Accident Anticipation via Temporal Occurrence Prediction
作者: Tianhao Zhao, Yiyang Zou, Zihao Mao, Peilun Xiao, Yulin Huang, Hongda Yang, Yuxuan Li, Qun Li, Guobin Wu, Yutian Lin
分类: cs.CV
发布日期: 2025-10-25
备注: Accepted by NIPS 2025
💡 一句话要点
提出基于时间发生预测的事故预判方法,提升道路安全性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 事故预判 时间发生预测 Transformer 道路安全 高级驾驶辅助系统
📋 核心要点
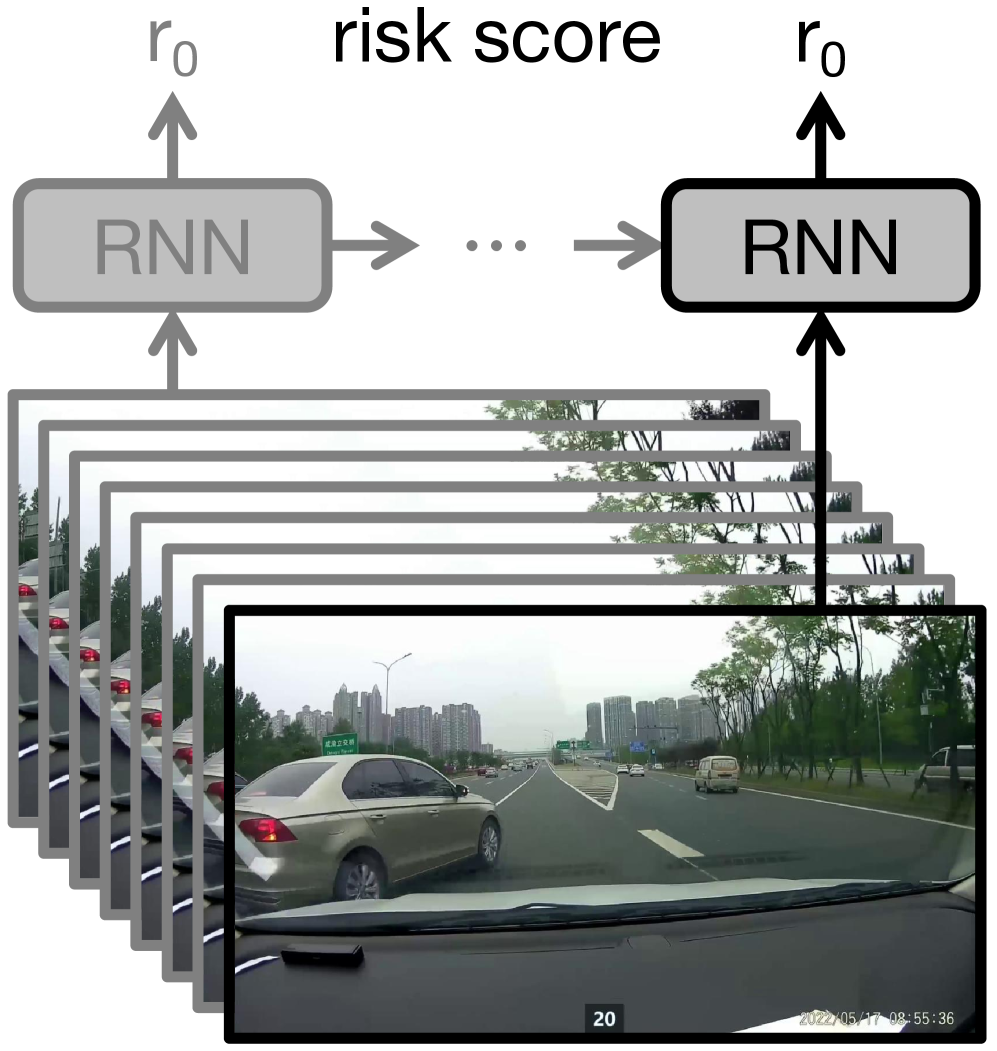
- 现有事故预判方法依赖模糊的二元监督,导致学习不稳定和误报率高。
- 提出一种新的预测范例,直接预测未来时间步的事故分数,利用精确的时间戳监督。
- 实验表明,该方法在实际误报率约束下,显著提升了召回率和事故发生时间预测精度。
📝 摘要(中文)
本文提出了一种新的事故预判方法,旨在在线预测潜在的碰撞,从而及时发出警报以提高道路安全性。现有方法通常预测帧级别的风险分数作为危险指标,但这些方法依赖于模糊的二元监督(将事故视频中的所有帧都标记为正样本),而实际上风险随时间连续变化,导致不可靠的学习和虚假警报。为了解决这个问题,我们提出了一种新的范例,将预测目标从当前帧风险评分转移到直接估计多个未来时间步(例如,提前0.1秒-2.0秒)的事故分数,利用精确标注的事故时间戳作为监督。我们的方法采用片段级别的编码器来联合建模空间和时间动态,以及一个基于Transformer的时间解码器,该解码器使用专用的时间查询同时预测所有未来范围的事故分数。此外,我们引入了一种改进的评估协议,仅当误报率(FAR)保持在可接受的范围内时,才报告事故发生时间(TTA)和召回率(在多个事故前间隔(0.5秒、1.0秒和1.5秒)评估),从而确保实际相关性。实验表明,我们的方法在实际的FAR约束下,在召回率和TTA方面都取得了优异的性能。
🔬 方法详解
问题定义:现有事故预判方法主要通过预测每一帧的风险得分来判断事故发生的可能性。然而,这些方法通常使用二元标签(事故视频的所有帧都标记为正样本),忽略了事故风险随时间变化的特性,导致模型学习到的风险评估不准确,容易产生误报。因此,如何利用更精确的监督信息,更准确地预测事故风险,是本文要解决的核心问题。
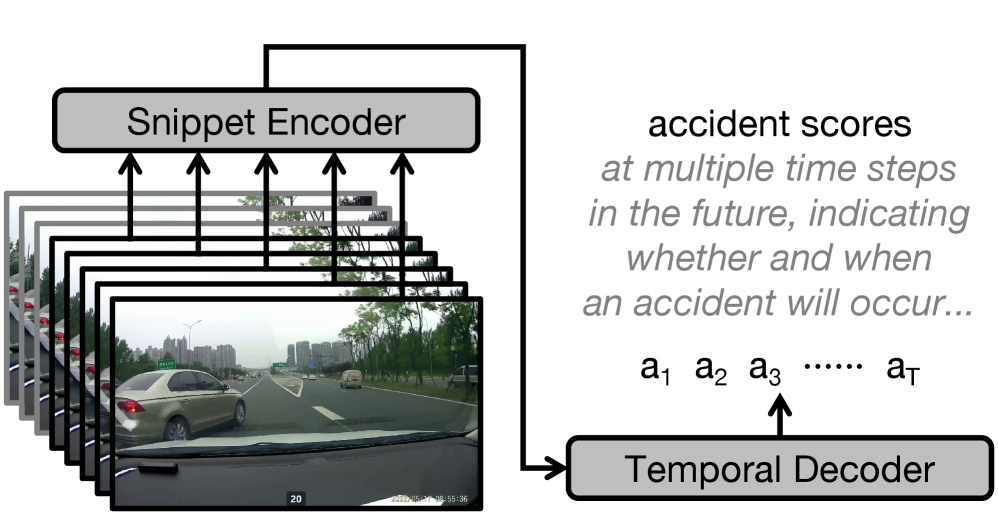
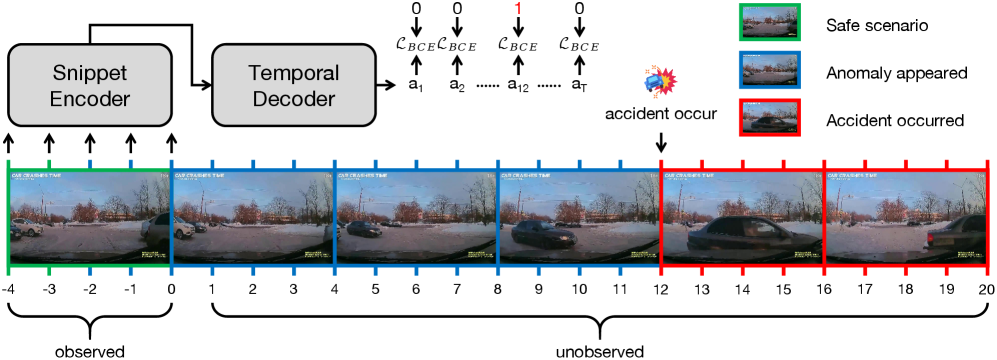
核心思路:本文的核心思路是将预测目标从当前帧的风险评分,转移到直接预测未来多个时间步的事故分数。通过利用精确标注的事故时间戳作为监督信号,模型可以直接学习到事故发生前不同时间段的风险变化模式。这种方法避免了模糊的二元监督带来的问题,能够更准确地评估事故风险。
技术框架:该方法主要包含两个核心模块:片段级别编码器和基于Transformer的时间解码器。首先,片段级别编码器用于联合建模视频片段中的空间和时间动态信息,提取视频特征。然后,基于Transformer的时间解码器利用编码器提取的特征,并使用专用的时间查询,同时预测所有未来时间范围的事故分数。整个框架采用端到端的方式进行训练。
关键创新:该方法最重要的创新点在于将预测目标从当前帧风险评分转移到未来时间步事故分数预测,并利用精确的事故时间戳作为监督信号。这种方法能够更准确地学习事故风险变化模式,避免了传统方法中模糊二元监督带来的问题。此外,使用Transformer解码器可以同时预测多个未来时间步的事故分数,提高了预测效率。
关键设计:在时间解码器中,使用了可学习的时间查询向量,每个查询向量对应一个特定的未来时间步。解码器的损失函数基于预测的事故分数和真实事故时间戳之间的差异进行计算。此外,论文还提出了一种改进的评估协议,在可接受的误报率范围内,评估事故发生时间(TTA)和召回率,从而更客观地评估方法的实际性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在实际误报率约束下,显著提升了事故预判的性能。具体来说,在改进的评估协议下,该方法在召回率和事故发生时间(TTA)方面均优于现有方法。例如,在特定误报率下,该方法可以将事故预警时间提前0.5秒以上,并显著提高召回率,表明该方法在实际应用中具有更高的可靠性和实用性。
🎯 应用场景
该研究成果可应用于高级驾驶辅助系统(ADAS)和自动驾驶系统中,通过提前预测潜在的交通事故风险,及时向驾驶员发出警告或采取干预措施,从而有效降低交通事故的发生率,提高道路交通安全。此外,该技术还可以应用于智能监控系统,用于检测和预警潜在的安全事故。
📄 摘要(原文)
Accident anticipation aims to predict potential collisions in an online manner, enabling timely alerts to enhance road safety. Existing methods typically predict frame-level risk scores as indicators of hazard. However, these approaches rely on ambiguous binary supervision (labeling all frames in accident videos as positive) despite the fact that risk varies continuously over time, leading to unreliable learning and false alarms. To address this, we propose a novel paradigm that shifts the prediction target from current-frame risk scoring to directly estimating accident scores at multiple future time steps (e.g., 0.1s-2.0s ahead), leveraging precisely annotated accident timestamps as supervision. Our method employs a snippet-level encoder to jointly model spatial and temporal dynamics, and a Transformer-based temporal decoder that predicts accident scores for all future horizons simultaneously using dedicated temporal queries. Furthermore, we introduce a refined evaluation protocol that reports Time-to-Accident (TTA) and recall (evaluated at multiple pre-accident intervals (0.5s, 1.0s, and 1.5s)) only when the false alarm rate (FAR) remains within an acceptable range, ensuring practical relevance. Experiments show that our method achieves superior performance in both recall and TTA under realistic FAR constraints.