MergeMix: A Unified Augmentation Paradigm for Visual and Multi-Modal Understanding
作者: Xin Jin, Siyuan Li, Siyong Jian, Kai Yu, Huan Wang
分类: cs.CV
发布日期: 2025-10-27 (更新: 2025-12-29)
备注: Code Link: https://github.com/JinXins/MergeMix
💡 一句话要点
提出MergeMix统一增强范式,提升视觉和多模态理解能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉语言对齐 数据增强 Mixup Token Merge 偏好学习 大型语言模型
📋 核心要点
- 现有MLLM对齐方法SFT依赖人工标注,泛化性不足;RL计算开销大,训练不稳定。
- 提出MergeMix,通过Token Merge的Mixup增强桥接SFT和RL,实现高效稳定的对齐。
- 实验表明,MergeMix在分类精度、泛化能力和MLLM对齐方面均有显著提升。
📝 摘要(中文)
多模态大型语言模型(MLLM)中的视觉-语言对齐依赖于监督微调(SFT)或强化学习(RL)。在后训练阶段对齐MLLM时,SFT是一个稳定的选择,但需要人工标注且缺乏任务泛化能力;而RL从奖励信号中搜索更好的答案,但计算开销大且不稳定。为了在可扩展性、效率和对齐泛化之间取得平衡,我们提出了MergeMix,一种统一的范式,它通过高效的基于Token Merge的Mixup增强来桥接SFT和RL。对于Mixup策略,我们根据具有聚类区域的合并注意力图生成上下文对齐的混合图像以及相应的标签。然后,我们通过构建原始图像和MergeMix生成的图像的偏好对,并使用混合SimPO损失优化软偏好边距,来增强MLLM的偏好驱动范式。大量实验表明,MergeMix不仅作为一种增强方法实现了卓越的分类精度,而且提高了MLLM的泛化能力和对齐能力,为具有训练效率和稳定性的偏好对齐提供了一种新的学习范式。
🔬 方法详解
问题定义:现有的多模态大语言模型(MLLMs)的视觉-语言对齐方法,如监督微调(SFT)和强化学习(RL),存在各自的局限性。SFT需要大量人工标注数据,成本高昂且泛化能力有限。RL虽然可以从奖励信号中学习,但计算复杂度高,训练过程不稳定,难以收敛。因此,如何高效、稳定地提升MLLMs的视觉-语言对齐能力和泛化能力是一个关键问题。
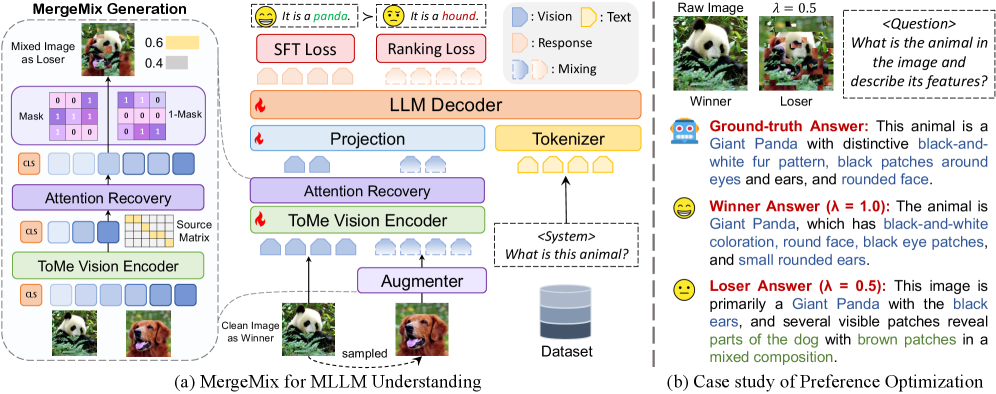
核心思路:MergeMix的核心思路是利用一种统一的增强范式,将SFT和RL的优势结合起来。它通过Token Merge技术生成混合图像,并利用这些混合图像构建偏好对,从而引导模型学习更好的视觉-语言对齐。这种方法旨在在可扩展性、效率和泛化能力之间取得平衡。
技术框架:MergeMix的整体框架包含以下几个主要步骤:1) Token Merge: 使用Token Merge算法对图像的token进行合并,生成具有聚类区域的注意力图。2) Mixup增强: 基于合并的注意力图,将两张图像进行混合,生成上下文对齐的混合图像,并生成相应的混合标签。3) 偏好对构建: 构建原始图像和MergeMix生成的图像的偏好对。4) 偏好学习: 使用混合SimPO损失优化软偏好边距,从而增强MLLM的偏好驱动范式。
关键创新:MergeMix的关键创新在于其统一的增强范式,它将Token Merge和Mixup增强结合起来,生成具有上下文对齐的混合图像。这种方法不仅可以提高模型的分类精度,还可以增强模型的泛化能力和对齐能力。与传统的Mixup方法相比,MergeMix能够更好地保留图像的语义信息,从而生成更有效的混合图像。
关键设计:MergeMix的关键设计包括:1) Token Merge策略: 使用自适应的Token Merge算法,根据图像的内容动态地合并token。2) Mixup比例: 根据合并的注意力图,自适应地调整混合比例,以生成具有上下文对齐的混合图像。3) 混合SimPO损失: 使用混合SimPO损失来优化软偏好边距,从而引导模型学习更好的视觉-语言对齐。具体来说,SimPO损失函数用于鼓励模型对原始图像给出更高的偏好,同时对MergeMix生成的图像给出适当的偏好。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MergeMix在图像分类任务上取得了显著的性能提升,超越了传统的Mixup方法。同时,MergeMix还能够提高MLLM的泛化能力和对齐能力,使其在视觉问答等任务上表现更佳。例如,在某些数据集上,MergeMix可以将模型的准确率提高几个百分点。
🎯 应用场景
MergeMix可应用于各种多模态理解任务,例如图像描述、视觉问答、图像分类等。该方法能够提升模型的泛化能力和对齐能力,使其在实际应用中表现更佳。此外,MergeMix的训练效率高,可以降低训练成本,加速模型部署。未来,MergeMix有望成为多模态学习领域的一种重要技术。
📄 摘要(原文)
Vision-language alignment in multi-modal large language models (MLLMs) relies on supervised fine-tuning (SFT) or reinforcement learning (RL). To align multi-modal large language models (MLLMs) in the post-training stage, supervised fine-tuning (SFT) is a stable choice but requires human annotations and lacks task generalizations, while Reinforcement Learning (RL) searches for better answers from reward signals but suffers from computational overhead and instability. To achieve balance among scalability, efficiency, and alignment generalizations, we propose MergeMix, a unified paradigm that bridges SFT and RL with an efficient Token Merge based Mixup augmentation. As for the Mixup policy, we generate contextual aligned mixed images with the corresponding labels according to the merged attention maps with cluster regions. Then, we enhance the preference-driven paradigm for MLLMs by building preference pairs with raw images and MergeMix-generated ones and optimizing the soft preference margin with the mixed SimPO loss. Extensive experiments demonstrate that MergeMix not only achieves dominant classification accuracy as an augmentation method but also improves generalization abilities and alignment of MLLMs, providing a new learning paradigm for preference alignment with training efficiency and stability.