HieraMamba: Video Temporal Grounding via Hierarchical Anchor-Mamba Pooling
作者: Joungbin An, Kristen Grauman
分类: cs.CV
发布日期: 2025-10-27
备注: Project Page: https://vision.cs.utexas.edu/projects/hieramamba/
💡 一句话要点
提出HieraMamba,通过分层Anchor-Mamba池化实现视频时序定位
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction) 支柱八:物理动画 (Physics-based Animation)
关键词: 视频时序定位 长视频理解 Mamba 分层架构 对比学习
📋 核心要点
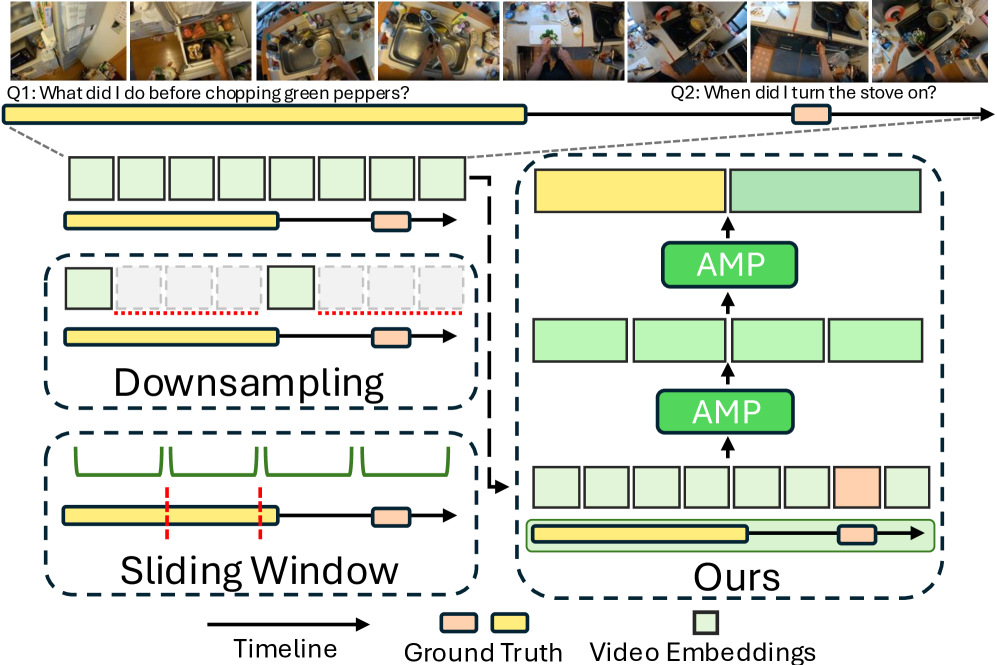
- 现有视频时序定位方法在处理长视频时,难以兼顾全局上下文和精细时间细节,常常牺牲时间保真度。
- HieraMamba通过分层架构和Anchor-Mamba池化,在不同尺度上保留时间结构和语义信息,实现更精确的定位。
- 实验表明,HieraMamba在多个数据集上取得了state-of-the-art的结果,尤其在长视频定位任务上表现突出。
📝 摘要(中文)
视频时序定位旨在从无分割视频中定位自然语言查询对应的起始和结束时间。该任务需要捕捉全局上下文和精细的时间细节。尤其是在长视频中,现有方法通常通过过度下采样或依赖固定窗口来牺牲时间保真度。我们提出了HieraMamba,一种分层架构,可在不同尺度上保持时间结构和语义丰富性。其核心是Anchor-Mamba池化(AMP)块,它利用Mamba的选择性扫描来生成紧凑的锚点token,以总结多个粒度的视频内容。两个互补的目标,即锚点条件对比损失和分段池化对比损失,鼓励锚点保留局部细节,同时保持全局区分性。HieraMamba在Ego4D-NLQ、MAD和TACoS上取得了新的state-of-the-art,展示了在长无分割视频中精确、时间保真的定位。
🔬 方法详解
问题定义:视频时序定位旨在根据给定的自然语言查询,在未分割的长视频中找到对应的时间片段。现有方法在处理长视频时,通常会过度下采样,导致时间分辨率降低,或者依赖固定大小的窗口,无法适应不同长度的查询片段,从而影响定位精度。
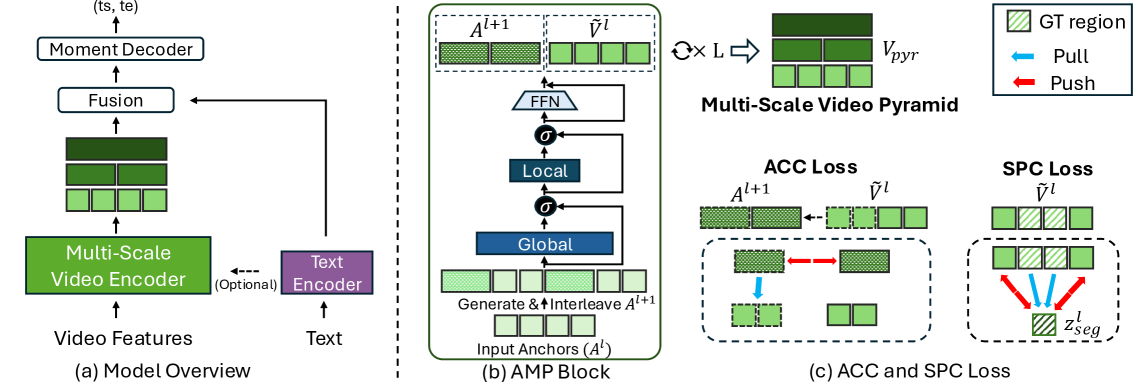
核心思路:HieraMamba的核心思路是利用分层结构和Mamba的选择性扫描机制,在不同尺度上提取视频特征,并生成具有代表性的锚点token。这些锚点token既能捕捉全局上下文信息,又能保留局部细节,从而实现更精确的时序定位。
技术框架:HieraMamba的整体架构是一个分层结构,包含多个Anchor-Mamba池化(AMP)块。每个AMP块首先使用Mamba的选择性扫描机制处理视频特征,然后生成紧凑的锚点token。这些锚点token被传递到下一层AMP块,以提取更高层次的特征。最后,使用锚点条件对比损失和分段池化对比损失来训练模型,使其能够区分不同的时间片段。
关键创新:HieraMamba的关键创新在于Anchor-Mamba池化(AMP)块和分层架构。AMP块利用Mamba的选择性扫描机制,能够有效地处理长序列数据,并生成具有代表性的锚点token。分层架构则允许模型在不同尺度上提取视频特征,从而更好地捕捉全局上下文和局部细节。与现有方法相比,HieraMamba能够更有效地处理长视频,并实现更精确的时序定位。
关键设计:HieraMamba的关键设计包括:1) 使用Mamba的选择性扫描机制来处理视频特征;2) 设计Anchor-Mamba池化(AMP)块来生成紧凑的锚点token;3) 使用分层架构来提取不同尺度的特征;4) 使用锚点条件对比损失和分段池化对比损失来训练模型。具体参数设置和网络结构细节未在摘要中详细说明,需要参考论文全文。
🖼️ 关键图片
📊 实验亮点
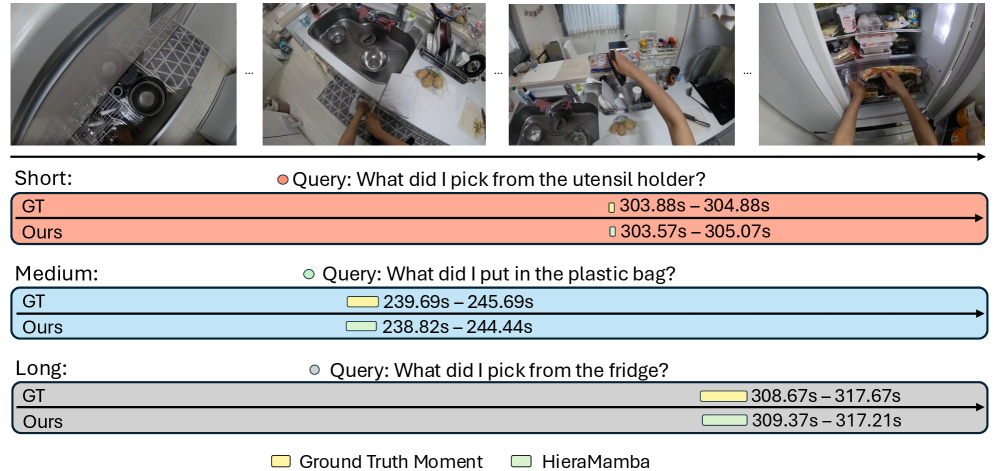
HieraMamba在Ego4D-NLQ、MAD和TACoS三个数据集上取得了state-of-the-art的结果,证明了其在长视频时序定位任务上的优越性。具体性能数据和提升幅度需要在论文中查找。该模型尤其在长视频数据集上表现突出,表明其能够有效地处理长序列数据。
🎯 应用场景
HieraMamba在视频内容理解领域具有广泛的应用前景,例如视频检索、智能监控、自动驾驶等。它可以帮助用户快速准确地找到视频中感兴趣的内容,提高视频分析的效率和准确性。未来,该技术有望应用于更复杂的视频场景,例如多模态视频分析、视频生成等。
📄 摘要(原文)
Video temporal grounding, the task of localizing the start and end times of a natural language query in untrimmed video, requires capturing both global context and fine-grained temporal detail. This challenge is particularly pronounced in long videos, where existing methods often compromise temporal fidelity by over-downsampling or relying on fixed windows. We present HieraMamba, a hierarchical architecture that preserves temporal structure and semantic richness across scales. At its core are Anchor-MambaPooling (AMP) blocks, which utilize Mamba's selective scanning to produce compact anchor tokens that summarize video content at multiple granularities. Two complementary objectives, anchor-conditioned and segment-pooled contrastive losses, encourage anchors to retain local detail while remaining globally discriminative. HieraMamba sets a new state-of-the-art on Ego4D-NLQ, MAD, and TACoS, demonstrating precise, temporally faithful localization in long, untrimmed videos.