STATUS Bench: A Rigorous Benchmark for Evaluating Object State Understanding in Vision-Language Models
作者: Mahiro Ukai, Shuhei Kurita, Nakamasa Inoue
分类: cs.CV, cs.AI, cs.MM
发布日期: 2025-10-26
💡 一句话要点
STATUS Bench:用于评估视觉-语言模型对象状态理解能力的严格基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 对象状态识别 基准数据集 状态转换理解 多模态学习
📋 核心要点
- 现有视觉-语言模型在识别对象状态(如开关、开闭)方面能力不足,缺乏系统性的评估基准。
- 提出STATUS Bench,包含对象状态识别、图像检索和状态变化识别三个任务,以全面评估模型对对象状态的理解。
- 实验表明,现有开源模型在STATUS Bench上表现不佳,经过STATUS Train微调后,Qwen2.5-VL性能显著提升。
📝 摘要(中文)
本文提出了状态和转换理解基准(STATUS Bench),旨在严格评估视觉-语言模型(VLMs)在理解不同情境下对象状态细微变化方面的能力。STATUS Bench引入了一种新颖的评估方案,要求VLMs同时执行对象状态识别(OSI)、图像检索(IR)和状态变化识别(SCI)三项任务。该基准基于完全手工制作的数据集,包含图像对、相应的对象状态描述和状态变化描述。此外,作者还引入了一个大规模训练数据集STATUS Train,包含1300万个半自动创建的描述,为该领域的研究提供资源。实验表明,STATUS Bench能够进行严格的一致性评估,并揭示了当前最先进的VLMs在捕捉细微对象状态差异方面仍然存在困难。令人惊讶的是,在提出的严格评估方案下,大多数开源VLMs表现出接近随机水平的零样本性能。在STATUS Train上进行微调后,Qwen2.5-VL的性能达到了与Gemini 2.0 Flash相当的水平。这些发现强调了STATUS Bench和Train对于推进VLM研究中对象状态识别的必要性。
🔬 方法详解
问题定义:论文旨在解决视觉-语言模型(VLMs)在理解和识别对象状态方面的不足。现有方法缺乏一个严格的基准来评估VLMs对对象状态细微变化的理解能力,导致模型难以准确区分和识别不同的对象状态,例如“打开”和“关闭”。
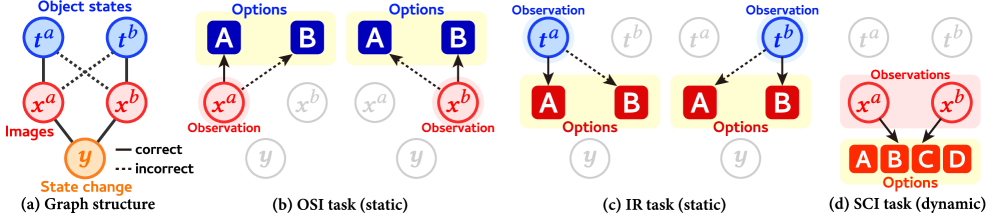
核心思路:论文的核心思路是构建一个包含多种对象状态及其变化的基准数据集(STATUS Bench),并设计一套综合性的评估方案,包括对象状态识别(OSI)、图像检索(IR)和状态变化识别(SCI)三个任务。通过这三个任务,可以全面评估VLMs对对象状态的理解和推理能力。
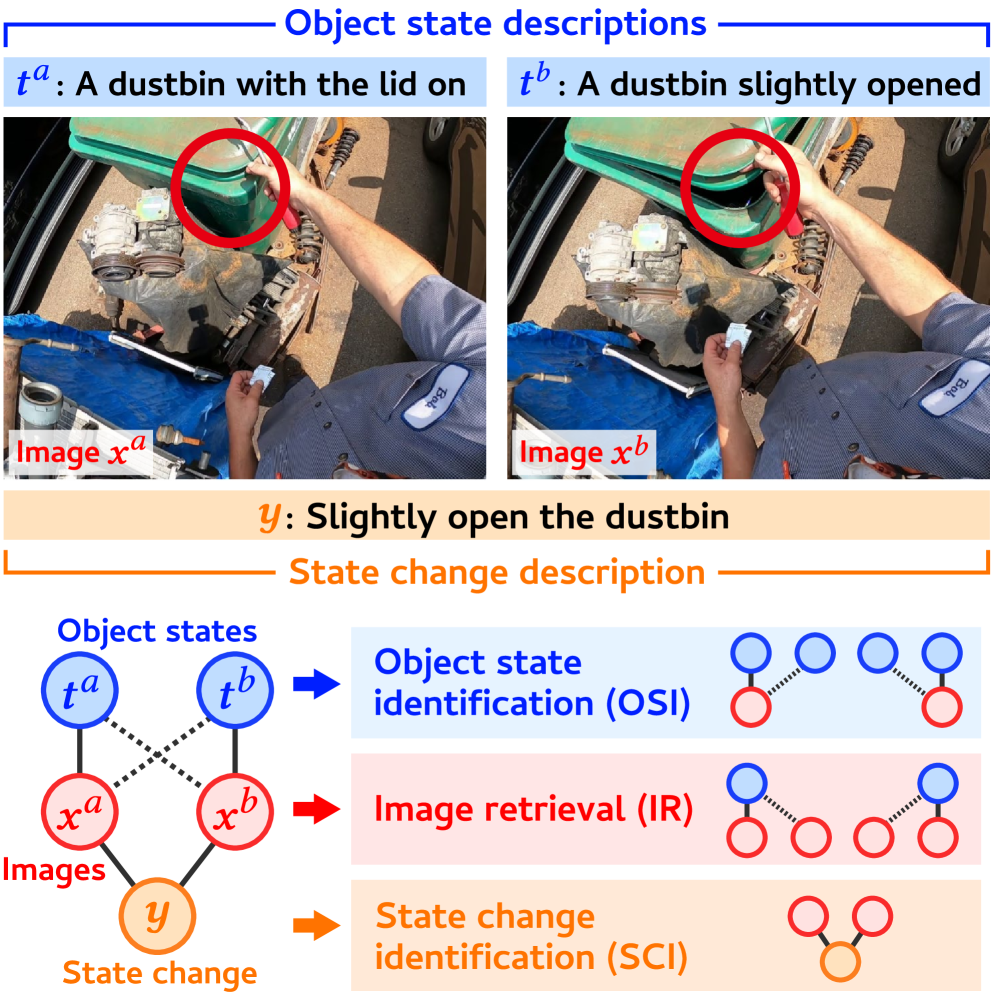
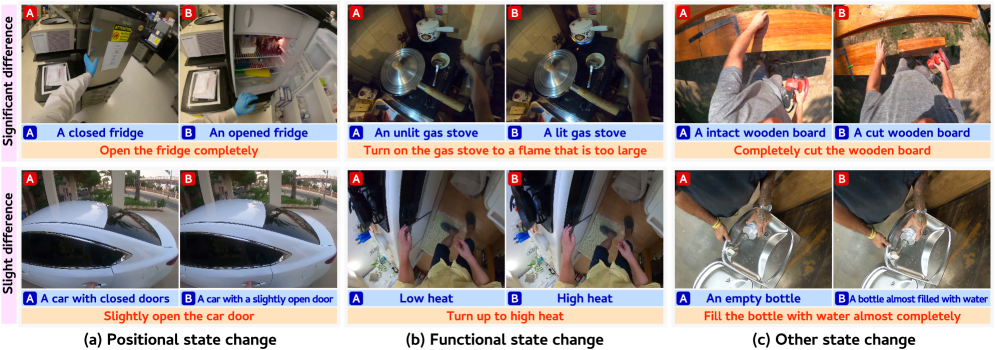
技术框架:STATUS Bench包含一个手工标注的评估数据集和一个半自动生成的大规模训练数据集(STATUS Train)。评估数据集包含图像对,以及对应的对象状态描述和状态变化描述。评估流程包括:1) 给定图像和问题,VLMs需要识别对象的状态;2) 给定查询图像,VLMs需要从候选集中检索具有相同状态的图像;3) 给定图像对,VLMs需要识别状态的变化。
关键创新:论文的关键创新在于提出了一个综合性的对象状态理解评估基准,该基准不仅包含多种对象状态,还考虑了状态的变化。此外,论文还设计了一套包含三个任务的评估方案,可以全面评估VLMs对对象状态的理解和推理能力。STATUS Train数据集的规模也远大于现有的相关数据集。
关键设计:STATUS Bench的数据集构建过程中,作者精心挑选了具有代表性的对象和状态,并对图像进行了高质量的标注。STATUS Train数据集则通过半自动化的方式生成,以保证数据的规模和多样性。在评估过程中,作者采用了多种评估指标,以全面衡量VLMs的性能。具体参数设置和损失函数等细节未在摘要中明确说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,当前最先进的开源VLMs在STATUS Bench上表现不佳,零样本性能接近随机水平。经过在STATUS Train上进行微调后,Qwen2.5-VL的性能得到了显著提升,达到了与Gemini 2.0 Flash相当的水平。这表明STATUS Bench和Train对于提升VLMs的对象状态理解能力具有重要价值。
🎯 应用场景
该研究成果可应用于智能家居、机器人导航、视频监控等领域。例如,机器人可以根据对象的状态(如门是否打开)进行导航和交互;智能家居系统可以根据设备的状态(如灯是否打开)进行自动控制。该基准的提出将促进视觉-语言模型在对象状态理解方面的研究进展,提升相关应用的智能化水平。
📄 摘要(原文)
Object state recognition aims to identify the specific condition of objects, such as their positional states (e.g., open or closed) and functional states (e.g., on or off). While recent Vision-Language Models (VLMs) are capable of performing a variety of multimodal tasks, it remains unclear how precisely they can identify object states. To alleviate this issue, we introduce the STAte and Transition UnderStanding Benchmark (STATUS Bench), the first benchmark for rigorously evaluating the ability of VLMs to understand subtle variations in object states in diverse situations. Specifically, STATUS Bench introduces a novel evaluation scheme that requires VLMs to perform three tasks simultaneously: object state identification (OSI), image retrieval (IR), and state change identification (SCI). These tasks are defined over our fully hand-crafted dataset involving image pairs, their corresponding object state descriptions and state change descriptions. Furthermore, we introduce a large-scale training dataset, namely STATUS Train, which consists of 13 million semi-automatically created descriptions. This dataset serves as the largest resource to facilitate further research in this area. In our experiments, we demonstrate that STATUS Bench enables rigorous consistency evaluation and reveal that current state-of-the-art VLMs still significantly struggle to capture subtle object state distinctions. Surprisingly, under the proposed rigorous evaluation scheme, most open-weight VLMs exhibited chance-level zero-shot performance. After fine-tuning on STATUS Train, Qwen2.5-VL achieved performance comparable to Gemini 2.0 Flash. These findings underscore the necessity of STATUS Bench and Train for advancing object state recognition in VLM research.