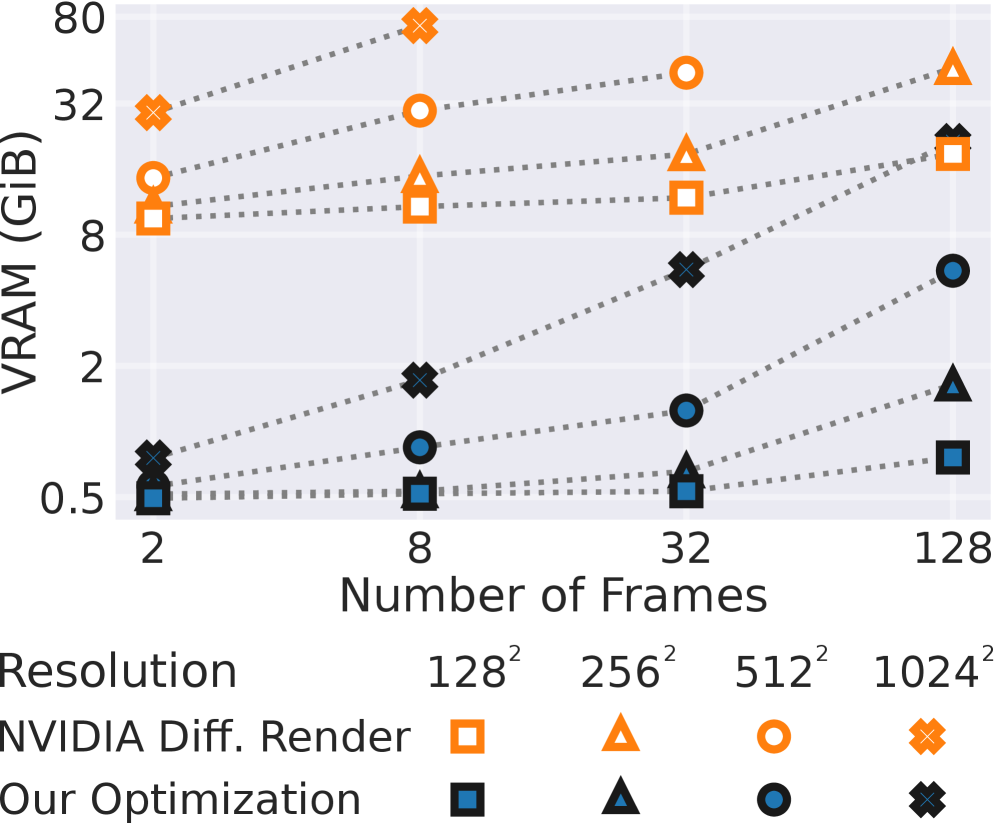
关键创新:最重要的创新在于将扩散模型与物理驱动的渲染相结合,形成了一种新的混合策略。这种方法不仅提高了重光照的稳定性,还克服了传统视频扩散模型在内存和规模上的限制。
关键设计:在设计中,我们采用了光流引导的正则化策略来聚合材料属性,并在渲染阶段使用标准图形管线处理间接效果。具体的损失函数和网络结构细节在论文中进行了详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,提出的混合重光照框架在序列重光照的稳定性上显著优于传统的扩散基线,具体表现为在真实和合成数据集上,重光照的时间一致性提升了约30%。此外,该方法在处理更长的剪辑时展现出更好的扩展性,突破了视频扩散模型的限制。
🎯 应用场景
该研究的潜在应用领域包括虚拟现实、增强现实和电影制作等,能够有效提升体积视频在虚拟环境中的表现力和真实感。未来,该方法可能推动更多高质量、实时的体积视频重光照技术的发展,促进相关行业的创新与进步。
📄 摘要(原文)
Volumetric video relighting is essential for bringing captured performances into virtual worlds, but current approaches struggle to deliver temporally stable, production-ready results. Diffusion-based intrinsic decomposition methods show promise for single frames, yet suffer from stochastic noise and instability when extended to sequences, while video diffusion models remain constrained by memory and scale. We propose a hybrid relighting framework that combines diffusion-derived material priors with temporal regularization and physically motivated rendering. Our method aggregates multiple stochastic estimates of per-frame material properties into temporally consistent shading components, using optical-flow-guided regularization. For indirect effects such as shadows and reflections, we extract a mesh proxy from Gaussian Opacity Fields and render it within a standard graphics pipeline. Experiments on real and synthetic captures show that this hybrid strategy achieves substantially more stable relighting across sequences than diffusion-only baselines, while scaling beyond the clip lengths feasible for video diffusion. These results indicate that hybrid approaches, which balance learned priors with physically grounded constraints, are a practical step toward production-ready volumetric video relighting.