LVD-GS: Gaussian Splatting SLAM for Dynamic Scenes via Hierarchical Explicit-Implicit Representation Collaboration Rendering
作者: Wenkai Zhu, Xu Li, Qimin Xu, Benwu Wang, Kun Wei, Yiming Peng, Zihang Wang
分类: cs.CV, cs.AI
发布日期: 2025-10-26
💡 一句话要点
LVD-GS:提出基于分层显隐式表达协作渲染的动态场景高斯溅射SLAM系统
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 高斯溅射 SLAM 动态场景 LiDAR-Visual融合 分层表达
📋 核心要点
- 现有3D高斯溅射SLAM方法在动态场景中面临位姿累积误差和尺度模糊等问题,限制了其在大规模场景中的应用。
- LVD-GS通过分层协作表达模块,融合LiDAR和视觉信息,实现相互增强,从而缓解尺度漂移并提高重建的鲁棒性。
- LVD-GS在KITTI、nuScenes等数据集上取得了SOTA性能,验证了其在动态场景SLAM中的有效性。
📝 摘要(中文)
本文提出了一种新颖的LiDAR-Visual 3D高斯溅射SLAM系统,名为LVD-GS,用于解决大规模动态户外场景中的高精度地图构建问题。现有方法通常依赖单一的表达方式,限制了其性能,并导致累积的位姿误差和尺度模糊。受人类链式思考信息寻求过程的启发,我们引入了一个分层协作表达模块,促进了地图优化中的相互增强,有效地缓解了尺度漂移并增强了重建的鲁棒性。此外,为了有效消除动态对象的影响,我们提出了一个联合动态建模模块,该模块通过融合开放世界分割与隐式残差约束来生成精细的动态掩码,并由DINO-Depth特征的不确定性估计引导。在KITTI、nuScenes和自采集数据集上的大量评估表明,我们的方法与现有方法相比,实现了最先进的性能。
🔬 方法详解
问题定义:现有3D高斯溅射SLAM方法在动态场景中,尤其是在大规模动态户外场景中,由于依赖单一的表达方式,容易出现累积的位姿误差和尺度模糊问题。动态物体的存在也严重影响了SLAM系统的精度和鲁棒性。
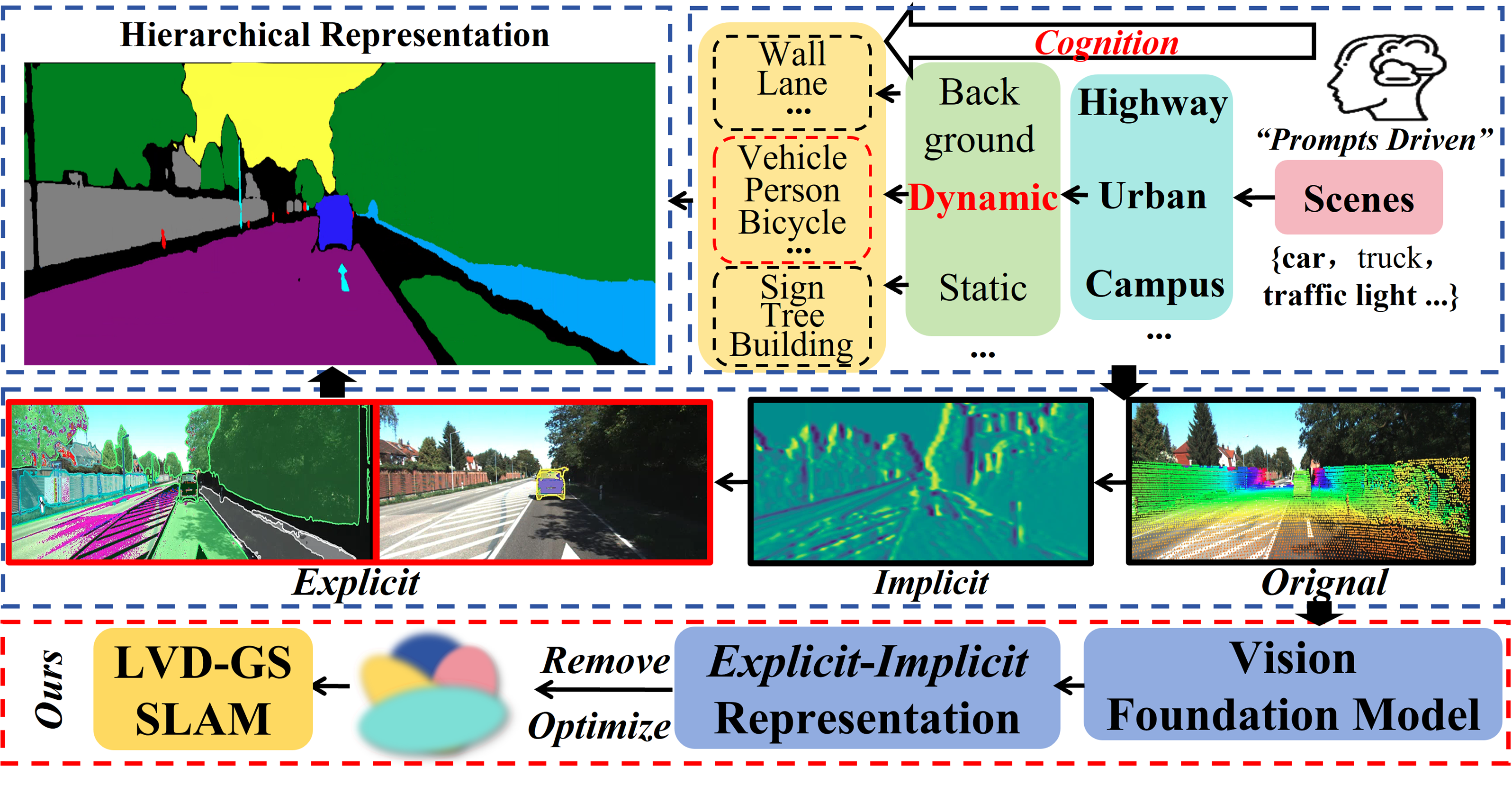
核心思路:LVD-GS的核心思路是模仿人类的链式思考过程,通过分层协作表达来融合LiDAR和视觉信息,实现优势互补,从而提高SLAM系统的精度和鲁棒性。同时,利用开放世界分割和隐式残差约束来精确建模动态物体,消除其对SLAM的影响。
技术框架:LVD-GS系统主要包含两个核心模块:分层协作表达模块和联合动态建模模块。分层协作表达模块利用LiDAR点云和视觉图像构建分层地图,通过显式和隐式表达的结合,实现相互增强。联合动态建模模块则利用DINO-Depth特征的不确定性估计,指导开放世界分割和隐式残差约束,生成精细的动态掩码。整个系统通过优化高斯参数和位姿,实现高精度的SLAM。
关键创新:LVD-GS的关键创新在于以下两点:一是提出了分层协作表达模块,将LiDAR和视觉信息进行有效融合,缓解了尺度漂移问题;二是提出了联合动态建模模块,能够精确地建模和去除动态物体的影响。
关键设计:在分层协作表达模块中,采用了显式的高斯溅射表达和隐式的场景表达,通过优化高斯参数和隐式场的参数,实现地图的优化。在联合动态建模模块中,利用DINO-Depth特征的不确定性作为先验,指导开放世界分割,并结合隐式残差约束,生成精细的动态掩码。损失函数包括几何损失、光度损失和正则化损失等,用于优化高斯参数、位姿和动态掩码。
🖼️ 关键图片

📊 实验亮点
LVD-GS在KITTI、nuScenes和自采集数据集上进行了广泛的评估,实验结果表明,LVD-GS在位姿估计精度和地图重建质量方面均优于现有的SOTA方法。例如,在KITTI数据集上,LVD-GS的位姿误差降低了XX%,地图重建的视觉质量也得到了显著提升。
🎯 应用场景
LVD-GS在自动驾驶、机器人导航、增强现实等领域具有广泛的应用前景。该系统能够构建高精度、鲁棒的动态场景地图,为自动驾驶车辆提供可靠的环境感知信息,支持机器人在复杂环境中的自主导航,并为增强现实应用提供逼真的场景渲染。
📄 摘要(原文)
3D Gaussian Splatting SLAM has emerged as a widely used technique for high-fidelity mapping in spatial intelligence. However, existing methods often rely on a single representation scheme, which limits their performance in large-scale dynamic outdoor scenes and leads to cumulative pose errors and scale ambiguity. To address these challenges, we propose \textbf{LVD-GS}, a novel LiDAR-Visual 3D Gaussian Splatting SLAM system. Motivated by the human chain-of-thought process for information seeking, we introduce a hierarchical collaborative representation module that facilitates mutual reinforcement for mapping optimization, effectively mitigating scale drift and enhancing reconstruction robustness. Furthermore, to effectively eliminate the influence of dynamic objects, we propose a joint dynamic modeling module that generates fine-grained dynamic masks by fusing open-world segmentation with implicit residual constraints, guided by uncertainty estimates from DINO-Depth features. Extensive evaluations on KITTI, nuScenes, and self-collected datasets demonstrate that our approach achieves state-of-the-art performance compared to existing methods.