Gen-LangSplat: Generalized Language Gaussian Splatting with Pre-Trained Feature Compression
作者: Pranav Saxena
分类: cs.CV, cs.AI
发布日期: 2025-10-27
💡 一句话要点
Gen-LangSplat:利用预训练特征压缩实现通用语言高斯溅射,提升效率。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D高斯溅射 语言场 预训练模型 特征压缩 自编码器
📋 核心要点
- 现有LangSplat方法需要为每个场景训练独立的语言自编码器进行特征压缩,这导致了高昂的计算成本和部署瓶颈。
- Gen-LangSplat通过引入预训练的通用自编码器,消除了对场景特定训练的依赖,从而显著提高了语言场构建的效率。
- 实验结果表明,Gen-LangSplat在保持甚至超过原始LangSplat查询性能的同时,极大地提升了效率,并实现了良好的表征保真度。
📝 摘要(中文)
在3D环境中建模开放词汇语言场对于直观的人机交互至关重要。LangSplat等先进方法利用3D高斯溅射高效构建这些语言场,编码从CLIP等高维模型中提取的特征。然而,这种效率被训练特定场景的语言自编码器进行特征压缩的需求所抵消,引入了昂贵的、逐场景优化的瓶颈,阻碍了部署的可扩展性。本文提出了Gen-LangSplat,通过用大规模ScanNet数据集上预训练的通用自编码器替换场景特定的自编码器,消除了这一需求。这种架构转变使得可以在任何新场景中使用固定的、紧凑的语言特征潜在空间,而无需任何场景特定的训练。通过消除这种依赖性,我们的整个语言场构建过程实现了效率提升,同时提供了与原始LangSplat方法相当或超过的查询性能。为了验证我们的设计选择,我们进行了彻底的消融研究,通过经验确定了最佳的潜在嵌入维度,并使用均方误差和原始和重投影的512维CLIP嵌入之间的余弦相似度来量化表征保真度。我们的结果表明,通用嵌入可以高效准确地支持新3D场景中的开放词汇查询,为可扩展的实时交互式3D AI应用铺平了道路。
🔬 方法详解
问题定义:LangSplat等方法在构建3D场景的语言场时,需要为每个场景单独训练一个语言自编码器来压缩CLIP特征,这导致训练成本高昂,限制了其在需要快速部署的场景中的应用。现有方法的痛点在于缺乏一种通用的、无需场景特定训练的特征压缩方案。
核心思路:Gen-LangSplat的核心思路是利用预训练的通用自编码器来替代场景特定的自编码器。通过在大规模数据集(如ScanNet)上预训练自编码器,使其能够学习到通用的场景特征表示,从而可以将其直接应用于新的场景,而无需额外的训练。
技术框架:Gen-LangSplat的整体框架与LangSplat类似,主要区别在于特征压缩模块。Gen-LangSplat使用一个预训练好的通用自编码器来将CLIP特征压缩到一个低维的潜在空间。该自编码器由编码器和解码器组成,编码器将高维CLIP特征映射到低维潜在空间,解码器则将潜在空间特征重构回原始CLIP特征。在构建语言场时,首先使用CLIP提取场景中每个3D高斯点的特征,然后使用预训练的编码器将其压缩到潜在空间,最后将潜在空间特征作为高斯点的属性进行优化。
关键创新:Gen-LangSplat最重要的创新点在于使用预训练的通用自编码器来替代场景特定的自编码器。这消除了对每个场景进行单独训练的需求,极大地提高了效率。与现有方法的本质区别在于,Gen-LangSplat学习的是一种通用的场景特征表示,而不是针对特定场景的特征表示。
关键设计:Gen-LangSplat的关键设计包括:1) 使用大规模ScanNet数据集进行自编码器的预训练;2) 通过消融实验确定最佳的潜在嵌入维度;3) 使用均方误差和余弦相似度来评估表征保真度。具体的网络结构和损失函数等细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片

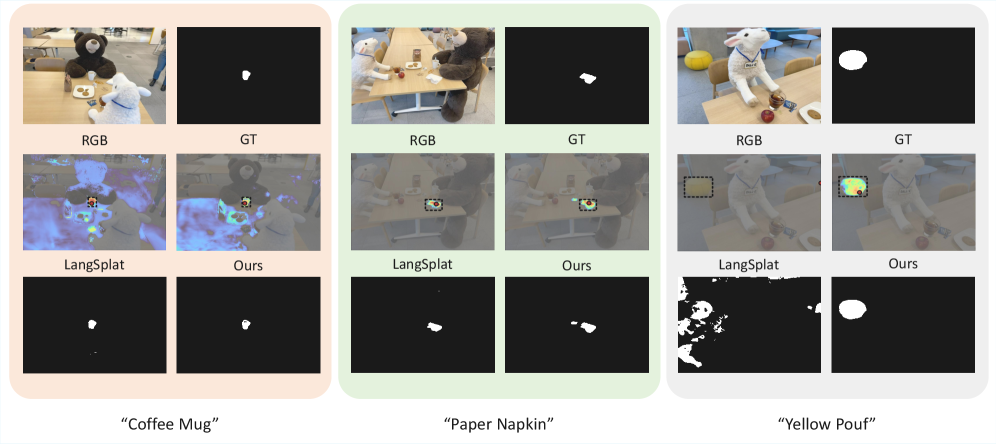

📊 实验亮点
Gen-LangSplat通过使用预训练的通用自编码器,显著提高了语言场构建的效率,消除了对场景特定训练的需求。实验结果表明,Gen-LangSplat在保持与原始LangSplat相当甚至超过的查询性能的同时,极大地提升了效率。消融研究确定了最佳的潜在嵌入维度,并使用均方误差和余弦相似度验证了表征保真度。
🎯 应用场景
Gen-LangSplat在机器人导航、虚拟现实、增强现实等领域具有广泛的应用前景。它可以用于构建智能家居环境,允许用户通过自然语言与虚拟环境进行交互。此外,该方法还可以应用于自动驾驶领域,帮助车辆理解周围环境中的语言信息,从而提高驾驶安全性。未来,Gen-LangSplat有望成为构建通用3D语言理解系统的关键技术。
📄 摘要(原文)
Modeling open-vocabulary language fields in 3D is essential for intuitive human-AI interaction and querying within physical environments. State-of-the-art approaches, such as LangSplat, leverage 3D Gaussian Splatting to efficiently construct these language fields, encoding features distilled from high-dimensional models like CLIP. However, this efficiency is currently offset by the requirement to train a scene-specific language autoencoder for feature compression, introducing a costly, per-scene optimization bottleneck that hinders deployment scalability. In this work, we introduce Gen-LangSplat, that eliminates this requirement by replacing the scene-wise autoencoder with a generalized autoencoder, pre-trained extensively on the large-scale ScanNet dataset. This architectural shift enables the use of a fixed, compact latent space for language features across any new scene without any scene-specific training. By removing this dependency, our entire language field construction process achieves a efficiency boost while delivering querying performance comparable to, or exceeding, the original LangSplat method. To validate our design choice, we perform a thorough ablation study empirically determining the optimal latent embedding dimension and quantifying representational fidelity using Mean Squared Error and cosine similarity between the original and reprojected 512-dimensional CLIP embeddings. Our results demonstrate that generalized embeddings can efficiently and accurately support open-vocabulary querying in novel 3D scenes, paving the way for scalable, real-time interactive 3D AI applications.