VideoTG-R1: Boosting Video Temporal Grounding via Curriculum Reinforcement Learning on Reflected Boundary Annotations
作者: Lu Dong, Haiyu Zhang, Han Lin, Ziang Yan, Xiangyu Zeng, Hongjie Zhang, Yifei Huang, Yi Wang, Zhen-Hua Ling, Limin Wang, Yali Wang
分类: cs.CV
发布日期: 2025-10-27
🔗 代码/项目: GITHUB
💡 一句话要点
VideoTG-R1:通过反射边界标注上的课程强化学习提升视频时序定位
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频时序定位 强化学习 课程学习 多模态大语言模型 边界反射标注
📋 核心要点
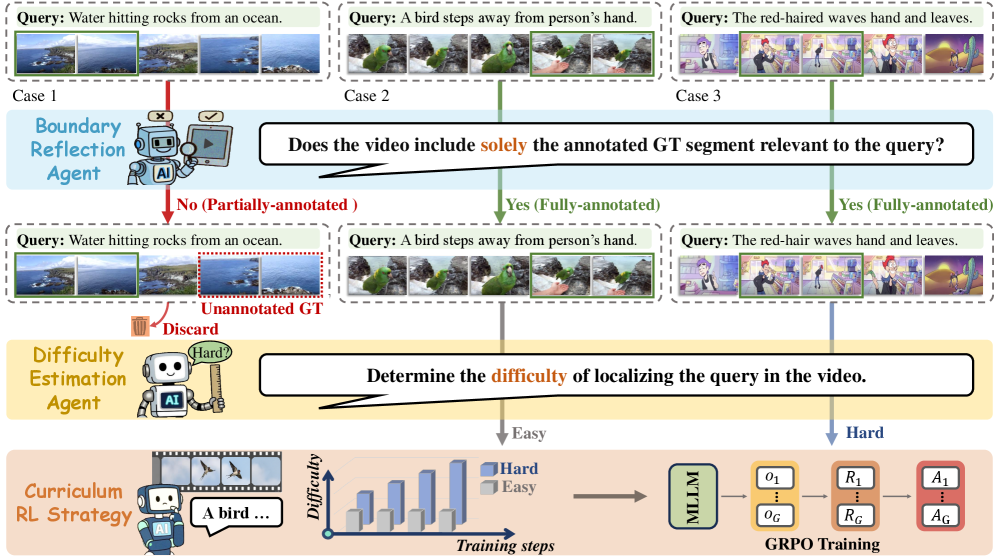
- 现有视频时序定位方法忽略了训练样本质量和难度带来的挑战,如部分标注样本和难以定位的样本。
- VideoTG-R1提出一种具有反射边界标注的课程强化学习框架,通过边界反射代理和难度估计代理来解决上述问题。
- 实验表明,VideoTG-R1仅使用少量数据和计算资源,即可在视频时序定位和视频问答任务上超越全数据训练的方法。
📝 摘要(中文)
视频时序定位(VTG)旨在根据语言查询在视频中定位精确的片段,这是视频理解中的一个基本挑战。虽然最近的多模态大型语言模型(MLLM)在通过强化学习(RL)解决VTG方面显示出前景,但它们忽略了训练样本的质量和难度带来的挑战。(1)部分标注的样本:许多样本包含超出标注间隔的相关片段,引入了模糊的监督。(2)难以定位的样本:零样本性能差的样本在RL训练期间产生持续低且难以区分的奖励,在多个输出之间没有明确的偏好,从而阻碍了学习效率。为了应对这些挑战,我们提出了VideoTG-R1,一种新颖的具有反射边界标注的课程强化学习框架,能够实现数据高效的训练。具体来说,我们提出了一个边界反射代理,它利用MLLM来预测标注间隔之外的查询相关时间戳,从而使我们能够识别和过滤掉部分标注的样本,从而减少歧义。此外,我们引入了一个难度估计代理来评估每个样本的训练难度,并设计了一种课程强化学习策略,该策略根据训练步骤动态地屏蔽难以定位的视频样本,从而降低训练难度并提供更清晰的偏好。在VTG和基于视频的问答任务上的实验证明了我们方法的有效性。值得注意的是,仅使用10%的训练样本和21%的计算预算,VideoTG-R1在组相对策略优化(GRPO)和监督微调(SFT)下均优于全数据对应方法。
🔬 方法详解
问题定义:视频时序定位旨在根据给定的文本查询,在视频中找到对应的时间片段。现有方法在训练时面临两个主要问题:一是部分标注问题,即标注区间外可能也存在相关内容,导致监督信号不准确;二是难例问题,即某些视频难以定位,导致强化学习训练时奖励信号区分度不高,难以学习。
核心思路:VideoTG-R1的核心思路是通过课程强化学习,逐步引入更难的样本进行训练,并利用多模态大语言模型(MLLM)来辅助判断样本的质量和难度,从而提高训练效率和模型性能。具体来说,它通过边界反射代理来识别和过滤部分标注的样本,并通过难度估计代理来评估样本的训练难度。
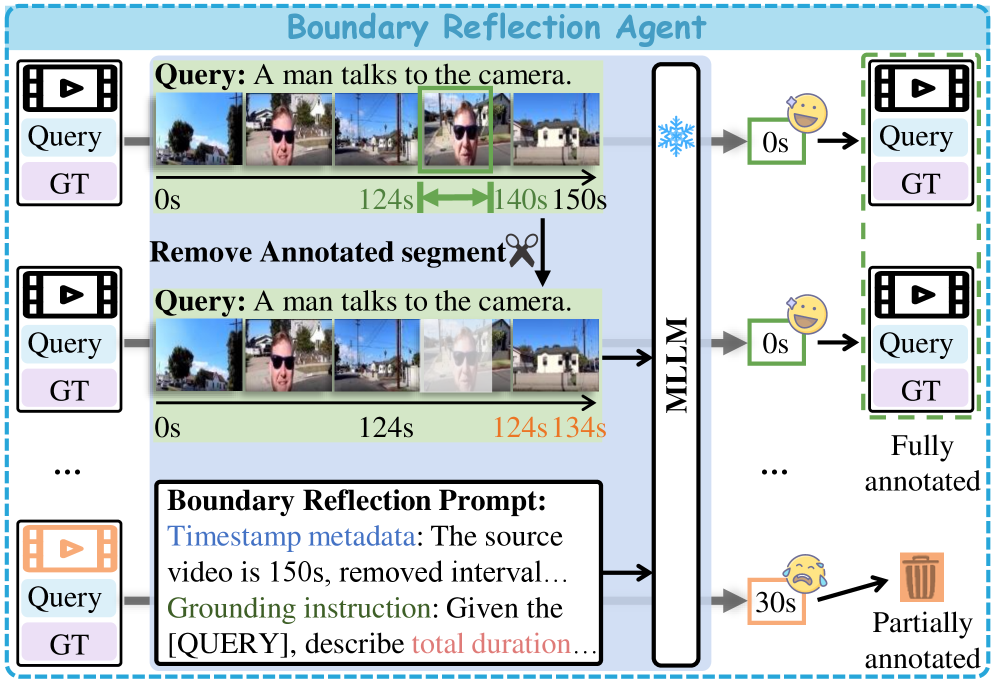
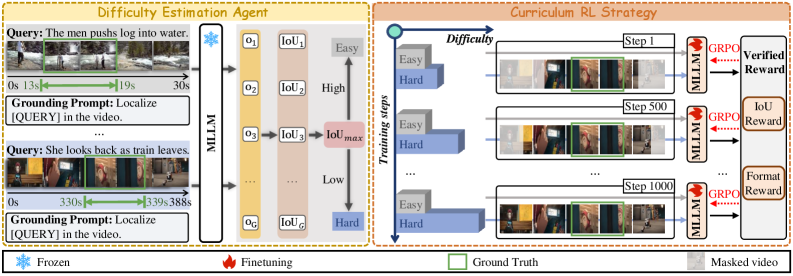
技术框架:VideoTG-R1的整体框架包含以下几个主要模块:1) 边界反射代理:利用MLLM预测标注区间外的相关时间戳,用于识别和过滤部分标注样本。2) 难度估计代理:评估每个样本的训练难度,用于后续的课程学习。3) 课程强化学习:根据样本难度,动态地屏蔽难以定位的视频样本,逐步增加训练难度。4) 训练过程:首先使用边界反射代理过滤数据,然后使用难度估计代理评估难度,最后进行课程强化学习训练。
关键创新:VideoTG-R1的关键创新在于:1) 提出了边界反射代理,利用MLLM来识别和过滤部分标注的样本,从而减少了训练数据的噪声。2) 提出了难度估计代理,用于评估样本的训练难度,从而可以进行更有效的课程学习。3) 将边界反射标注和课程强化学习结合起来,实现了数据高效的视频时序定位。
关键设计:1) 边界反射代理:使用MLLM预测标注区间外的相关时间戳,并设置阈值来判断样本是否为部分标注。2) 难度估计代理:使用模型的零样本性能来评估样本的难度,性能越差,难度越高。3) 课程强化学习:根据训练步骤动态地屏蔽难以定位的视频样本,屏蔽比例随着训练的进行而逐渐降低。4) 损失函数:使用标准的强化学习损失函数,例如GRPO。
🖼️ 关键图片
📊 实验亮点
VideoTG-R1在视频时序定位和视频问答任务上取得了显著的性能提升。在相同的性能下,该方法仅使用10%的训练样本和21%的计算预算,就能够超越使用全量数据训练的方法。这表明VideoTG-R1具有很高的数据效率和计算效率,能够在资源有限的情况下取得良好的性能。
🎯 应用场景
VideoTG-R1可应用于智能视频分析、视频检索、视频问答等领域。通过更精确地定位视频中的关键片段,可以提升视频理解的准确性和效率,例如在视频监控中快速定位异常事件,在视频搜索中快速找到用户感兴趣的内容,以及在视频问答中准确回答用户提出的问题。该研究有助于推动视频理解技术的发展,并为相关应用提供更强大的技术支持。
📄 摘要(原文)
Video temporal grounding (VTG) aims to locate precise segments in videos based on language queries, which is a fundamental challenge in video understanding. While recent Multimodal Large Language Models (MLLMs) have shown promise in tackling VTG through reinforcement learning (RL), they overlook the challenges arising from both the quality and difficulty of training samples. (1) Partially annotated samples. Many samples contain relevant segments beyond the annotated interval, introducing ambiguous supervision. (2) Hard-to-ground samples. Samples with poor zero-shot performance produce consistently low and indistinguishable rewards during RL training, exhibiting no clear preference among multiple outputs and thus hindering learning efficiency. To address these challenges, we propose VideoTG-R1, a novel curriculum RL framework with reflected boundary annotations, enabling data-efficient training. Specifically, we propose a Boundary Reflection Agent that utilizes MLLMs to predict query-relevant timestamps outside the annotated intervals, allowing us to identify and filter out partially annotated samples, thereby reducing ambiguity. Furthermore, we introduce a Difficulty Estimation Agent to assess the training difficulty of each sample and design a curriculum RL strategy that dynamically masks the videos of hard-to-ground samples according to the training steps, easing the training difficulty and providing clearer preference. Experiments on the VTG and grounded VideoQA tasks demonstrate the effectiveness of our method. Remarkably, with only 10% of the training samples and 21% of the computational budget, VideoTG-R1 outperforms full-data counterparts under both group relative policy optimization (GRPO) and supervised fine-tuning (SFT). The code is available at https://github.com/ldong1111/VideoTG-R1.