STG-Avatar: Animatable Human Avatars via Spacetime Gaussian
作者: Guangan Jiang, Tianzi Zhang, Dong Li, Zhenjun Zhao, Haoang Li, Mingrui Li, Hongyu Wang
分类: cs.CV
发布日期: 2025-10-25
备注: Accepted by the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2025
🔗 代码/项目: GITHUB
💡 一句话要点
STG-Avatar:基于时空高斯的动画人体化身,提升非刚性和动态区域重建质量
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 人体化身 3D高斯 时空高斯 线性混合蒙皮 非刚性形变 光流估计 单目重建
📋 核心要点
- 现有基于3DGS的人体化身方法难以准确表示非刚性物体的细节形变和动态区域的快速运动。
- STG-Avatar采用刚性-非刚性耦合形变框架,结合LBS的骨骼控制和STG的时空自适应优化。
- 实验表明,STG-Avatar在重建质量和效率上优于现有方法,并保持了实时渲染能力。
📝 摘要(中文)
本文提出STG-Avatar,一个基于3D高斯(3DGS)的高保真可动画人体化身重建框架,旨在解决单目视频重建中非刚性物体(如服装形变)和动态区域(如快速移动的肢体)细节捕捉不足的问题。该框架引入刚性-非刚性耦合形变机制,将时空高斯(STG)与线性混合蒙皮(LBS)相结合。LBS通过驱动全局姿态变换实现实时骨骼控制,STG通过时空自适应优化3D高斯进行补充。此外,利用光流识别高动态区域,并指导这些区域中3D高斯的自适应密集化。实验结果表明,该方法在重建质量和运算效率方面均优于现有技术,在保持实时渲染能力的同时,实现了卓越的量化指标。
🔬 方法详解
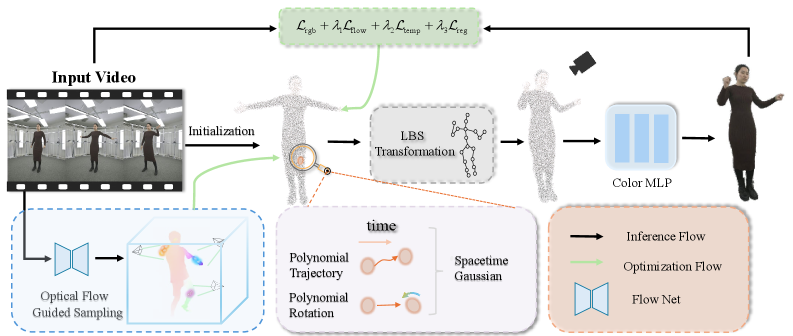
问题定义:现有基于单目视频的人体化身重建方法,尤其是在基于3D高斯表示的方法中,难以准确捕捉非刚性物体(如服装)的复杂形变以及动态区域(如快速运动的肢体)的细节。这些方法通常在处理快速运动或复杂形变时,会出现重建质量下降或渲染伪影的问题。
核心思路:STG-Avatar的核心思路是将传统的线性混合蒙皮(LBS)与时空高斯(STG)表示相结合,形成一种刚性-非刚性耦合的形变框架。LBS负责处理全局的骨骼运动和姿态变换,而STG则负责捕捉局部、非刚性的形变细节。通过这种混合表示,可以充分利用LBS的实时性和STG的细节捕捉能力。
技术框架:STG-Avatar的整体框架包括以下几个主要模块:1) 基于单目视频的输入,提取人体骨骼姿态;2) 使用LBS将3D高斯进行初步的姿态变换;3) 引入时空高斯(STG),通过优化3D高斯的位置、形状和颜色等参数,来精细化重建结果,捕捉非刚性形变;4) 利用光流信息检测高动态区域,并在这些区域自适应地增加3D高斯的密度,以提升重建质量。
关键创新:STG-Avatar的关键创新在于刚性-非刚性耦合形变框架,以及基于光流引导的自适应高斯密集化策略。与完全依赖LBS或完全依赖神经隐式表示的方法不同,STG-Avatar将两者优势结合,实现了更高效、更精确的人体化身重建。光流引导的自适应密集化则针对性地提升了动态区域的重建质量。
关键设计:在STG-Avatar中,关键的设计包括:1) STG的参数化方式,如何有效地表示时空信息;2) LBS和STG之间的融合策略,如何平衡两者的贡献;3) 光流信息的提取和利用方式,如何准确地检测高动态区域;4) 损失函数的设计,如何引导3D高斯的优化,使其更好地拟合目标人体。
🖼️ 关键图片


📊 实验亮点
实验结果表明,STG-Avatar在重建质量和运算效率方面均优于现有技术。在定量指标上,STG-Avatar相较于其他SOTA方法取得了显著提升(具体数值未知,需参考论文原文)。同时,STG-Avatar保持了实时渲染能力,能够在保证重建质量的同时,实现流畅的交互体验。此外,消融实验验证了刚性-非刚性耦合形变框架和光流引导的自适应密集化策略的有效性。
🎯 应用场景
STG-Avatar在人机交互、虚拟现实/增强现实、数字内容创作等领域具有广泛的应用前景。它可以用于创建高度逼真、可交互的虚拟化身,提升用户的沉浸式体验。此外,该技术还可以应用于远程协作、虚拟会议、游戏开发等场景,为用户提供更加自然、高效的交互方式。未来,该技术有望进一步发展,实现更加智能化、个性化的虚拟化身定制。
📄 摘要(原文)
Realistic animatable human avatars from monocular videos are crucial for advancing human-robot interaction and enhancing immersive virtual experiences. While recent research on 3DGS-based human avatars has made progress, it still struggles with accurately representing detailed features of non-rigid objects (e.g., clothing deformations) and dynamic regions (e.g., rapidly moving limbs). To address these challenges, we present STG-Avatar, a 3DGS-based framework for high-fidelity animatable human avatar reconstruction. Specifically, our framework introduces a rigid-nonrigid coupled deformation framework that synergistically integrates Spacetime Gaussians (STG) with linear blend skinning (LBS). In this hybrid design, LBS enables real-time skeletal control by driving global pose transformations, while STG complements it through spacetime adaptive optimization of 3D Gaussians. Furthermore, we employ optical flow to identify high-dynamic regions and guide the adaptive densification of 3D Gaussians in these regions. Experimental results demonstrate that our method consistently outperforms state-of-the-art baselines in both reconstruction quality and operational efficiency, achieving superior quantitative metrics while retaining real-time rendering capabilities. Our code is available at https://github.com/jiangguangan/STG-Avatar