LOC: A General Language-Guided Framework for Open-Set 3D Occupancy Prediction
作者: Yuhang Gao, Xiang Xiang, Sheng Zhong, Guoyou Wang
分类: cs.CV, cs.CL, cs.LG, cs.RO, eess.IV
发布日期: 2025-10-25
💡 一句话要点
LOC:一种通用的语言引导框架,用于开放集3D occupancy预测。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D occupancy预测 开放集识别 视觉-语言模型 密集对比学习 自监督学习 LiDAR点云 nuScenes数据集
📋 核心要点
- 现有3D场景理解方法在开放集场景下泛化能力不足,缺乏对未知类别的有效识别。
- LOC框架通过语言引导,融合多帧LiDAR信息,并利用密集对比学习缓解特征同质化,提升开放集识别能力。
- 在nuScenes数据集上的实验表明,LOC框架能够高精度预测已知类别,并有效区分未知类别,无需额外训练。
📝 摘要(中文)
视觉-语言模型(VLM)在开放集挑战中展现了显著的进展。然而,3D数据集的有限性阻碍了它们在3D场景理解中的有效应用。我们提出了LOC,一个通用的语言引导框架,可以适应各种occupancy网络,支持监督和自监督学习范式。对于自监督任务,我们采用了一种融合多帧LiDAR点云的策略,用于动态/静态场景,使用泊松重建来填充空隙,并通过K近邻(KNN)为体素分配语义,以获得全面的体素表示。为了缓解直接高维特征蒸馏引起的特征过度同质化,我们引入了密集对比学习(DCL)。DCL利用密集体素语义信息和预定义的文本提示。这有效地增强了开放集识别,而无需密集的像素级监督,并且我们的框架还可以利用现有的ground truth来进一步提高性能。我们的模型预测嵌入在CLIP特征空间中的密集体素特征,整合文本和图像像素信息,并基于文本和语义相似性进行分类。在nuScenes数据集上的实验证明了该方法的优越性能,实现了已知类的高精度预测,并区分了未知类,而无需额外的训练数据。
🔬 方法详解
问题定义:现有的3D occupancy预测方法在处理开放集场景时面临挑战,即模型难以泛化到训练集中未见过的类别。这些方法通常依赖于封闭集假设,无法有效识别和区分未知物体,导致预测精度下降。此外,直接使用高维特征蒸馏容易导致特征过度同质化,降低模型的判别能力。
核心思路:LOC框架的核心思路是利用视觉-语言模型(VLM)的强大语义理解能力,通过语言引导的方式提升3D occupancy预测在开放集场景下的性能。该框架通过融合多帧LiDAR信息构建更完整的场景表示,并引入密集对比学习(DCL)来缓解特征同质化问题,从而提高模型对未知类别的识别能力。
技术框架:LOC框架包含以下主要模块:1)多帧LiDAR融合模块,用于整合多帧点云数据,并通过泊松重建填充空隙;2)语义分配模块,利用KNN算法为体素分配语义标签;3)特征蒸馏模块,将教师模型的知识迁移到学生模型;4)密集对比学习(DCL)模块,通过对比学习增强特征的判别性;5)预测模块,基于CLIP特征空间中的体素特征,结合文本和图像信息进行分类。
关键创新:LOC框架的关键创新在于:1)提出了一种通用的语言引导框架,可以适应各种occupancy网络;2)引入了密集对比学习(DCL),有效缓解了特征过度同质化问题,提升了开放集识别能力;3)采用自监督学习范式,利用多帧LiDAR信息和泊松重建构建训练数据,降低了对标注数据的依赖。
关键设计:在密集对比学习(DCL)中,使用了预定义的文本提示来引导特征学习。损失函数的设计包括对比损失和交叉熵损失,用于优化特征表示和分类性能。KNN算法中K值的选择会影响语义分配的准确性,需要根据具体数据集进行调整。网络结构方面,使用了基于体素的3D卷积神经网络进行特征提取和预测。
🖼️ 关键图片
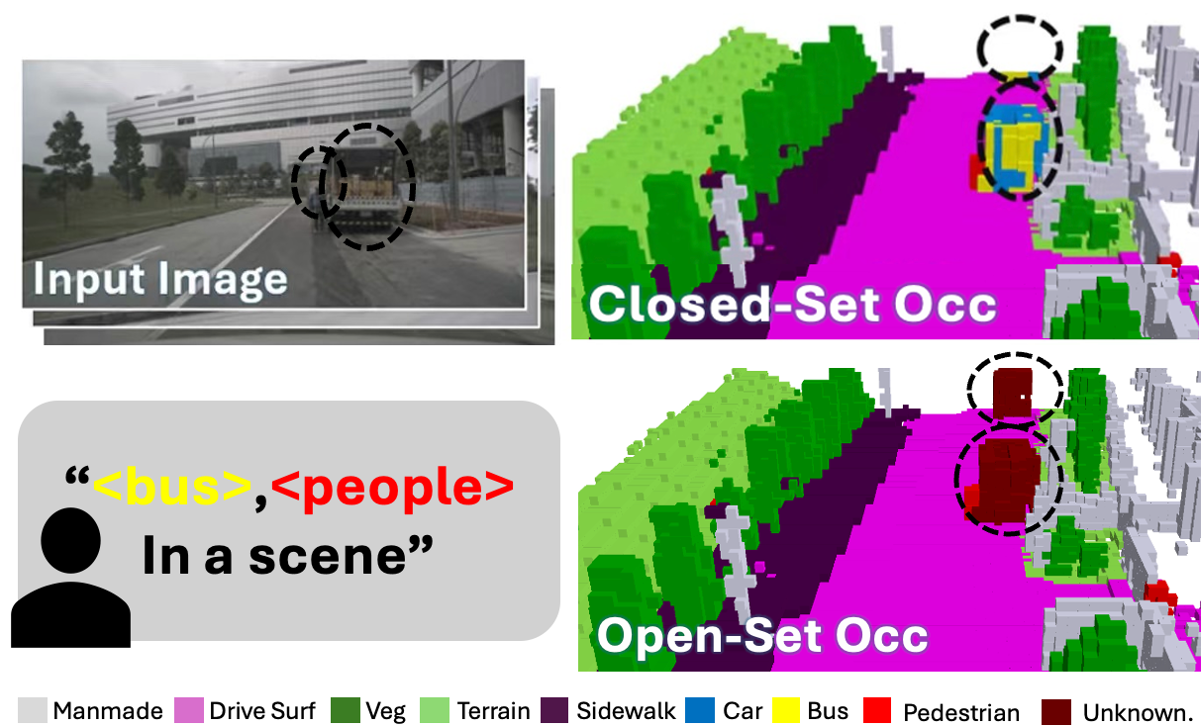
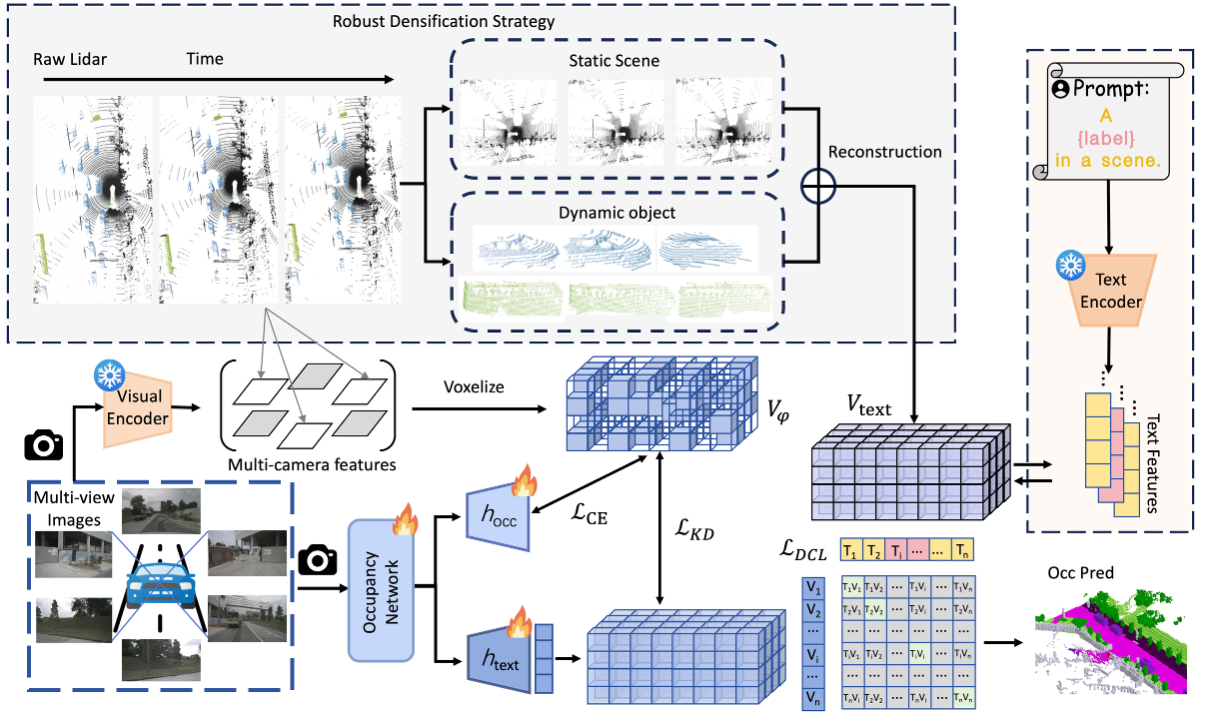

📊 实验亮点
LOC框架在nuScenes数据集上取得了显著的性能提升。实验结果表明,该方法能够以高精度预测已知类别,并有效区分未知类别,而无需额外的训练数据。与现有方法相比,LOC框架在开放集识别方面具有更强的泛化能力和鲁棒性。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、增强现实等领域。在自动驾驶中,该方法可以提高车辆对复杂环境中未知物体的识别能力,从而提升驾驶安全性。在机器人导航中,该方法可以帮助机器人更好地理解周围环境,实现更智能的路径规划和避障。在增强现实中,该方法可以用于构建更逼真的3D场景,提升用户体验。
📄 摘要(原文)
Vision-Language Models (VLMs) have shown significant progress in open-set challenges. However, the limited availability of 3D datasets hinders their effective application in 3D scene understanding. We propose LOC, a general language-guided framework adaptable to various occupancy networks, supporting both supervised and self-supervised learning paradigms. For self-supervised tasks, we employ a strategy that fuses multi-frame LiDAR points for dynamic/static scenes, using Poisson reconstruction to fill voids, and assigning semantics to voxels via K-Nearest Neighbor (KNN) to obtain comprehensive voxel representations. To mitigate feature over-homogenization caused by direct high-dimensional feature distillation, we introduce Densely Contrastive Learning (DCL). DCL leverages dense voxel semantic information and predefined textual prompts. This efficiently enhances open-set recognition without dense pixel-level supervision, and our framework can also leverage existing ground truth to further improve performance. Our model predicts dense voxel features embedded in the CLIP feature space, integrating textual and image pixel information, and classifies based on text and semantic similarity. Experiments on the nuScenes dataset demonstrate the method's superior performance, achieving high-precision predictions for known classes and distinguishing unknown classes without additional training data.