UrbanIng-V2X: A Large-Scale Multi-Vehicle, Multi-Infrastructure Dataset Across Multiple Intersections for Cooperative Perception
作者: Karthikeyan Chandra Sekaran, Markus Geisler, Dominik Rößle, Adithya Mohan, Daniel Cremers, Wolfgang Utschick, Michael Botsch, Werner Huber, Torsten Schön
分类: cs.CV
发布日期: 2025-10-27 (更新: 2026-02-02)
备注: Accepted to NeurIPS 2025. Including supplemental material. For code and dataset, see https://github.com/thi-ad/UrbanIng-V2X
💡 一句话要点
UrbanIng-V2X:用于协同感知的多路口大规模多车辆多基础设施数据集
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 协同感知 自动驾驶 智能交通 多模态数据 数据集 V2X 城市环境
📋 核心要点
- 现有协同感知数据集规模有限,缺乏多路口、多车辆和多基础设施的综合数据,限制了算法的泛化能力。
- UrbanIng-V2X数据集旨在提供大规模、多模态的协同感知数据,包含车辆和基础设施传感器在多个城市路口的同步记录。
- 该数据集包含丰富的传感器数据和3D标注,并提供了基准测试和数字孪生环境,促进协同感知算法的开发和评估。
📝 摘要(中文)
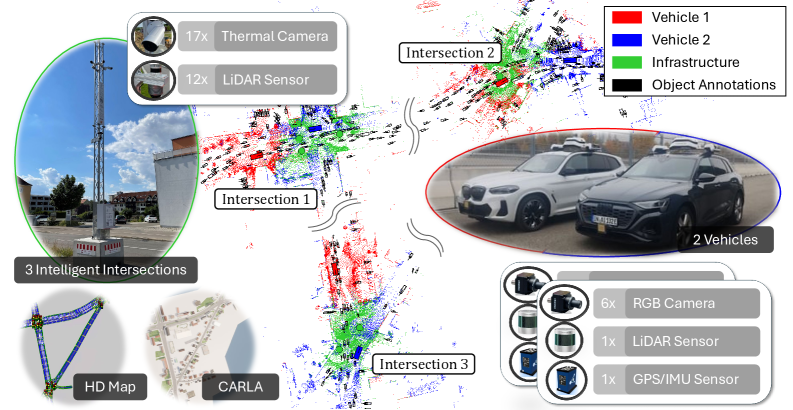
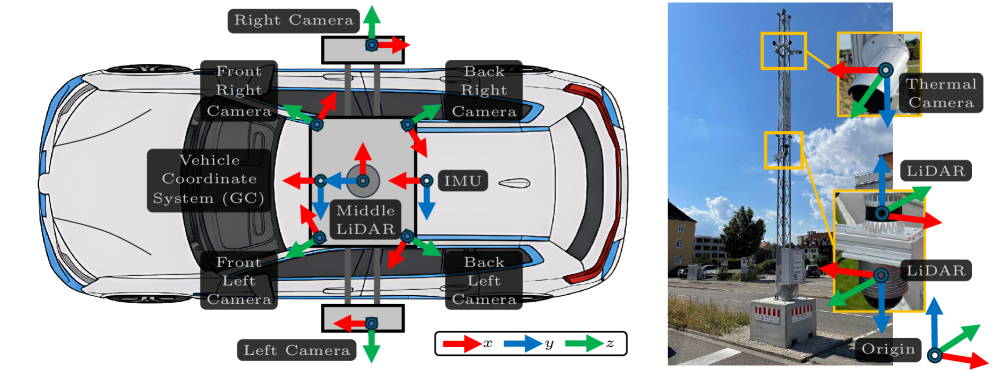
现有的协同感知数据集在推动智能交通应用方面发挥了关键作用,通过智能体之间的信息交换,克服遮挡等挑战,并提高整体场景理解能力。然而,一些现有的真实世界数据集虽然包含了车-车和车-路交互,但通常仅限于单个路口或单辆车。目前缺乏一个包含多个互联车辆和基础设施传感器,并覆盖多个路口的综合感知数据集,这限制了算法在不同交通环境中的基准测试。因此,可能发生过拟合,并且由于相似的路口布局和交通参与者行为,模型可能表现出误导性的高性能。为了解决这个问题,我们推出了UrbanIng-V2X,这是第一个大规模多模态数据集,支持在德国因戈尔施塔特三个城市路口部署的车辆和基础设施传感器之间的协同感知。UrbanIng-V2X包含34个时间对齐和空间校准的传感器序列,每个序列持续20秒。所有序列都包含来自三个路口之一的记录,涉及两辆车和最多三个基础设施传感器杆在协调场景中运行。总的来说,UrbanIng-V2X提供了来自12个车载RGB相机、2个车载激光雷达、17个基础设施热像仪和12个基础设施激光雷达的数据。所有序列都以10 Hz的频率进行标注,带有跨越13个对象类别的3D边界框,从而在整个数据集中产生大约71.2万个标注实例。我们使用最先进的协同感知方法提供了全面的评估,并公开发布了代码库、数据集、高清地图和完整数据收集环境的数字孪生。
🔬 方法详解
问题定义:现有协同感知数据集通常规模较小,场景单一,难以覆盖复杂的城市交通环境。这导致算法在特定场景下表现良好,但在其他场景下泛化能力不足。缺乏多路口、多车辆和多基础设施的综合数据集是当前协同感知研究的瓶颈。
核心思路:UrbanIng-V2X数据集的核心思路是提供一个大规模、多模态、多路口的协同感知数据集,以促进算法在更真实、更复杂的城市交通环境中的研究和评估。通过整合车辆和基础设施的传感器数据,可以实现更全面的场景理解和更鲁棒的感知性能。
技术框架:UrbanIng-V2X数据集的构建涉及以下几个关键步骤: 1. 数据采集:在德国因戈尔施塔特三个城市路口部署车辆和基础设施传感器,采集多模态数据。 2. 数据同步与校准:对采集到的数据进行时间对齐和空间校准,确保数据的一致性。 3. 数据标注:使用3D边界框对数据进行标注,涵盖13个对象类别。 4. 数据集发布:公开发布数据集、代码库、高清地图和数字孪生环境。
关键创新:UrbanIng-V2X数据集的关键创新在于其大规模、多模态和多路口的特性。它是第一个包含多个互联车辆和基础设施传感器,并覆盖多个路口的协同感知数据集。此外,该数据集还提供了高清地图和数字孪生环境,方便研究人员进行算法开发和评估。
关键设计:UrbanIng-V2X数据集的关键设计包括: * 传感器配置:车辆配备RGB相机和激光雷达,基础设施配备热像仪和激光雷达,提供多模态数据。 * 数据采集场景:选择三个具有代表性的城市路口,覆盖不同的交通状况。 * 标注频率:以10 Hz的频率进行标注,确保标注的准确性和完整性。 * 对象类别:标注13个对象类别,涵盖常见的交通参与者。
🖼️ 关键图片

📊 实验亮点
论文使用最先进的协同感知方法对UrbanIng-V2X数据集进行了全面的评估。实验结果表明,该数据集能够有效评估算法在不同交通环境中的性能,并为算法的改进提供指导。数据集包含约71.2万个标注实例,为算法训练提供了充足的数据。
🎯 应用场景
UrbanIng-V2X数据集可广泛应用于自动驾驶、智能交通系统、机器人导航等领域。该数据集能够促进协同感知算法的开发和评估,提高自动驾驶车辆在复杂城市环境中的感知能力,并为智能交通系统的优化提供数据支持。未来,该数据集有望推动城市交通的智能化和安全性。
📄 摘要(原文)
Recent cooperative perception datasets have played a crucial role in advancing smart mobility applications by enabling information exchange between intelligent agents, helping to overcome challenges such as occlusions and improving overall scene understanding. While some existing real-world datasets incorporate both vehicle-to-vehicle and vehicle-to-infrastructure interactions, they are typically limited to a single intersection or a single vehicle. A comprehensive perception dataset featuring multiple connected vehicles and infrastructure sensors across several intersections remains unavailable, limiting the benchmarking of algorithms in diverse traffic environments. Consequently, overfitting can occur, and models may demonstrate misleadingly high performance due to similar intersection layouts and traffic participant behavior. To address this gap, we introduce UrbanIng-V2X, the first large-scale, multi-modal dataset supporting cooperative perception involving vehicles and infrastructure sensors deployed across three urban intersections in Ingolstadt, Germany. UrbanIng-V2X consists of 34 temporally aligned and spatially calibrated sensor sequences, each lasting 20 seconds. All sequences contain recordings from one of three intersections, involving two vehicles and up to three infrastructure-mounted sensor poles operating in coordinated scenarios. In total, UrbanIng-V2X provides data from 12 vehicle-mounted RGB cameras, 2 vehicle LiDARs, 17 infrastructure thermal cameras, and 12 infrastructure LiDARs. All sequences are annotated at a frequency of 10 Hz with 3D bounding boxes spanning 13 object classes, resulting in approximately 712k annotated instances across the dataset. We provide comprehensive evaluations using state-of-the-art cooperative perception methods and publicly release the codebase, dataset, HD map, and a digital twin of the complete data collection environment.