Video-Thinker: Sparking "Thinking with Videos" via Reinforcement Learning
作者: Shijian Wang, Jiarui Jin, Xingjian Wang, Linxin Song, Runhao Fu, Hecheng Wang, Zongyuan Ge, Yuan Lu, Xuelian Cheng
分类: cs.CV
发布日期: 2025-10-27
💡 一句话要点
提出Video-Thinker,通过强化学习赋能MLLM进行视频推理
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频推理 多模态大语言模型 强化学习 思维链 自主推理
📋 核心要点
- 现有方法缺乏动态推理能力,无法有效利用视频信息进行复杂推理。
- Video-Thinker通过强化学习,使MLLM自主利用自身能力生成推理线索,实现视频推理。
- 实验表明,Video-Thinker在多个视频推理基准上显著优于现有方法,达到SOTA水平。
📝 摘要(中文)
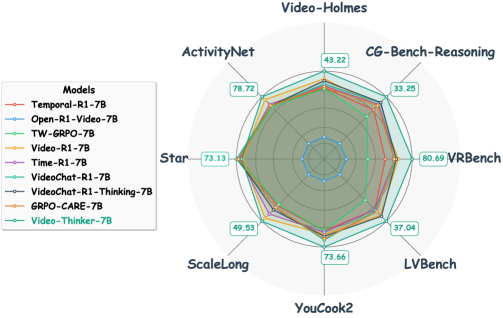
本文提出Video-Thinker,旨在使多模态大语言模型(MLLMs)能够像处理图像一样进行视频推理。Video-Thinker通过自主利用MLLMs内在的“grounding”和“captioning”能力,在推理过程中生成推理线索。为了激发这种能力,作者构建了一个名为Video-Thinker-10K的数据集,该数据集包含在思维链推理序列中自主工具的使用。训练策略首先采用监督微调(SFT)来学习推理格式,然后采用组相对策略优化(GRPO)来加强推理能力。Video-Thinker使MLLMs能够自主地进行视频推理的grounding和captioning任务,无需构建和调用外部工具。大量实验表明,Video-Thinker在领域内任务和具有挑战性的领域外视频推理基准(包括Video-Holmes、CG-Bench-Reasoning和VRBench)上都取得了显著的性能提升。Video-Thinker-7B显著优于现有基线(如Video-R1),并在7B大小的MLLM中建立了最先进的性能。
🔬 方法详解
问题定义:现有方法在视频推理方面存在不足,无法像图像推理一样进行动态推理。现有的多模态大语言模型虽然在图像推理上取得了显著进展,但缺乏有效利用视频信息进行复杂推理的能力。痛点在于如何让模型自主地从视频中提取关键信息,并将其用于推理过程。
核心思路:Video-Thinker的核心思路是赋予多模态大语言模型自主进行视频推理的能力,使其能够像人类一样,通过观察视频并提取关键信息,逐步进行推理。通过强化学习,模型能够自主地利用其内在的“grounding”和“captioning”能力,生成推理线索,从而实现更有效的视频推理。
技术框架:Video-Thinker的整体框架包括以下几个主要阶段:首先,构建Video-Thinker-10K数据集,该数据集包含在思维链推理序列中自主工具的使用。然后,使用监督微调(SFT)来学习推理格式。最后,采用组相对策略优化(GRPO)来加强推理能力。该框架允许模型自主地进行视频推理的grounding和captioning任务,无需构建和调用外部工具。
关键创新:Video-Thinker最重要的技术创新点在于它通过强化学习,使MLLM能够自主地进行视频推理,而无需依赖外部工具或人工干预。与现有方法相比,Video-Thinker能够更有效地利用视频信息,生成更准确的推理结果。此外,GRPO的引入进一步提升了模型的推理能力。
关键设计:Video-Thinker的关键设计包括:Video-Thinker-10K数据集的构建,该数据集包含了丰富的视频推理场景和思维链推理序列;监督微调(SFT)阶段,用于学习推理格式;组相对策略优化(GRPO)阶段,用于加强推理能力。具体的参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
Video-Thinker在多个视频推理基准上取得了显著的性能提升。在Video-Holmes、CG-Bench-Reasoning和VRBench等领域外视频推理基准上,Video-Thinker-7B显著优于现有基线(如Video-R1),并在7B大小的MLLM中建立了最先进的性能。具体的性能数据和提升幅度未在摘要中详细说明,属于未知信息。
🎯 应用场景
Video-Thinker具有广泛的应用前景,可应用于智能监控、视频内容理解、自动驾驶、机器人导航等领域。通过赋予机器更强的视频推理能力,可以实现更智能化的决策和控制,提高工作效率和安全性。未来,该技术有望在医疗诊断、教育培训等领域发挥重要作用。
📄 摘要(原文)
Recent advances in image reasoning methods, particularly "Thinking with Images", have demonstrated remarkable success in Multimodal Large Language Models (MLLMs); however, this dynamic reasoning paradigm has not yet been extended to video reasoning tasks. In this paper, we propose Video-Thinker, which empowers MLLMs to think with videos by autonomously leveraging their intrinsic "grounding" and "captioning" capabilities to generate reasoning clues throughout the inference process. To spark this capability, we construct Video-Thinker-10K, a curated dataset featuring autonomous tool usage within chain-of-thought reasoning sequences. Our training strategy begins with Supervised Fine-Tuning (SFT) to learn the reasoning format, followed by Group Relative Policy Optimization (GRPO) to strengthen this reasoning capability. Through this approach, Video-Thinker enables MLLMs to autonomously navigate grounding and captioning tasks for video reasoning, eliminating the need for constructing and calling external tools. Extensive experiments demonstrate that Video-Thinker achieves significant performance gains on both in-domain tasks and challenging out-of-domain video reasoning benchmarks, including Video-Holmes, CG-Bench-Reasoning, and VRBench. Our Video-Thinker-7B substantially outperforms existing baselines such as Video-R1 and establishes state-of-the-art performance among 7B-sized MLLMs.