AG-Fusion: adaptive gated multimodal fusion for 3d object detection in complex scenes
作者: Sixian Liu, Chen Xu, Qiang Wang, Donghai Shi, Yiwen Li
分类: cs.CV, cs.LG
发布日期: 2025-10-27
💡 一句话要点
提出自适应门控多模态融合AG-Fusion,解决复杂场景下3D目标检测的鲁棒性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D目标检测 多模态融合 自适应门控 跨模态注意力 BEV表示 鲁棒性 复杂场景
📋 核心要点
- 现有3D目标检测方法在传感器退化或环境干扰等复杂场景下,性能显著下降,鲁棒性不足。
- 提出AG-Fusion,通过自适应门控融合跨模态知识,选择性地整合可靠模式,增强复杂场景下的检测鲁棒性。
- 在KITTI数据集上达到93.92%的精度,并在更具挑战性的E3D数据集上超越基线24.88%,验证了方法的有效性。
📝 摘要(中文)
多模态相机-激光雷达融合技术在3D目标检测中得到了广泛应用,并展现出令人鼓舞的性能。然而,现有方法在传感器退化或环境干扰等具有挑战性的场景中表现出显著的性能下降。我们提出了一种新的自适应门控融合(AG-Fusion)方法,通过识别可靠的模式来选择性地整合跨模态知识,从而在复杂场景中实现鲁棒的检测。具体来说,我们首先将来自每个模态的特征投影到统一的BEV空间中,并使用基于窗口的注意力机制来增强它们。随后,设计了一个基于跨模态注意力的自适应门控融合模块,以将这些特征整合到对具有挑战性的环境具有鲁棒性的可靠BEV表示中。此外,我们构建了一个名为Excavator3D(E3D)的新数据集,专注于具有挑战性的挖掘机操作场景,以评估复杂条件下的性能。我们的方法不仅在标准KITTI数据集上实现了93.92%的竞争性精度,而且在具有挑战性的E3D数据集上显著优于基线24.88%,证明了在复杂工业场景中对不可靠模态信息的卓越鲁棒性。
🔬 方法详解
问题定义:现有基于多模态融合的3D目标检测方法在复杂场景下,例如传感器数据质量下降或存在环境干扰时,性能会显著降低。这些方法无法有效地识别和利用可靠的跨模态信息,导致检测精度下降,鲁棒性不足。因此,需要一种能够自适应地选择和融合跨模态信息的方法,以应对复杂场景下的挑战。
核心思路:AG-Fusion的核心思路是利用跨模态注意力机制,学习一个自适应门控,用于选择性地融合来自不同模态的特征。该门控能够根据各个模态的可靠性动态地调整融合权重,从而抑制不可靠模态的影响,突出可靠模态的贡献。通过这种方式,AG-Fusion能够有效地利用跨模态信息,提高在复杂场景下的检测鲁棒性。
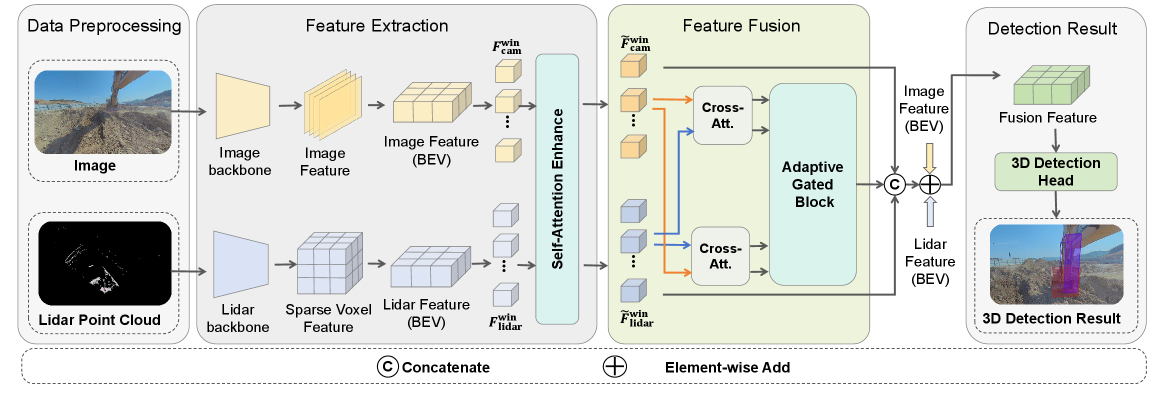
技术框架:AG-Fusion的整体框架包括以下几个主要阶段:1) 特征投影:将来自不同模态(相机和激光雷达)的特征投影到统一的BEV(Bird's-Eye View)空间中。2) 特征增强:使用基于窗口的注意力机制增强BEV特征,提高特征的表达能力。3) 自适应门控融合:设计一个基于跨模态注意力的自适应门控融合模块,用于选择性地融合来自不同模态的特征。4) 3D目标检测:利用融合后的BEV特征进行3D目标检测。
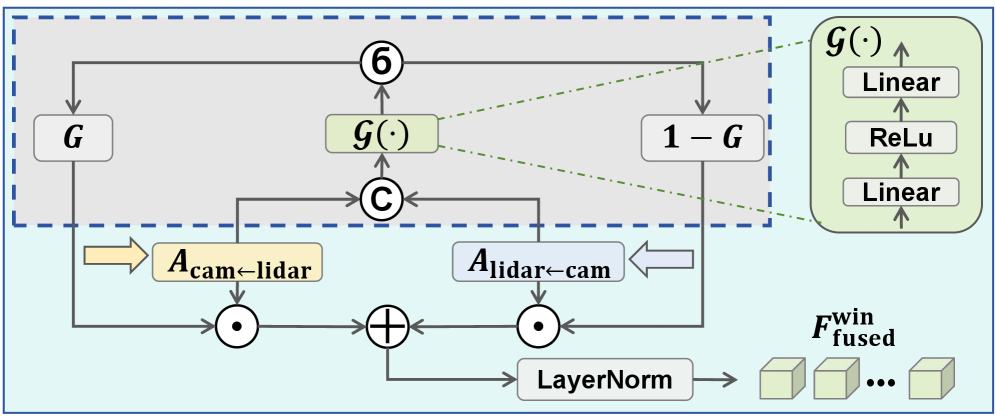
关键创新:AG-Fusion最重要的技术创新点在于自适应门控融合模块。该模块利用跨模态注意力机制学习一个门控,用于动态地调整不同模态的融合权重。与传统的固定权重融合方法相比,AG-Fusion能够根据各个模态的可靠性自适应地调整融合策略,从而提高在复杂场景下的检测鲁棒性。
关键设计:自适应门控融合模块的关键设计包括:1) 跨模态注意力机制:利用跨模态注意力机制学习不同模态之间的相关性,从而为门控的生成提供依据。2) 门控生成:基于跨模态注意力机制的结果,生成一个门控,用于控制不同模态的融合权重。3) 融合策略:利用生成的门控,对不同模态的特征进行加权融合,得到最终的BEV特征表示。
🖼️ 关键图片

📊 实验亮点
AG-Fusion在KITTI数据集上取得了93.92%的精度,与现有方法具有竞争力。更重要的是,在作者构建的更具挑战性的Excavator3D (E3D)数据集上,AG-Fusion相比基线方法提升了24.88%,充分证明了其在复杂场景下的优越鲁棒性。该结果表明AG-Fusion能够有效应对传感器退化和环境干扰等问题。
🎯 应用场景
AG-Fusion技术可广泛应用于自动驾驶、机器人、智能交通等领域。尤其在矿区、建筑工地等复杂工业场景中,传感器易受粉尘、光照等因素干扰,AG-Fusion能够有效提升3D目标检测的可靠性,保障安全生产。未来,该技术有望进一步扩展到更多复杂环境下的感知任务。
📄 摘要(原文)
Multimodal camera-LiDAR fusion technology has found extensive application in 3D object detection, demonstrating encouraging performance. However, existing methods exhibit significant performance degradation in challenging scenarios characterized by sensor degradation or environmental disturbances. We propose a novel Adaptive Gated Fusion (AG-Fusion) approach that selectively integrates cross-modal knowledge by identifying reliable patterns for robust detection in complex scenes. Specifically, we first project features from each modality into a unified BEV space and enhance them using a window-based attention mechanism. Subsequently, an adaptive gated fusion module based on cross-modal attention is designed to integrate these features into reliable BEV representations robust to challenging environments. Furthermore, we construct a new dataset named Excavator3D (E3D) focusing on challenging excavator operation scenarios to benchmark performance in complex conditions. Our method not only achieves competitive performance on the standard KITTI dataset with 93.92% accuracy, but also significantly outperforms the baseline by 24.88% on the challenging E3D dataset, demonstrating superior robustness to unreliable modal information in complex industrial scenes.