DynaPose4D: High-Quality 4D Dynamic Content Generation via Pose Alignment Loss
作者: Jing Yang, Yufeng Yang
分类: cs.CV, cs.AI
发布日期: 2025-10-26
💡 一句话要点
DynaPose4D:通过姿态对齐损失生成高质量4D动态内容
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 4D动态内容生成 高斯溅射 姿态估计 单图像重建 运动一致性
📋 核心要点
- 现有方法难以从单张图像生成高质量4D动态内容,尤其是在建模时间依赖性和捕获动态几何变化方面存在挑战。
- DynaPose4D通过集成4D高斯溅射和类别无关姿态估计技术,从单张图像构建3D模型并预测多视角姿态,从而生成动态内容。
- 实验结果表明,DynaPose4D在动态运动生成中实现了出色的连贯性、一致性和流畅性,验证了该框架的有效性。
📝 摘要(中文)
本文提出DynaPose4D,一种用于从单张静态图像生成高质量4D动态内容的创新解决方案。现有方法在建模时间依赖性和准确捕获动态几何变化方面存在局限性,尤其是在考虑相机视角变化时。DynaPose4D集成了4D高斯溅射(4DGS)技术和类别无关姿态估计(CAPE)技术。该框架使用3D高斯溅射从单张图像构建3D模型,然后基于选定视角的单样本支持预测多视角姿态关键点,利用监督信号来增强运动一致性。实验结果表明,DynaPose4D在动态运动生成中实现了出色的连贯性、一致性和流畅性。这些发现验证了DynaPose4D框架的有效性,并表明其在计算机视觉和动画制作领域的潜在应用。
🔬 方法详解
问题定义:论文旨在解决从单张静态图像生成高质量4D动态内容的问题。现有方法,特别是基于2D或3D生成模型的方法,在处理时间依赖性、捕捉动态几何变化以及应对相机视角变化时存在局限性,导致生成的动态内容缺乏连贯性和真实感。
核心思路:论文的核心思路是将4D高斯溅射(4DGS)技术与类别无关姿态估计(CAPE)技术相结合。4DGS负责构建和渲染动态场景,而CAPE则用于估计不同视角的姿态关键点,从而实现运动的连贯性。通过姿态对齐损失,可以约束不同视角下的运动一致性,从而生成更真实的动态内容。
技术框架:DynaPose4D框架主要包含以下几个阶段:1) 使用3D高斯溅射从单张图像构建3D模型;2) 基于选定视角的单样本支持,利用CAPE预测多视角姿态关键点;3) 使用姿态对齐损失来增强运动一致性;4) 使用4DGS渲染最终的动态内容。整个框架通过端到端的方式进行训练。
关键创新:该论文的关键创新在于将4DGS和CAPE技术结合,并引入姿态对齐损失。这种结合使得模型能够从单张图像中学习到动态场景的几何和运动信息,并生成高质量的4D动态内容。姿态对齐损失是保证不同视角下运动一致性的关键。
关键设计:在具体实现上,论文可能采用了以下关键设计:1) 使用预训练的CAPE模型来初始化姿态估计;2) 设计合适的姿态对齐损失函数,例如最小化不同视角下对应关键点之间的距离;3) 使用正则化项来约束4DGS的参数,防止过拟合;4) 采用多尺度训练策略,提高模型的泛化能力。具体的网络结构和参数设置在论文中应该有详细描述。
🖼️ 关键图片


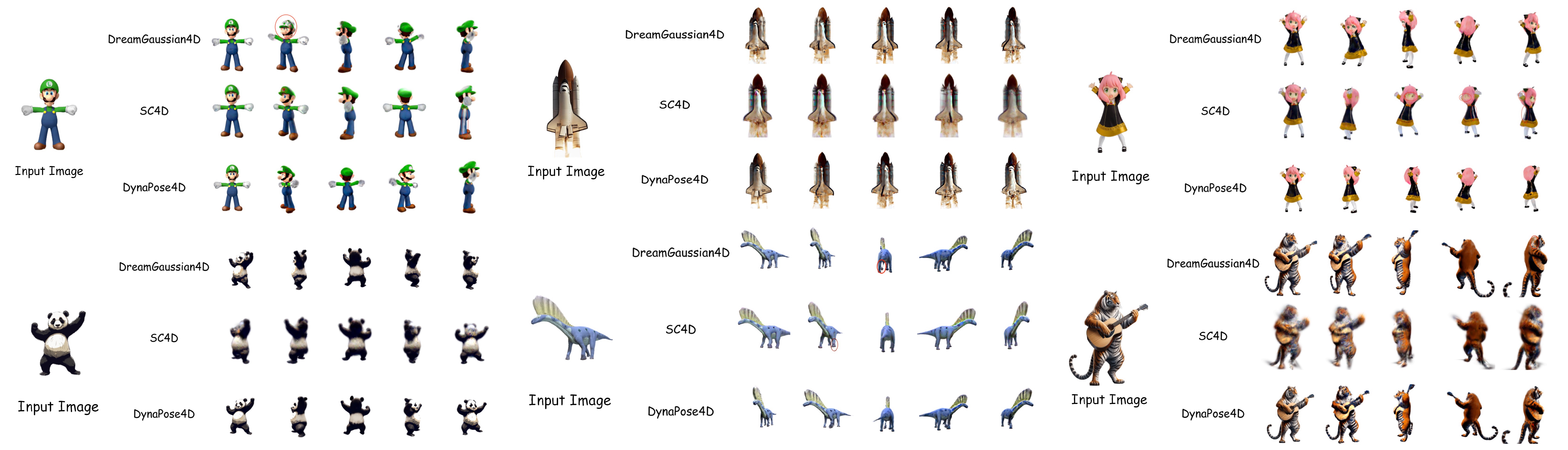
📊 实验亮点
实验结果表明,DynaPose4D在动态运动生成中实现了出色的连贯性、一致性和流畅性。与现有方法相比,DynaPose4D能够生成更真实的动态内容,并且能够更好地处理相机视角变化。具体的性能数据(例如,在特定指标上的提升幅度)需要在论文中查找。该研究验证了将4DGS和CAPE技术结合用于4D动态内容生成的有效性。
🎯 应用场景
DynaPose4D具有广泛的应用前景,包括:1) 虚拟现实和增强现实内容生成;2) 动画制作和游戏开发;3) 远程呈现和虚拟会议;4) 机器人控制和人机交互。该技术可以降低4D动态内容生成的成本和门槛,并为用户提供更加沉浸式的体验。未来,该技术有望应用于更多领域,例如自动驾驶和智能监控。
📄 摘要(原文)
Recent advancements in 2D and 3D generative models have expanded the capabilities of computer vision. However, generating high-quality 4D dynamic content from a single static image remains a significant challenge. Traditional methods have limitations in modeling temporal dependencies and accurately capturing dynamic geometry changes, especially when considering variations in camera perspective. To address this issue, we propose DynaPose4D, an innovative solution that integrates 4D Gaussian Splatting (4DGS) techniques with Category-Agnostic Pose Estimation (CAPE) technology. This framework uses 3D Gaussian Splatting to construct a 3D model from single images, then predicts multi-view pose keypoints based on one-shot support from a chosen view, leveraging supervisory signals to enhance motion consistency. Experimental results show that DynaPose4D achieves excellent coherence, consistency, and fluidity in dynamic motion generation. These findings not only validate the efficacy of the DynaPose4D framework but also indicate its potential applications in the domains of computer vision and animation production.