GRPO-Guard: Mitigating Implicit Over-Optimization in Flow Matching via Regulated Clipping
作者: Jing Wang, Jiajun Liang, Jie Liu, Henglin Liu, Gongye Liu, Jun Zheng, Wanyuan Pang, Ao Ma, Zhenyu Xie, Xintao Wang, Meng Wang, Pengfei Wan, Xiaodan Liang
分类: cs.CV, cs.LG
发布日期: 2025-10-25 (更新: 2025-10-30)
备注: Project Page: https://jingw193.github.io/GRPO-Guard/
💡 一句话要点
GRPO-Guard:通过调节裁剪缓解Flow Matching中的隐式过度优化
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Flow Matching 强化学习 过度优化 扩散模型 梯度裁剪 比率归一化 图像生成 文本到图像生成
📋 核心要点
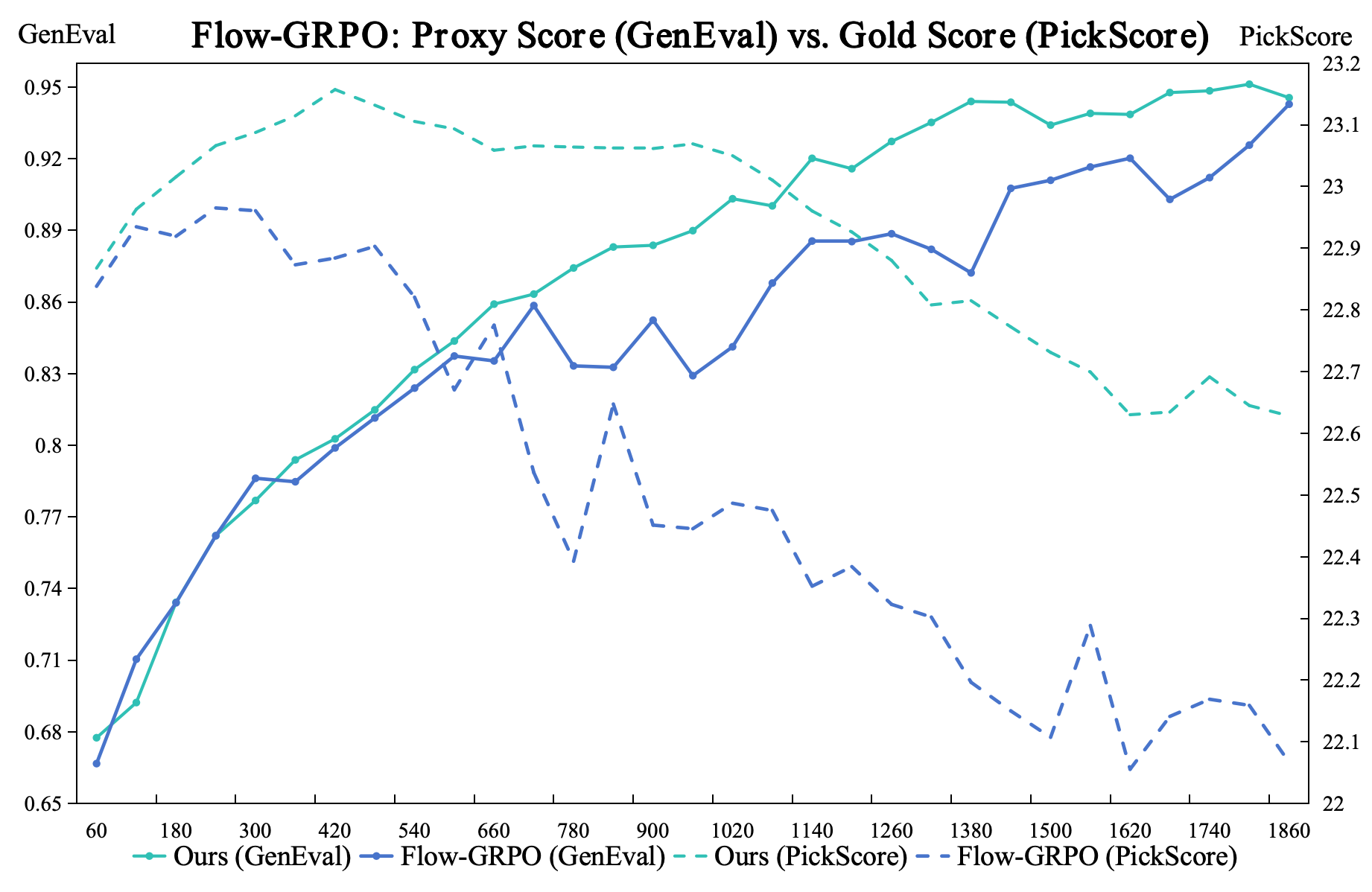
- 现有基于GRPO的Flow Matching方法存在隐式过度优化问题,导致图像质量和文本对齐等关键指标下降。
- GRPO-Guard通过比率归一化和梯度重加权,实现调节裁剪机制,稳定优化过程,缓解过度优化。
- 实验表明,GRPO-Guard在多个扩散模型和任务上,显著减少过度优化,并保持或提升生成质量。
📝 摘要(中文)
近年来,基于GRPO的强化学习在优化Flow Matching模型方面取得了显著进展,有效地提高了模型与特定任务奖励的对齐程度。在这些框架中,策略更新依赖于重要性比率裁剪来约束过度自信的正向和负向梯度。然而,在实践中,我们观察到重要性比率分布存在系统性偏移——其均值低于1,且方差在不同时间步长上差异显著。这种左移且不一致的分布阻止了正向优势样本进入裁剪区域,导致该机制无法约束过度自信的正向更新。因此,策略模型不可避免地进入隐式过度优化阶段——虽然代理奖励持续增加,但图像质量和文本提示对齐等关键指标急剧下降,最终导致学习到的策略在实际应用中变得不切实际。为了解决这个问题,我们引入了GRPO-Guard,这是对现有GRPO框架的一个简单而有效的增强。我们的方法结合了比率归一化,恢复了平衡且步长一致的重要性比率,确保PPO裁剪能够正确约束去噪时间步长上的有害更新。此外,梯度重加权策略均衡了噪声条件下的策略梯度,防止特定时间步长区域的过度更新。这些设计共同构成了一种调节裁剪机制,稳定了优化过程,并在不依赖于大量KL正则化的情况下,显著缓解了隐式过度优化。在多个扩散骨干网络(例如,SD3.5M,Flux.1-dev)和各种代理任务上的大量实验表明,GRPO-Guard显著减少了过度优化,同时保持甚至提高了生成质量。
🔬 方法详解
问题定义:论文旨在解决基于GRPO的Flow Matching模型训练过程中出现的隐式过度优化问题。现有方法依赖重要性比率裁剪来约束梯度更新,但实际中重要性比率分布存在偏移和不一致性,导致裁剪失效,模型在代理奖励提升的同时,图像质量等关键指标下降。
核心思路:论文的核心思路是通过调节裁剪机制,恢复重要性比率的平衡和一致性,并均衡不同噪声条件下的梯度更新,从而稳定优化过程,避免模型陷入隐式过度优化。
技术框架:GRPO-Guard是在现有GRPO框架上的增强,主要包含两个模块:比率归一化和梯度重加权。比率归一化用于恢复重要性比率的平衡和步长一致性,确保PPO裁剪有效约束有害更新。梯度重加权用于均衡不同噪声条件下的策略梯度,防止特定时间步长区域的过度更新。这两个模块共同作用,形成一个调节裁剪机制。
关键创新:论文的关键创新在于提出了一个调节裁剪机制,通过比率归一化和梯度重加权,解决了GRPO在Flow Matching中存在的隐式过度优化问题。与现有方法相比,GRPO-Guard不需要依赖大量的KL正则化,就能有效稳定优化过程,并提升生成质量。
关键设计:比率归一化通过对重要性比率进行标准化,使其均值接近1,方差在不同时间步长上保持一致。梯度重加权通过调整不同噪声条件下的梯度权重,使得策略梯度在各个时间步长上更加均衡。具体的参数设置和损失函数细节在论文中有详细描述,旨在平衡不同时间步长上的学习速率,防止某些区域的梯度主导整个训练过程。
🖼️ 关键图片


📊 实验亮点
实验结果表明,GRPO-Guard在SD3.5M和Flux.1-dev等多个扩散模型上,以及图像生成和文本到图像生成等任务上,均能显著减少过度优化,并保持甚至提高生成质量。例如,在某些任务上,GRPO-Guard能够在保持图像质量的同时,显著提高文本提示对齐度。
🎯 应用场景
该研究成果可应用于各种基于Flow Matching的生成模型训练,例如图像生成、文本到图像生成等。通过缓解隐式过度优化,可以提高生成模型的稳定性和生成质量,使其在实际应用中更具实用价值。未来,该方法可以进一步推广到其他强化学习优化生成模型的场景。
📄 摘要(原文)
Recently, GRPO-based reinforcement learning has shown remarkable progress in optimizing flow-matching models, effectively improving their alignment with task-specific rewards. Within these frameworks, the policy update relies on importance-ratio clipping to constrain overconfident positive and negative gradients. However, in practice, we observe a systematic shift in the importance-ratio distribution-its mean falls below 1 and its variance differs substantially across timesteps. This left-shifted and inconsistent distribution prevents positive-advantage samples from entering the clipped region, causing the mechanism to fail in constraining overconfident positive updates. As a result, the policy model inevitably enters an implicit over-optimization stage-while the proxy reward continues to increase, essential metrics such as image quality and text-prompt alignment deteriorate sharply, ultimately making the learned policy impractical for real-world use. To address this issue, we introduce GRPO-Guard, a simple yet effective enhancement to existing GRPO frameworks. Our method incorporates ratio normalization, which restores a balanced and step-consistent importance ratio, ensuring that PPO clipping properly constrains harmful updates across denoising timesteps. In addition, a gradient reweighting strategy equalizes policy gradients over noise conditions, preventing excessive updates from particular timestep regions. Together, these designs act as a regulated clipping mechanism, stabilizing optimization and substantially mitigating implicit over-optimization without relying on heavy KL regularization. Extensive experiments on multiple diffusion backbones (e.g., SD3.5M, Flux.1-dev) and diverse proxy tasks demonstrate that GRPO-Guard significantly reduces over-optimization while maintaining or even improving generation quality.