On the Faithfulness of Visual Thinking: Measurement and Enhancement
作者: Zujing Liu, Junwen Pan, Qi She, Yuan Gao, Guisong Xia
分类: cs.CV, cs.AI
发布日期: 2025-10-27
🔗 代码/项目: GITHUB
💡 一句话要点
提出SCCM学习策略,提升视觉语言模型多模态推理中视觉信息的可靠性和充分性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 多模态推理 思维链 视觉真实性 强化学习 因果推断 充分成分因果模型 无监督学习
📋 核心要点
- 现有视觉语言模型在多模态推理中,虽然能生成思维链,但视觉信息的准确性不足,导致推理过程缺乏真实性。
- 论文提出一种名为SCCM的学习策略,旨在鼓励模型生成充分且最小的视觉组件,从而独立地引导模型得出正确答案。
- 实验结果表明,SCCM能够显著提升视觉语言模型在细粒度感知和推理任务中的视觉真实性,且无需额外标注。
📝 摘要(中文)
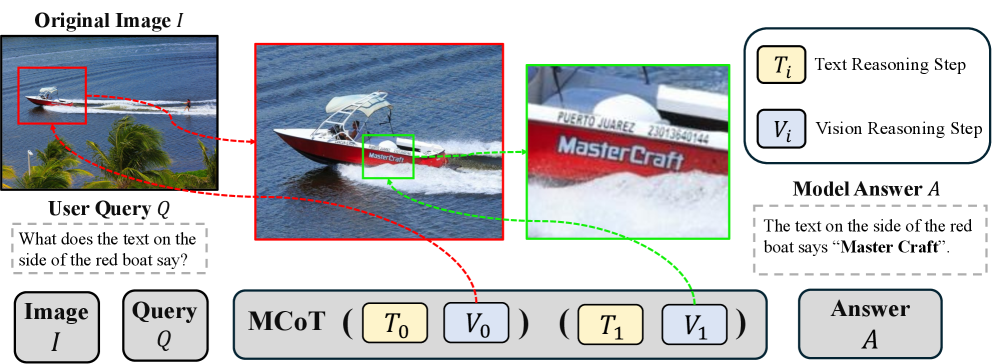
近年来,大型视觉语言模型(LVLMs)经过强化微调(RFT)后,能够生成视觉-文本多模态思维链(MCoT)。然而,我们观察到MCoT中包含的视觉信息通常不准确,即使如此模型仍能给出正确答案,这表明MCoT推理过程缺乏真实性。我们将这种不真实性归因于RFT中的强化学习奖励,它仅激励交错的视觉-文本提示格式,即鼓励模型将视觉信息融入文本推理步骤,而不考虑视觉信息的正确性。本文首先通过干预视觉和文本思维来衡量MCoT的真实性,从而探究MCoT的真实性。令人惊讶的是,模型的预测在视觉干预下几乎保持不变,但在文本干预下变化显著,表明视觉证据在很大程度上被忽略。为了进一步分析视觉信息,我们引入了一种基于LVLM的自动评估指标,从可靠性和充分性两个角度量化视觉提示的真实性。我们的评估表明,当前MCoT轨迹中的视觉信息既不可靠也不充分。为了解决这个问题,我们提出了一种新的MCoT学习策略,称为充分成分因果模型(SCCM)学习。这种方法鼓励MCoT生成充分但最小的视觉组件,这些组件能够独立地得出正确的答案。我们注意到,所提出的SCCM是无标注的,并且可以即插即用地与各种用于MCoT的RFT兼容。经验结果表明,SCCM始终如一地提高了各种细粒度感知和推理基准测试中的视觉真实性。
🔬 方法详解
问题定义:现有视觉语言模型(LVLMs)在生成多模态思维链(MCoT)时,虽然能够整合视觉信息,但这些视觉信息往往不准确,甚至与最终答案无关。强化学习微调(RFT)只关注视觉-文本交错的格式,而忽略了视觉信息的正确性,导致模型过度依赖文本信息,忽视了视觉信息的真实作用。因此,需要解决的问题是如何提高MCoT中视觉信息的可靠性和充分性,使其真正参与到推理过程中。
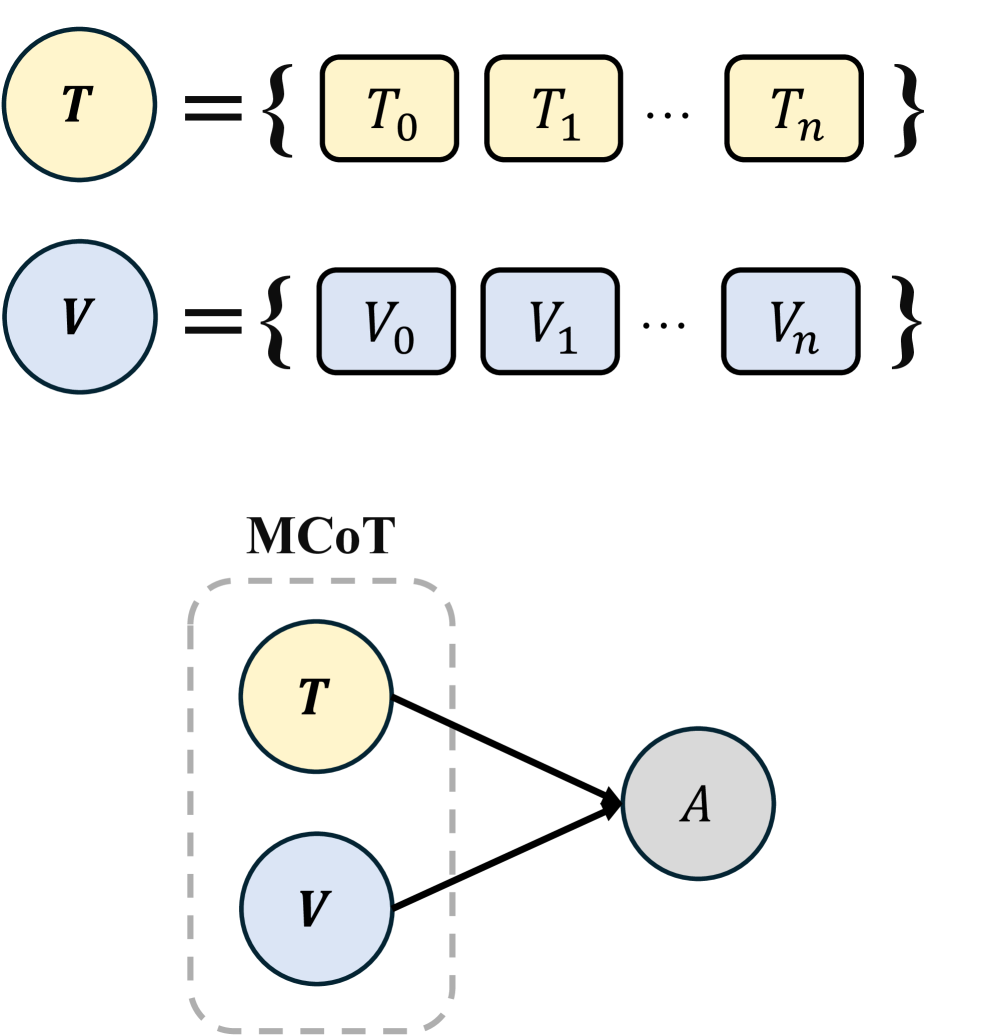
核心思路:论文的核心思路是让模型学习生成“充分成分”的视觉信息,即那些能够独立支撑模型得出正确答案的最小视觉信息集合。通过鼓励模型关注关键的视觉证据,减少对无关视觉信息的依赖,从而提高视觉推理的真实性。这种方法基于因果推断的思想,试图让模型学习视觉信息与最终答案之间的因果关系。
技术框架:SCCM学习策略可以作为一个插件模块,与现有的RFT方法结合使用。其主要流程包括:1) 使用LVLM生成MCoT;2) 利用提出的自动评估指标评估视觉信息的可靠性和充分性;3) 使用SCCM学习策略优化MCoT的生成过程,鼓励模型生成更充分且更可靠的视觉信息。整个框架无需额外的人工标注,可以端到端地进行训练。
关键创新:论文的关键创新在于提出了SCCM学习策略,这是一种无监督的方法,能够有效地提高LVLM在多模态推理中对视觉信息的利用率和真实性。与传统的RFT方法不同,SCCM不仅关注视觉-文本的格式,更关注视觉信息的质量和作用。此外,论文还提出了一个自动评估指标,用于量化MCoT中视觉信息的可靠性和充分性。
关键设计:SCCM学习策略的关键设计在于如何定义和鼓励“充分成分”。具体来说,论文可能设计了一种损失函数,用于惩罚那些包含冗余或不相关视觉信息的MCoT。此外,可能还采用了一些技术手段,例如注意力机制或信息瓶颈,来引导模型关注关键的视觉区域。具体的参数设置和网络结构细节需要在论文中进一步查找。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SCCM学习策略在多个细粒度感知和推理基准测试中,显著提高了视觉语言模型的视觉真实性。具体性能提升数据未知,但论文强调SCCM在各种基准测试中均表现出一致的改进效果,证明了其有效性和泛化能力。SCCM作为一种即插即用的模块,可以方便地集成到现有的RFT框架中。
🎯 应用场景
该研究成果可应用于各种需要视觉理解和推理的场景,例如智能问答、图像标注、机器人导航、自动驾驶等。通过提高视觉信息的可靠性,可以提升系统的决策能力和鲁棒性,使其在复杂环境中更好地工作。未来,该方法有望扩展到更广泛的多模态任务中,例如视频理解和具身智能。
📄 摘要(原文)
Recent large vision-language models (LVLMs) can generate vision-text multimodal chain-of-thought (MCoT) traces after reinforcement fine-tuning (RFT). However, we observe that the visual information incorporated in MCoT is often inaccurate, though still yield correct answers, indicating a lack of faithfulness in the MCoT reasoning process. We attribute this unfaithfulness to the RL reward in RFT, which solely incentivizes the format of interleaved vision-text cues, ie, it encourages the model to incorporate visual information into its text reasoning steps without considering the correctness of the visual information. In this paper, we first probe the faithfulness of MCoT by measuring how much the prediction changes when its visual and textual thoughts are intervened. Surprisingly, the model's predictions remain nearly unchanged under visual intervention but change significantly under textual intervention, indicating that the visual evidence is largely ignored. To further analyze visual information, we introduce an automated LVLM-based evaluation metric that quantifies the faithfulness of visual cues from two perspectives: reliability and sufficiency. Our evaluation reveals that the visual information in current MCoT traces is simultaneously unreliable and insufficient. To address this issue, we propose a novel MCoT learning strategy termed Sufficient-Component Cause Model (SCCM) learning. This approach encourages the MCoT to generate sufficient yet minimal visual components that are independently capable of leading to correct answers. We note that the proposed SCCM is annotation-free and compatible with various RFT for MCoT in a plug-and-play manner. Empirical results demonstrate that SCCM consistently improves the visual faithfulness across a suite of fine-grained perception and reasoning benchmarks. Code is available at https://github.com/EugeneLiu01/Faithful_Thinking_with_Image.