Single-Teacher View Augmentation: Boosting Knowledge Distillation via Angular Diversity
作者: Seonghoon Yu, Dongjun Nam, Dina Katabi, Jeany Son
分类: cs.CV, cs.AI
发布日期: 2025-10-26
备注: Accepted to NeurIPS 2025
💡 一句话要点
提出基于单教师视角增强的知识蒸馏方法,通过角度多样性提升学生模型性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 模型压缩 视角增强 角度多样性 单教师模型
📋 核心要点
- 现有知识蒸馏方法依赖多个教师网络以获得多样性,计算成本高昂,限制了其应用。
- 该论文提出单教师视角增强方法,通过角度多样性损失函数,从单教师网络生成多个视角。
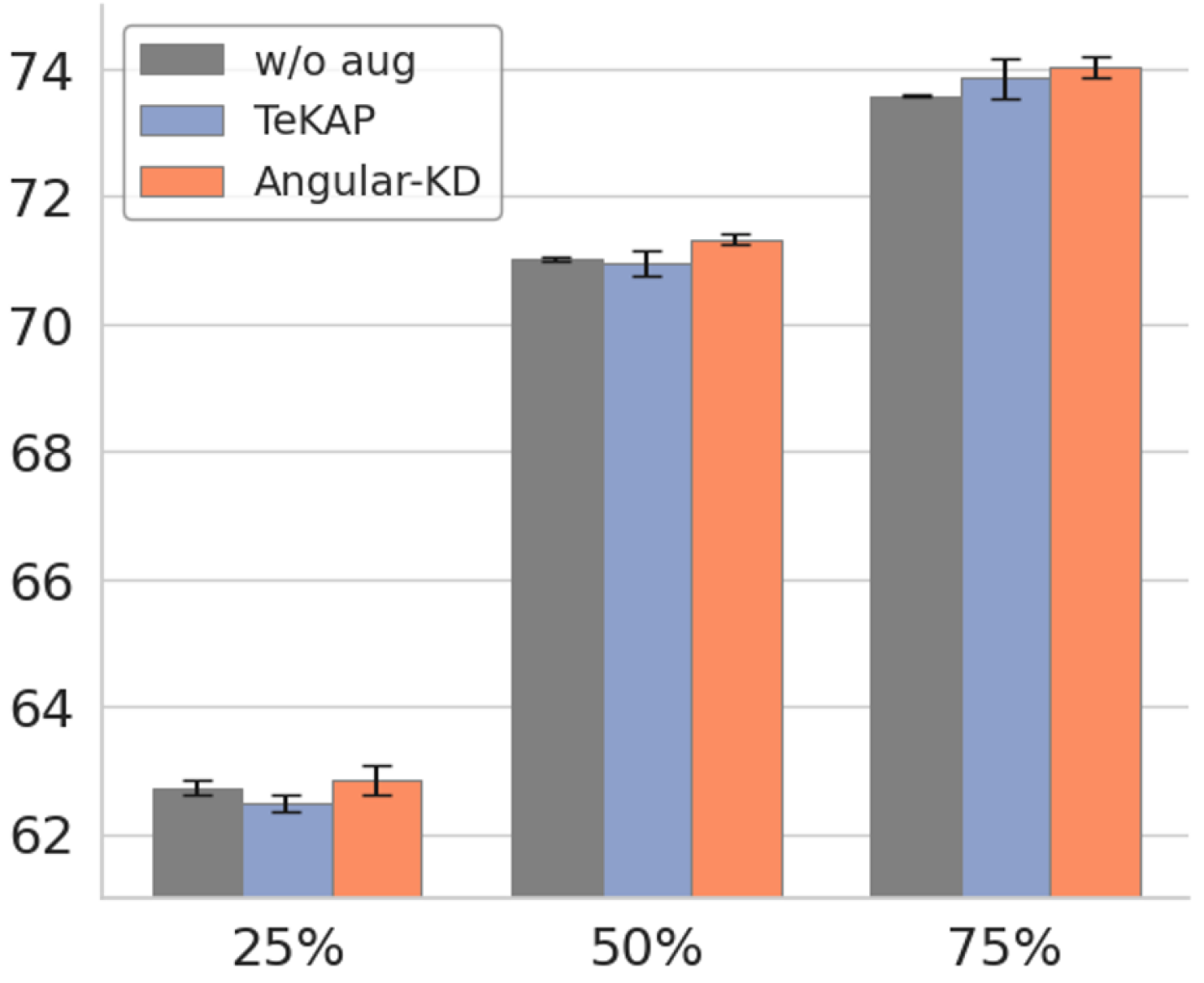
- 实验表明,该方法优于现有知识增强方法,且能与其他知识蒸馏框架兼容,提升泛化性能。
📝 摘要(中文)
知识蒸馏(KD)旨在通过从大型、高容量的教师模型中转移知识来训练轻量级的学生模型。最近的研究表明,利用多样化的教师视角可以显著提高蒸馏性能;然而,实现这种多样性通常需要多个教师网络,导致高昂的计算成本。本文提出了一种新颖的、具有成本效益的知识增强方法,用于KD,该方法通过将多个分支附加到单个教师来生成多样化的多视角。为了确保多视角之间有意义的语义变化,我们引入了两个角度多样性目标:1)约束的视角间多样性损失,它最大化增强视角之间的角度,同时保持与原始教师输出的接近度;2)视角内多样性损失,它鼓励视角围绕原始输出均匀分布。来自这些角度多样化视角的集成知识,以及原始教师的知识,被提炼到学生模型中。我们进一步从理论上证明,我们的目标增加了集成成员之间的多样性,从而降低了集成预期损失的上限,从而实现更有效的蒸馏。实验结果表明,我们的方法在不同的配置中超越了现有的知识增强方法。此外,所提出的方法可以即插即用地与其他KD框架兼容,从而在泛化性能方面提供一致的改进。
🔬 方法详解
问题定义:知识蒸馏旨在将大型教师模型的知识迁移到小型学生模型,但现有方法通常需要多个教师模型来获得多样化的知识,这导致了巨大的计算开销。因此,如何在计算资源有限的情况下,有效地利用知识蒸馏成为一个挑战。
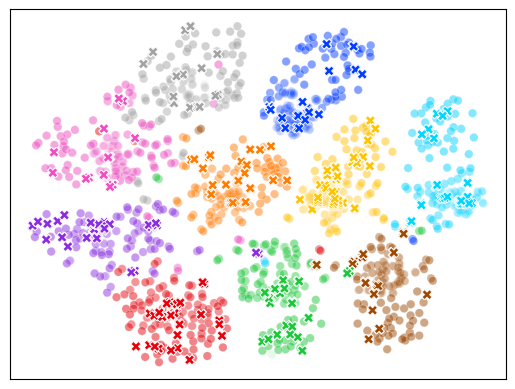
核心思路:该论文的核心思路是通过对单个教师模型进行视角增强,生成多个具有角度多样性的视角,从而模拟多个教师模型的效果。通过约束不同视角之间的角度,以及视角在原始输出周围的分布,来保证视角的多样性和信息量。
技术框架:该方法首先在单个教师模型上添加多个分支,每个分支代表一个不同的视角。然后,通过两个角度多样性损失函数来训练这些分支:约束的视角间多样性损失和视角内多样性损失。最后,将这些视角以及原始教师模型的输出集成起来,用于训练学生模型。
关键创新:该论文的关键创新在于提出了角度多样性损失函数,它能够有效地控制不同视角之间的角度,并保证视角在原始输出周围的均匀分布。这种方法避免了使用多个教师模型,从而大大降低了计算成本。
关键设计:约束的视角间多样性损失旨在最大化不同视角之间的角度,同时保持与原始教师输出的接近度。具体来说,它通过计算不同视角输出之间的余弦相似度,并将其作为损失函数的一部分。视角内多样性损失旨在鼓励视角围绕原始输出均匀分布。它通过计算每个视角与原始输出之间的角度,并将其作为损失函数的一部分。此外,论文还从理论上证明了这些损失函数能够降低集成预期损失的上限。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在多个数据集和模型架构上都优于现有的知识增强方法。例如,在ImageNet数据集上,该方法可以将ResNet-18学生模型的准确率提高超过2个百分点。此外,该方法还可以与其他知识蒸馏框架兼容,进一步提升性能。
🎯 应用场景
该研究成果可应用于各种需要模型轻量化和加速的场景,例如移动设备上的图像识别、自动驾驶中的目标检测等。通过单教师视角增强,可以在计算资源有限的情况下,有效地提升学生模型的性能,具有广泛的应用前景。
📄 摘要(原文)
Knowledge Distillation (KD) aims to train a lightweight student model by transferring knowledge from a large, high-capacity teacher. Recent studies have shown that leveraging diverse teacher perspectives can significantly improve distillation performance; however, achieving such diversity typically requires multiple teacher networks, leading to high computational costs. In this work, we propose a novel cost-efficient knowledge augmentation method for KD that generates diverse multi-views by attaching multiple branches to a single teacher. To ensure meaningful semantic variation across multi-views, we introduce two angular diversity objectives: 1) constrained inter-angle diversify loss, which maximizes angles between augmented views while preserving proximity to the original teacher output, and 2) intra-angle diversify loss, which encourages an even distribution of views around the original output. The ensembled knowledge from these angularly diverse views, along with the original teacher, is distilled into the student. We further theoretically demonstrate that our objectives increase the diversity among ensemble members and thereby reduce the upper bound of the ensemble's expected loss, leading to more effective distillation. Experimental results show that our method surpasses an existing knowledge augmentation method across diverse configurations. Moreover, the proposed method is compatible with other KD frameworks in a plug-and-play fashion, providing consistent improvements in generalization performance.