SARVLM: A Vision Language Foundation Model for Semantic Understanding and Target Recognition in SAR Imagery
作者: Qiwei Ma, Zhiyu Wang, Wang Liu, Xukun Lu, Bin Deng, Puhong Duan, Xudong Kang, Shutao Li
分类: cs.CV, cs.AI
发布日期: 2025-10-26 (更新: 2025-11-26)
备注: 11 pages, 9 figures
💡 一句话要点
提出SARVLM:面向SAR图像语义理解和目标识别的视觉语言基础模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: SAR图像 视觉语言模型 多模态学习 领域迁移学习 语义理解
📋 核心要点
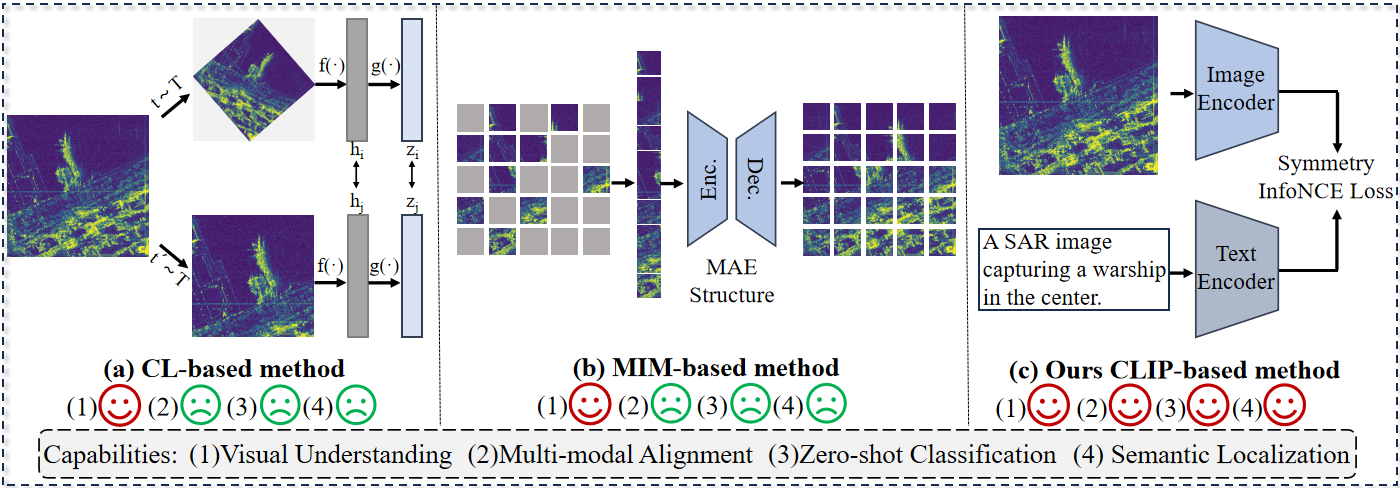
- 现有SAR基础模型侧重低级视觉特征,忽略了多模态对齐和零样本目标识别。
- 提出SARVLM,利用领域迁移训练策略,弥合自然图像和SAR图像的差距,实现视觉-语言对齐。
- 实验表明,SARVLM在图像文本检索等任务上优于现有VLM,提升了SAR图像的语义理解能力。
📝 摘要(中文)
合成孔径雷达(SAR)因其全天候能力成为重要的成像方式。虽然自监督学习和掩码图像建模(MIM)的最新进展推动了SAR基础模型的发展,但这些方法主要强调低级视觉特征,往往忽略了SAR图像中的多模态对齐和零样本目标识别。为了解决这个问题,我们构建了SARVLM-1M,一个包含超过一百万图像-文本对的大规模视觉语言数据集,这些数据来自现有数据集的聚合。我们进一步提出了一种领域迁移训练策略,以缓解自然图像和SAR图像之间的巨大差距。在此基础上,我们开发了SARVLM,这是第一个专为SAR定制的视觉语言基础模型(VLM),包含SARCLIP和SARCap。SARVLM在提出的领域迁移策略下,通过视觉-语言对比目标进行训练,从而桥接SAR图像和文本描述。在图像文本检索、零样本分类、语义定位和图像字幕生成方面的大量实验表明,SARVLM提供了卓越的特征提取和解释能力,优于最先进的VLM,并推动了SAR语义理解。
🔬 方法详解
问题定义:现有SAR图像处理方法,尤其是基于自监督学习的基础模型,虽然在提取低级视觉特征方面有所进展,但在多模态语义理解方面存在不足。具体来说,它们难以实现SAR图像与文本描述之间的有效关联,导致零样本目标识别等高级任务性能不佳。现有方法未能充分利用文本信息来增强SAR图像的理解。
核心思路:论文的核心思路是构建一个视觉语言基础模型(VLM),通过对比学习的方式,将SAR图像和文本描述映射到同一个语义空间。通过领域迁移训练策略,缓解自然图像和SAR图像之间的领域差异,从而提升模型在SAR图像上的泛化能力。这种方法旨在利用文本信息来指导SAR图像的特征学习,从而实现更高级的语义理解。
技术框架:SARVLM包含两个主要模块:SARCLIP和SARCap。SARCLIP负责学习SAR图像和文本描述的联合嵌入表示,通过对比学习目标,使得语义相关的图像和文本在嵌入空间中更接近。SARCap是一个图像字幕生成模型,用于生成SAR图像的文本描述。整个训练流程包括:1) 构建大规模SAR图像-文本数据集SARVLM-1M;2) 采用领域迁移训练策略,先在自然图像数据集上预训练,再迁移到SAR数据集上进行微调;3) 使用视觉-语言对比损失函数训练SARCLIP,使用交叉熵损失函数训练SARCap。
关键创新:该论文的关键创新在于:1) 提出了SARVLM,这是第一个专为SAR图像设计的视觉语言基础模型;2) 构建了大规模SAR图像-文本数据集SARVLM-1M;3) 提出了领域迁移训练策略,有效缓解了自然图像和SAR图像之间的领域差异。这些创新使得SARVLM能够更好地理解SAR图像的语义信息,并在多个下游任务上取得优异表现。
关键设计:领域迁移训练策略是关键设计之一,具体实现方式是先在ImageNet等自然图像数据集上预训练模型,然后再在SARVLM-1M数据集上进行微调。视觉-语言对比损失函数采用InfoNCE损失,用于最大化正样本对(即语义相关的图像和文本)之间的相似度,同时最小化负样本对之间的相似度。SARCLIP和SARCap的具体网络结构未知,但推测采用了Transformer架构。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SARVLM在图像文本检索、零样本分类、语义定位和图像字幕生成等任务上均取得了显著的性能提升,优于现有的视觉语言模型。具体性能数据未知,但摘要强调了SARVLM在特征提取和解释方面的卓越表现,表明其在SAR图像语义理解方面具有显著优势。
🎯 应用场景
SARVLM在遥感图像解译、目标检测、环境监测、灾害评估等领域具有广泛的应用前景。通过结合SAR图像和文本信息,可以更准确地识别地物类型、监测地表变化、评估灾害损失。该研究成果有助于提升SAR图像的应用价值,为相关领域的决策提供更可靠的依据,并可能促进SAR图像智能解译技术的进一步发展。
📄 摘要(原文)
Synthetic Aperture Radar (SAR) is a crucial imaging modality thanks to its all-weather capability. Although recent advances in self-supervised learning and masked image modeling (MIM) have enabled SAR foundation models, these methods largely emphasize low-level visual features and often overlook multimodal alignment and zero-shot target recognition in SAR imagery. To address this, we construct SARVLM-1M, a large-scale vision-language dataset with over one million image-text pairs aggregated from existing datasets. We further propose a domain transfer training strategy to mitigate the large gap between natural and SAR imagery. Building on this, we develop SARVLM, the first vision language foundation model (VLM) tailored to SAR, comprising SARCLIP and SARCap. SARVLM is trained with a vision-language contrastive objective under the proposed domain transfer strategy, bridging SAR imagery and textual descriptions. Extensive experiments on image text retrieval, zero-shot classification, semantic localization, and imagery captioning demonstrate that SARVLM delivers superior feature extraction and interpretation, outperforming state-of-the-art VLMs and advancing SAR semantic understanding. Code and datasets will be released soon.