Look and Tell: A Dataset for Multimodal Grounding Across Egocentric and Exocentric Views
作者: Anna Deichler, Jonas Beskow
分类: cs.CV, cs.CL, cs.RO
发布日期: 2025-10-26 (更新: 2025-10-28)
备注: 10 pages, 6 figures, 2 tables. Accepted to the NeurIPS 2025 Workshop on SPACE in Vision, Language, and Embodied AI (SpaVLE). Dataset: https://huggingface.co/datasets/annadeichler/KTH-ARIA-referential
💡 一句话要点
提出Look and Tell数据集,用于研究第一人称和第三人称视角下的多模态指示性交流。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态数据集 具身智能体 指示性交流 第一人称视角 第三人称视角 3D场景重建 人机交互
📋 核心要点
- 现有方法在理解不同视角下的指示性交流方面存在挑战,尤其是在多模态信息融合方面。
- 论文核心在于构建一个包含第一人称和第三人称视角的多模态数据集,用于研究指示性交流中的空间关系。
- 该数据集包含同步的注视、语音、视频和3D场景重建,为具身智能体的开发提供了宝贵的资源。
📝 摘要(中文)
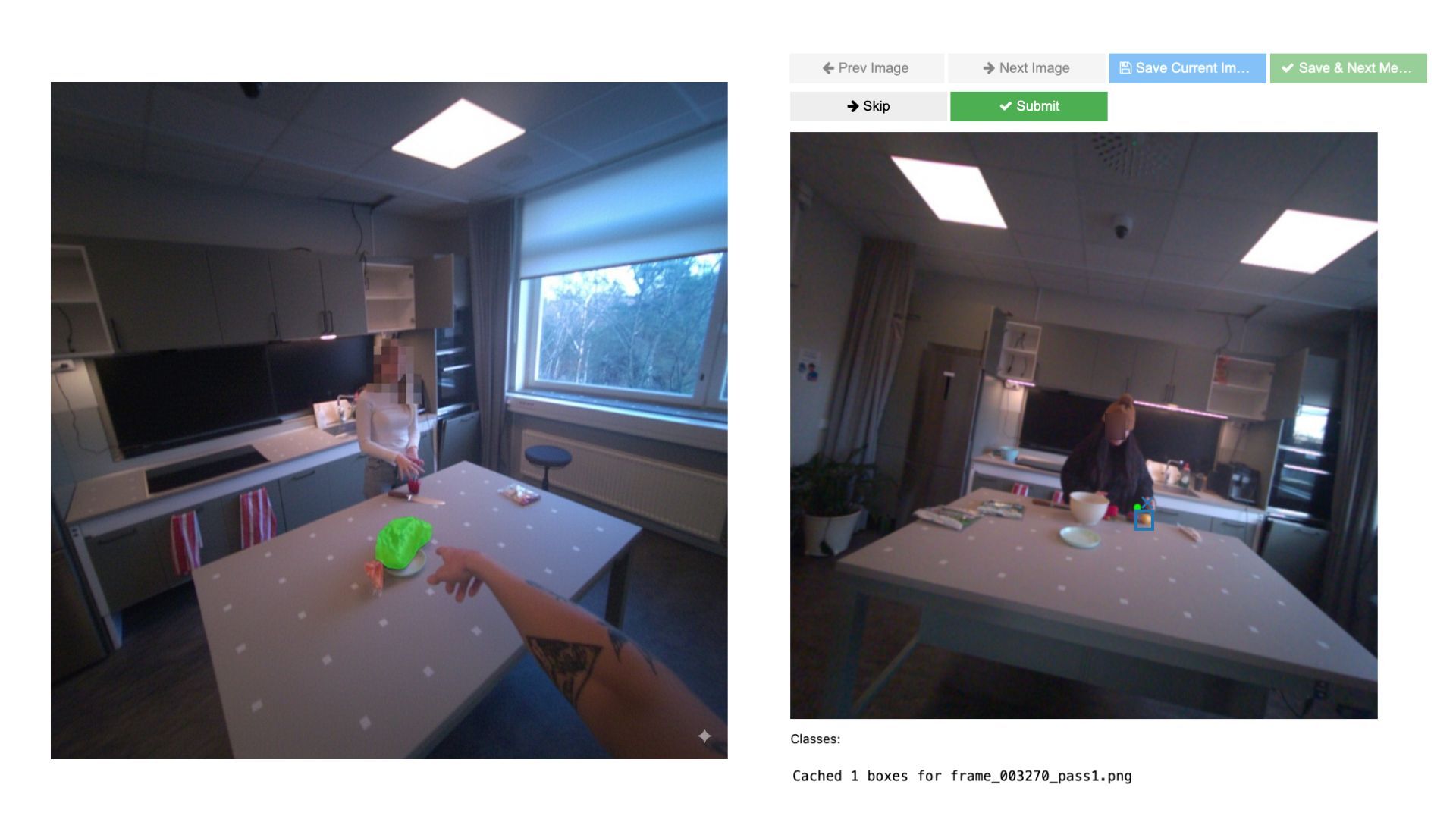
本文介绍Look and Tell,一个用于研究以自我中心和以外部中心视角进行指示性交流的多模态数据集。我们使用Meta Project Aria智能眼镜和固定摄像头,记录了25名参与者在厨房中指导同伴识别食材时的同步注视、语音和视频。结合3D场景重建,该设置提供了一个基准,用于评估不同的空间表示(2D vs. 3D;自我 vs. 外部)如何影响多模态定位。该数据集包含3.67小时的录音,包括2,707个带有丰富注释的指示性表达,旨在推进能够理解和参与情境对话的具身智能体的开发。
🔬 方法详解
问题定义:论文旨在解决具身智能体在理解和参与情境对话时,如何有效地融合来自不同视角的(自我中心和外部中心)多模态信息,从而准确理解指示性表达的问题。现有方法在处理这种跨视角的指示性交流时,缺乏足够的数据支持和有效的评估基准,难以充分利用不同视角的空间信息。
核心思路:论文的核心思路是构建一个高质量的多模态数据集,该数据集包含同步的自我中心视角(智能眼镜)和外部中心视角(固定摄像头)的视频、语音和注视数据,以及3D场景重建信息。通过提供这些丰富的数据,研究者可以更好地研究不同空间表示(2D vs. 3D;自我 vs. 外部)如何影响多模态定位,并开发更有效的具身智能体。
技术框架:该研究的技术框架主要围绕数据集的构建展开,包括以下几个关键步骤: 1. 数据采集:使用Meta Project Aria智能眼镜和固定摄像头同步记录参与者在厨房环境中进行指示性交流时的视频、语音和注视数据。 2. 场景重建:利用采集到的视频数据进行3D场景重建,提供场景的几何信息。 3. 数据标注:对录音进行转录,并对指示性表达进行详细标注,包括所指对象、属性等。 4. 数据同步:将不同模态的数据进行时间同步,确保数据的一致性。
关键创新:该论文的关键创新在于构建了一个独特的多模态数据集,该数据集同时包含自我中心和外部中心视角的信息,并结合了3D场景重建。这种多视角的结合使得研究者可以更全面地研究指示性交流中的空间关系,并开发更鲁棒的具身智能体。
关键设计:数据集的关键设计包括: 1. 参与者选择:选择具有不同背景和经验的参与者,以增加数据的多样性。 2. 场景设计:选择厨房环境作为实验场景,因为厨房包含丰富的物体和交互,可以更好地模拟真实世界的场景。 3. 数据同步:采用精确的时间同步技术,确保不同模态数据之间的时间一致性。 4. 标注规范:制定详细的标注规范,确保标注的一致性和准确性。
🖼️ 关键图片


📊 实验亮点
该数据集包含3.67小时的录音,包括2,707个带有丰富注释的指示性表达。通过提供同步的注视、语音、视频和3D场景重建数据,该数据集为研究多模态定位和具身智能体的开发提供了一个有价值的基准。研究者可以使用该数据集来评估不同模型的性能,并比较不同空间表示对多模态定位的影响。
🎯 应用场景
该研究成果可应用于开发更智能的家庭助手机器人、辅助视障人士的导航系统、以及提升人机协作效率的工业机器人等领域。通过理解不同视角的指示性交流,这些应用可以更好地理解人类的意图,并做出更准确的响应,从而提升用户体验和工作效率。未来,该数据集还可以用于研究更复杂的交互场景,例如多人协作和跨文化交流。
📄 摘要(原文)
We introduce Look and Tell, a multimodal dataset for studying referential communication across egocentric and exocentric perspectives. Using Meta Project Aria smart glasses and stationary cameras, we recorded synchronized gaze, speech, and video as 25 participants instructed a partner to identify ingredients in a kitchen. Combined with 3D scene reconstructions, this setup provides a benchmark for evaluating how different spatial representations (2D vs. 3D; ego vs. exo) affect multimodal grounding. The dataset contains 3.67 hours of recordings, including 2,707 richly annotated referential expressions, and is designed to advance the development of embodied agents that can understand and engage in situated dialogue.