Mitigating Attention Sinks and Massive Activations in Audio-Visual Speech Recognition with LLMs
作者: Anand, Umberto Cappellazzo, Stavros Petridis, Maja Pantic
分类: eess.AS, cs.CV, cs.SD
发布日期: 2025-10-26 (更新: 2026-01-27)
备注: IEEE ICASSP 2026. The code is available at https://github.com/umbertocappellazzo/Llama-AVSR
💡 一句话要点
针对LLM在AVSR中Attention Sink和激活值过大问题,提出解耦损失函数。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视听语音识别 大型语言模型 注意力机制 Attention Sink 解耦损失
📋 核心要点
- 现有基于LLM的AVSR方法缺乏对模型内部动态的深入理解,存在Attention Sink和激活值过大的问题。
- 该论文提出一种解耦损失函数,通过降低BOS token与其他token的余弦相似度,缓解中间sink和激活值过大的问题。
- 实验表明,该方法在高视听特征下采样率下能有效降低词错误率,并在较低下采样率下保持性能稳定。
📝 摘要(中文)
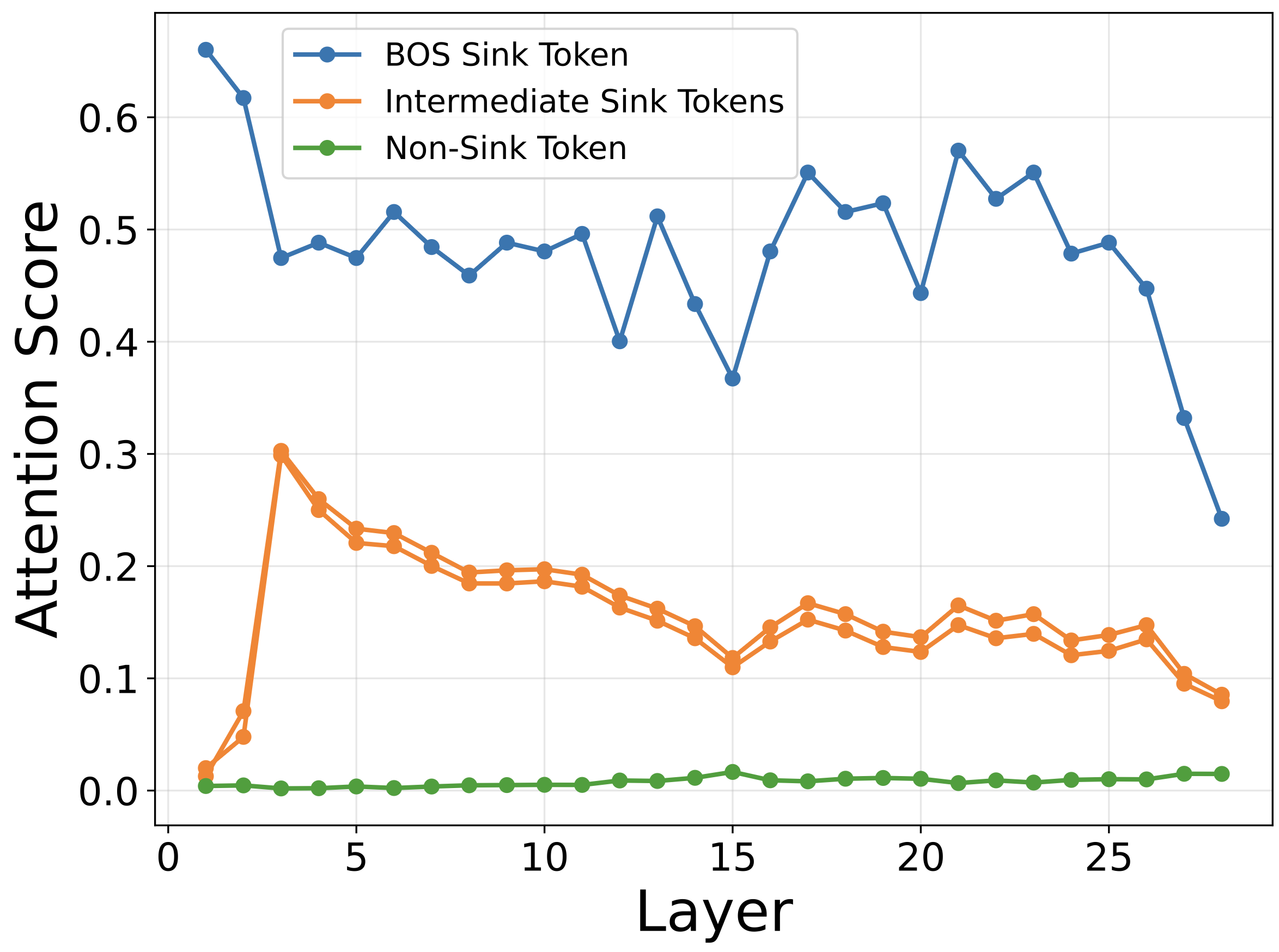
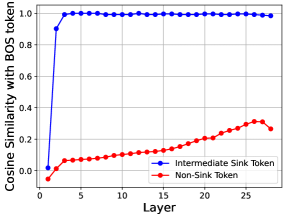
大型语言模型(LLMs)最近在听觉语音识别(ASR)、视觉语音识别(VSR)和视听语音识别(AVSR)方面取得了进展。然而,对其微调下的内部动态的理解仍然有限。在自然语言处理中,最近的研究揭示了注意力陷阱(attention sinks),即吸引不成比例的高注意力的token,以及相关的巨大激活,其中sink token的某些特征在LLM中表现出巨大的激活。在这项工作中,我们首次研究了多模态语音识别中的这些现象。通过对视听LLM的详细分析,我们不仅在BOS token处,而且在ASR、VSR和AVSR中的中间低语义token处识别出注意力陷阱和巨大激活。我们表明,巨大的激活源于MLP层,并且对应于所有sink token的固定特征索引。我们进一步表明,中间sink token与BOS token表现出高的余弦相似性,从而放大注意力和激活。基于这些见解,我们引入了一种简单的解耦损失,该损失减少了BOS和其他token之间的余弦相似性,从而有效地减轻了中间sink和巨大激活。此外,我们的方法在高的视听特征下采样下提高了词错误率(WER),同时在较低的下采样率下保持稳定。
🔬 方法详解
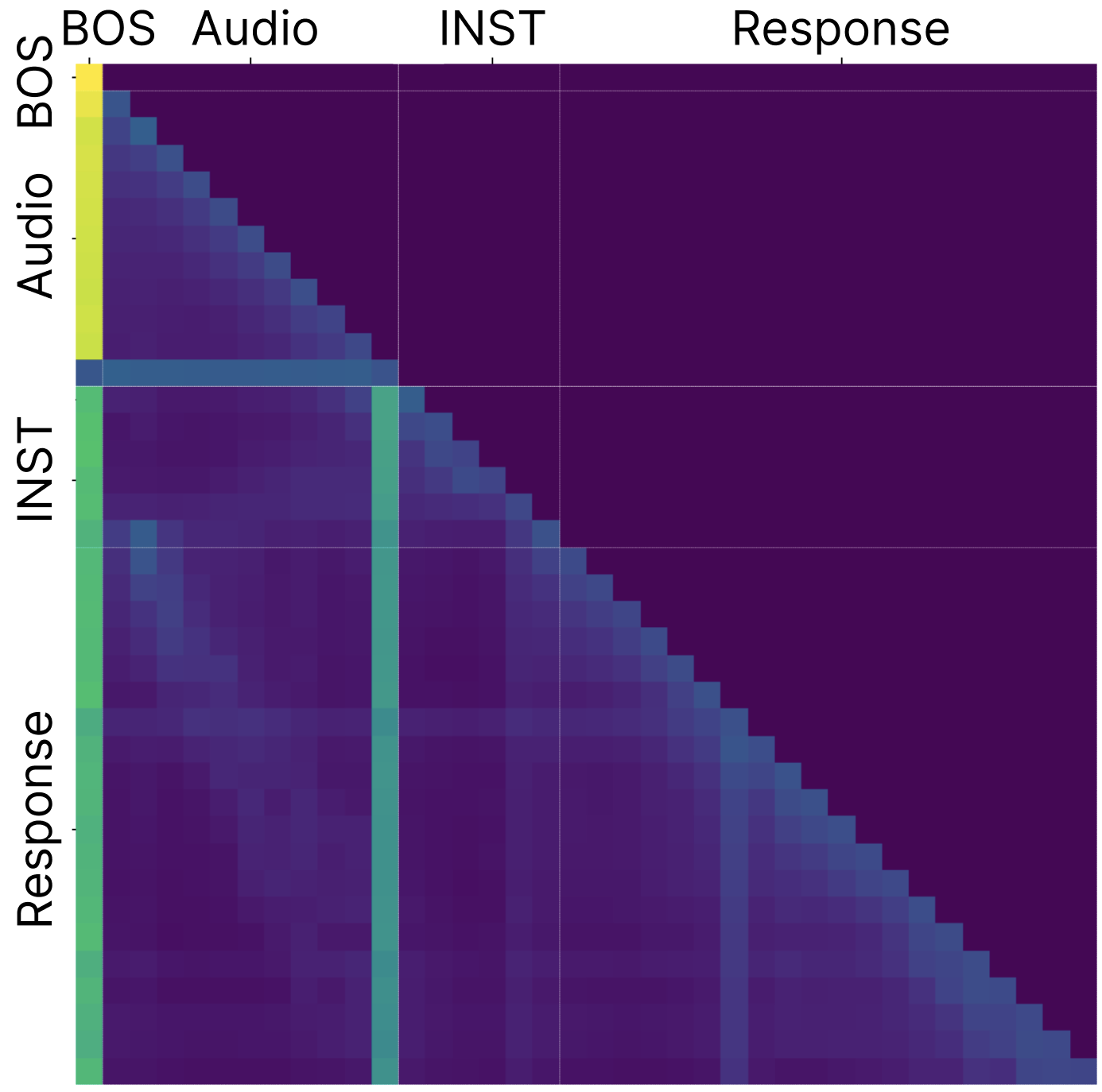
问题定义:论文旨在解决基于LLM的视听语音识别(AVSR)模型中存在的Attention Sink和激活值过大问题。现有方法在微调LLM时,对模型内部动态理解不足,导致模型在特定token(如BOS token和中间低语义token)上产生过高的注意力和激活,影响模型的性能。
核心思路:论文的核心思路是通过降低BOS token与其他token之间的余弦相似度,从而减少Attention Sink效应和激活值过大现象。作者观察到中间sink token与BOS token具有较高的余弦相似度,这会放大注意力和激活。因此,通过解耦BOS token与其他token的表示,可以有效缓解这些问题。
技术框架:该论文主要是在现有的AVSR模型基础上,增加了一个解耦损失函数。整体框架包括:1)视听特征提取模块,用于提取音频和视频特征;2)LLM编码器,用于对视听特征进行编码;3)解码器,用于生成文本序列。论文的关键在于在训练过程中引入解耦损失函数,以约束LLM编码器的输出。
关键创新:该论文的关键创新在于首次在多模态语音识别领域研究了Attention Sink和激活值过大现象,并提出了一种简单有效的解耦损失函数来缓解这些问题。与现有方法相比,该方法不需要复杂的模型结构修改,易于实现且效果显著。
关键设计:论文的关键设计在于解耦损失函数。该损失函数的目标是最小化BOS token与其他token之间的余弦相似度。具体而言,对于每个训练样本,计算BOS token的表示与其他token表示的余弦相似度,并将这些相似度值作为损失项。通过最小化该损失函数,可以促使模型学习到更加独立的BOS token表示,从而减少Attention Sink效应。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在高的视听特征下采样率下,能够显著降低词错误率(WER),并且在较低的下采样率下保持性能稳定。这表明该方法能够有效缓解Attention Sink和激活值过大问题,提高AVSR模型的鲁棒性。具体的性能提升数据在论文中给出。
🎯 应用场景
该研究成果可应用于各种需要视听语音识别的场景,例如视频会议、语音助手、智能客服等。通过提高AVSR模型的鲁棒性和准确性,可以改善用户体验,并为更高级的人机交互提供支持。此外,该研究对于理解和优化基于LLM的多模态学习模型具有重要的理论价值。
📄 摘要(原文)
Large language models (LLMs) have recently advanced auditory speech recognition (ASR), visual speech recognition (VSR), and audio-visual speech recognition (AVSR). However, understanding of their internal dynamics under fine-tuning remains limited. In natural language processing, recent work has revealed attention sinks, tokens that attract disproportionately high attention, and associated massive activations in which some features of sink tokens exhibit huge activation in LLMs. In this work, we are the first to study these phenomena in multimodal speech recognition. Through a detailed analysis of audio-visual LLMs, we identify attention sinks and massive activations not only at the BOS token but also at intermediate low-semantic tokens across ASR, VSR, and AVSR. We show that massive activations originate in the MLP layers and correspond to fixed feature indices across all sink tokens. We further show that intermediate sink tokens exhibit high cosine similarity to the BOS token, thereby amplifying attention and activation. Building on these insights, we introduce a simple decorrelation loss that reduces cosine similarity between BOS and other tokens, effectively mitigating intermediate sinks and massive activations. Furthermore, our method improves word error rate (WER) under high audio-visual feature downsampling while remaining stable at lower downsampling rates.