DecoDINO: 3D Human-Scene Contact Prediction with Semantic Classification
作者: Lukas Bierling, Davide Pasero, Fleur Dolmans, Helia Ghasemi, Angelo Broere
分类: cs.CV
发布日期: 2025-10-27
🔗 代码/项目: GITHUB
💡 一句话要点
提出DecoDINO以解决人类与场景接触预测问题
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction)
关键词: 接触预测 人机交互 增强现实 虚拟现实 深度学习 语义标签 三分支网络
📋 核心要点
- 现有方法DECO在处理软表面和遮挡时存在局限,且容易产生假阳性接触。
- DecoDINO通过引入三分支网络和DINOv2编码器,结合平衡损失和交叉注意力来提升接触预测精度。
- 在DAMON基准测试中,DecoDINO的二元接触F1分数提高了7%,测地误差减半,并增加了语义标签的预测能力。
📝 摘要(中文)
准确的顶点级接触预测是高保真度人类与物体交互模型的前提,这些模型广泛应用于机器人、增强现实/虚拟现实和行为模拟等领域。DECO是首个用于此任务的野外估计器,但其局限于二元接触图,并在软表面、遮挡、儿童和假阳性脚接触方面存在困难。为了解决这些问题,本文提出了DecoDINO,一个基于DECO框架的三分支网络。该网络使用两个DINOv2 ViT-g/14编码器,采用平衡损失加权以减少偏差,并通过补丁级交叉注意力来改善局部推理。最终,顶点特征通过轻量级多层感知机(MLP)和softmax分配语义接触标签。在DAMON基准测试中,DecoDINO显著提高了二元接触F1分数,减少了测地误差,并增强了对象级语义标签的预测。
🔬 方法详解
问题定义:本文旨在解决人类与周围物体之间的顶点级接触预测问题。现有方法DECO在处理软表面、遮挡和假阳性脚接触时存在明显不足,限制了其在实际应用中的有效性。
核心思路:DecoDINO的核心思路是通过三分支网络结构,结合DINOv2编码器和交叉注意力机制,来改善接触预测的准确性和鲁棒性。这样的设计旨在提升模型对复杂场景的理解能力。
技术框架:DecoDINO的整体架构包括三个主要模块:两个DINOv2 ViT-g/14编码器用于特征提取,一个轻量级多层感知机(MLP)用于最终的语义标签分配。模型还采用了平衡损失加权策略,以减少训练过程中的偏差。
关键创新:DecoDINO的主要创新在于引入了双编码器架构和补丁级交叉注意力机制,这与DECO的单一编码器设计形成了鲜明对比,显著提升了局部推理能力。
关键设计:在损失函数设计上,采用了平衡损失加权,以确保不同类别的接触预测均衡。此外,模型的轻量级MLP结构使得计算效率得以提升,同时保持了预测的准确性。通过LoRA微调技术,进一步增强了模型的性能。
🖼️ 关键图片


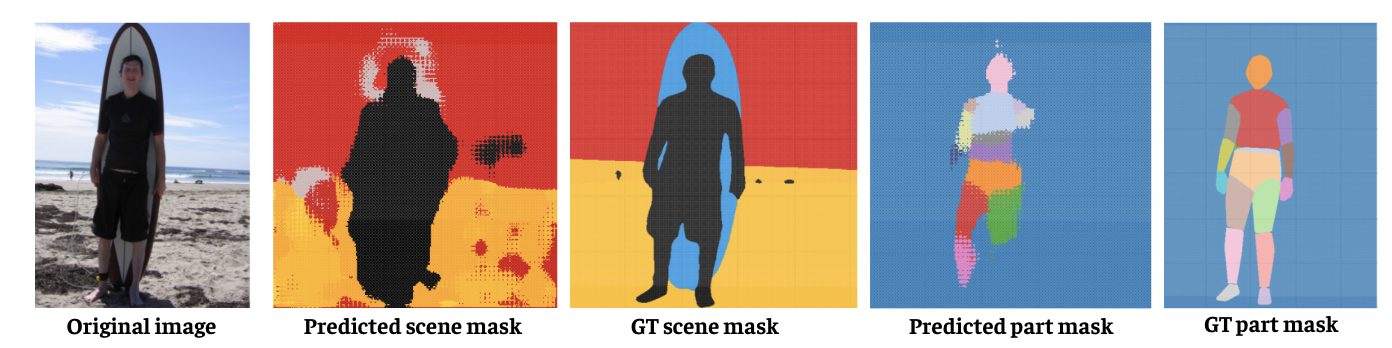
📊 实验亮点
DecoDINO在DAMON基准测试中表现优异,二元接触F1分数提高了7%,测地误差减半,并成功增强了对象级语义标签的预测能力,超越了挑战基线。
🎯 应用场景
DecoDINO的研究成果在多个领域具有广泛的应用潜力,包括机器人技术中的人机交互、增强现实和虚拟现实中的场景理解,以及行为模拟中的人类行为预测。其高精度的接触预测能力将推动这些领域的技术进步和应用落地。
📄 摘要(原文)
Accurate vertex-level contact prediction between humans and surrounding objects is a prerequisite for high fidelity human object interaction models used in robotics, AR/VR, and behavioral simulation. DECO was the first in the wild estimator for this task but is limited to binary contact maps and struggles with soft surfaces, occlusions, children, and false-positive foot contacts. We address these issues and introduce DecoDINO, a three-branch network based on DECO's framework. It uses two DINOv2 ViT-g/14 encoders, class-balanced loss weighting to reduce bias, and patch-level cross-attention for improved local reasoning. Vertex features are finally passed through a lightweight MLP with a softmax to assign semantic contact labels. We also tested a vision-language model (VLM) to integrate text features, but the simpler architecture performed better and was used instead. On the DAMON benchmark, DecoDINO (i) raises the binary-contact F1 score by 7$\%$, (ii) halves the geodesic error, and (iii) augments predictions with object-level semantic labels. Ablation studies show that LoRA fine-tuning and the dual encoders are key to these improvements. DecoDINO outperformed the challenge baseline in both tasks of the DAMON Challenge. Our code is available at https://github.com/DavidePasero/deco/tree/main.