Cross-Enhanced Multimodal Fusion of Eye-Tracking and Facial Features for Alzheimer's Disease Diagnosis
作者: Yujie Nie, Jianzhang Ni, Yonglong Ye, Yuan-Ting Zhang, Yun Kwok Wing, Xiangqing Xu, Xin Ma, Lizhou Fan
分类: cs.CV, cs.AI, eess.IV
发布日期: 2025-10-25
备注: 35 pages, 8 figures, and 7 tables
💡 一句话要点
提出一种交叉增强多模态融合框架,用于眼动追踪和面部特征的阿尔茨海默病诊断。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 阿尔茨海默病诊断 多模态融合 眼动追踪 面部特征 交叉注意力 深度学习 方向感知卷积
📋 核心要点
- 现有方法在阿尔茨海默病诊断中,较少关注眼动追踪和面部特征的联合应用,未能充分利用多模态信息的互补性。
- 论文提出交叉增强多模态融合框架,通过交叉注意力和方向感知卷积,自适应地学习判别性的多模态表征。
- 实验结果表明,该框架在区分阿尔茨海默病患者和健康对照者方面,分类准确率达到95.11%,优于传统方法。
📝 摘要(中文)
阿尔茨海默病(AD)的准确诊断对于及时干预和延缓疾病进展至关重要。多模态诊断方法通过整合行为和感知领域的互补信息,展现出巨大的潜力。眼动追踪和面部特征是认知功能的重要指标,反映了注意力的分配和神经认知状态。然而,很少有研究探索它们在辅助AD诊断中的联合应用。本研究提出了一种多模态交叉增强融合框架,协同利用眼动追踪和面部特征进行AD检测。该框架包含两个关键模块:(a)交叉增强融合注意力模块(CEFAM),通过交叉注意力和全局增强来建模模态间的交互;(b)方向感知卷积模块(DACM),通过水平-垂直感受野捕获细粒度的方向性面部特征。这些模块共同实现了自适应和判别性的多模态表征学习。为了支持这项工作,我们构建了一个同步的多模态数据集,包括25名AD患者和25名健康对照者(HC),通过在视觉记忆搜索范式中记录对齐的面部视频和眼动追踪序列,为评估整合策略提供了一个生态有效的资源。在该数据集上的大量实验表明,我们的框架优于传统的后期融合和特征连接方法,在区分AD和HC方面实现了95.11%的分类准确率,突出了通过显式建模模态间依赖关系和模态特定贡献所带来的卓越鲁棒性和诊断性能。
🔬 方法详解
问题定义:阿尔茨海默病(AD)的早期诊断面临挑战,现有方法往往依赖于单一模态数据,忽略了不同模态信息之间的互补性。特别是,眼动追踪和面部特征作为认知功能的重要指标,其联合应用在AD诊断中潜力巨大,但缺乏有效的方法来整合这些信息。现有方法的痛点在于无法充分建模模态间的交互关系,以及提取具有判别性的模态特定特征。
核心思路:论文的核心思路是设计一种多模态交叉增强融合框架,通过显式建模眼动追踪和面部特征之间的交互关系,并提取具有方向感知能力的面部特征,从而实现更准确的AD诊断。该框架旨在克服传统方法中模态信息融合不足的问题,充分利用多模态数据的互补性。
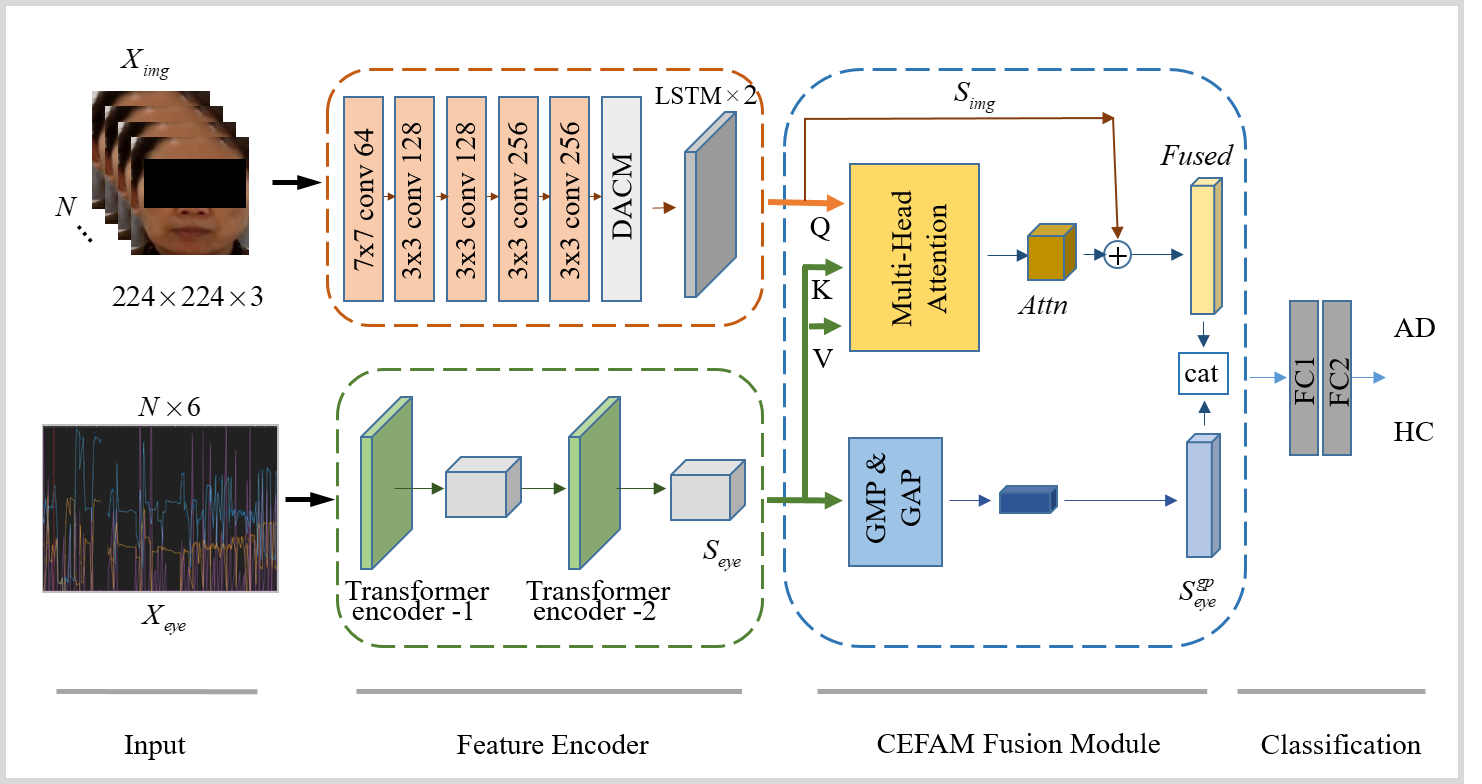
技术框架:该框架主要包含两个关键模块:交叉增强融合注意力模块(CEFAM)和方向感知卷积模块(DACM)。首先,CEFAM通过交叉注意力机制建模眼动追踪和面部特征之间的交互关系,并利用全局增强策略提升特征的表达能力。然后,DACM通过水平-垂直感受野捕获细粒度的方向性面部特征。最后,将两个模块提取的特征进行融合,用于AD的分类诊断。
关键创新:该论文的关键创新在于提出了CEFAM和DACM两个模块,分别用于建模模态间交互和提取方向感知面部特征。CEFAM通过交叉注意力机制,能够自适应地学习不同模态之间的依赖关系,从而实现更有效的模态融合。DACM通过水平-垂直感受野,能够捕获更细粒度的面部特征,从而提升诊断的准确性。与现有方法相比,该框架能够更充分地利用多模态信息,并提取更具判别性的特征。
关键设计:CEFAM中,交叉注意力机制的具体实现方式是使用Transformer中的自注意力机制,将眼动追踪和面部特征分别作为Query和Key/Value,计算它们之间的注意力权重。DACM中,水平-垂直感受野是通过设计特殊的卷积核实现的,这些卷积核能够分别提取水平和垂直方向上的特征。损失函数采用交叉熵损失函数,用于训练分类器。具体参数设置未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,提出的交叉增强多模态融合框架在阿尔茨海默病诊断中取得了显著的性能提升,分类准确率达到95.11%,优于传统的后期融合和特征连接方法。这表明该框架能够有效地利用眼动追踪和面部特征的互补信息,并提取具有判别性的特征,从而提升诊断的准确性。
🎯 应用场景
该研究成果可应用于阿尔茨海默病的早期辅助诊断,帮助医生更准确地识别高风险人群,从而进行及时的干预和治疗。此外,该方法也可推广到其他神经退行性疾病的诊断中,具有广阔的应用前景。未来,结合更多的生物标志物和临床数据,有望构建更完善的阿尔茨海默病诊断系统。
📄 摘要(原文)
Accurate diagnosis of Alzheimer's disease (AD) is essential for enabling timely intervention and slowing disease progression. Multimodal diagnostic approaches offer considerable promise by integrating complementary information across behavioral and perceptual domains. Eye-tracking and facial features, in particular, are important indicators of cognitive function, reflecting attentional distribution and neurocognitive state. However, few studies have explored their joint integration for auxiliary AD diagnosis. In this study, we propose a multimodal cross-enhanced fusion framework that synergistically leverages eye-tracking and facial features for AD detection. The framework incorporates two key modules: (a) a Cross-Enhanced Fusion Attention Module (CEFAM), which models inter-modal interactions through cross-attention and global enhancement, and (b) a Direction-Aware Convolution Module (DACM), which captures fine-grained directional facial features via horizontal-vertical receptive fields. Together, these modules enable adaptive and discriminative multimodal representation learning. To support this work, we constructed a synchronized multimodal dataset, including 25 patients with AD and 25 healthy controls (HC), by recording aligned facial video and eye-tracking sequences during a visual memory-search paradigm, providing an ecologically valid resource for evaluating integration strategies. Extensive experiments on this dataset demonstrate that our framework outperforms traditional late fusion and feature concatenation methods, achieving a classification accuracy of 95.11% in distinguishing AD from HC, highlighting superior robustness and diagnostic performance by explicitly modeling inter-modal dependencies and modality-specific contributions.