CogStereo: Neural Stereo Matching with Implicit Spatial Cognition Embedding
作者: Lihuang Fang, Xiao Hu, Yuchen Zou, Hong Zhang
分类: cs.CV
发布日期: 2025-10-25
备注: 9 pages, 6 figures
💡 一句话要点
CogStereo:利用隐式空间认知嵌入的神经立体匹配,提升零样本泛化能力。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 立体匹配 深度估计 空间认知 神经网络 跨域泛化
📋 核心要点
- 现有深度立体匹配方法依赖数据集微调,泛化能力不足,难以处理遮挡、弱纹理等复杂区域。
- CogStereo通过单目深度特征嵌入隐式空间认知,作为先验指导视差估计,提升场景理解的全局一致性。
- 实验表明,CogStereo在多个数据集上达到SOTA,并在跨域泛化方面表现优异,验证了其有效性。
📝 摘要(中文)
深度立体匹配在基准数据集上通过微调取得了显著进展,但在零样本泛化方面不如其他视觉任务中的基础模型。本文提出了CogStereo,一种新颖的框架,旨在解决诸如遮挡或弱纹理等具有挑战性的区域,而无需依赖于数据集特定的先验知识。CogStereo通过使用单目深度特征作为先验,将隐式空间认知嵌入到细化过程中,从而捕获超越局部对应关系的整体场景理解。这种方法确保了结构连贯的视差估计,即使在仅靠几何信息不足的区域也是如此。CogStereo采用双条件细化机制,将像素级不确定性与认知引导的特征相结合,以实现对不匹配的全局一致性校正。在Scene Flow、KITTI、Middlebury、ETH3D、EuRoc和真实世界等数据集上的大量实验表明,CogStereo不仅实现了最先进的结果,而且在跨域泛化方面表现出色,从而将立体视觉推向了认知驱动的方法。
🔬 方法详解
问题定义:现有深度立体匹配方法在处理遮挡、弱纹理等复杂场景时,依赖于数据集特定的先验知识,导致泛化能力较差。尤其是在零样本场景下,性能会显著下降。因此,如何提升深度立体匹配模型的跨域泛化能力,使其能够适应各种复杂场景,是本文要解决的核心问题。
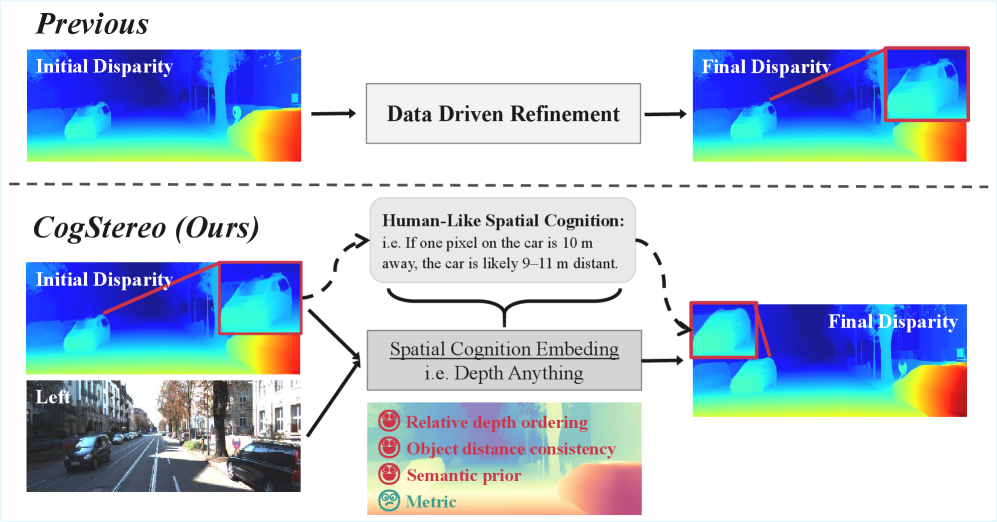
核心思路:CogStereo的核心思路是将隐式空间认知嵌入到立体匹配的细化过程中。具体来说,利用单目深度估计作为先验知识,指导视差估计,从而在缺乏纹理或存在遮挡的区域也能获得结构一致的视差图。这种方法模拟了人类视觉系统对场景的整体理解能力,而不仅仅依赖于局部像素的对应关系。
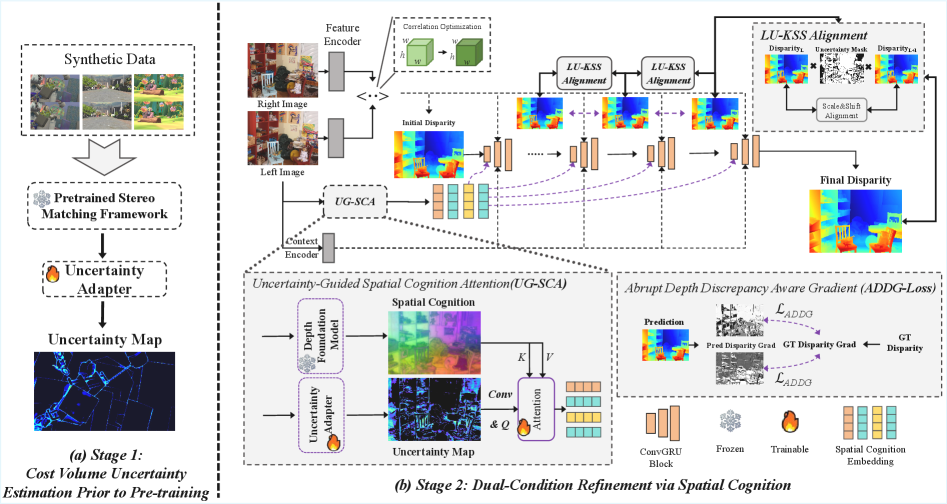
技术框架:CogStereo的整体框架包含以下几个主要模块:1) 特征提取模块:提取左右图像的特征。2) 代价体构建模块:基于特征计算左右图像之间的匹配代价。3) 初始视差估计模块:根据代价体估计初始视差图。4) 双条件细化模块:这是CogStereo的核心模块,利用单目深度特征和像素级不确定性信息,对初始视差图进行全局一致性校正。
关键创新:CogStereo的关键创新在于引入了隐式空间认知嵌入,通过单目深度特征作为先验,指导视差估计的细化过程。这种方法使得模型能够捕获场景的整体结构信息,从而在遮挡、弱纹理等复杂区域也能获得准确的视差估计。与现有方法相比,CogStereo不再仅仅依赖于局部像素的对应关系,而是结合了全局的场景理解,从而提升了模型的泛化能力。
关键设计:CogStereo采用了双条件细化机制,该机制结合了像素级不确定性与认知引导的特征。像素级不确定性用于衡量初始视差估计的可靠程度,认知引导的特征则来自于单目深度估计,用于提供场景的结构信息。通过将这两种信息结合起来,CogStereo能够对初始视差图进行全局一致性校正,从而获得更准确的视差估计。具体的网络结构和损失函数细节在论文中进行了详细描述,但摘要中未提供。
🖼️ 关键图片

📊 实验亮点
CogStereo在Scene Flow、KITTI、Middlebury、ETH3D、EuRoc等多个数据集上取得了state-of-the-art的结果,并在跨域泛化方面表现出色。具体性能数据和对比基线在摘要中未给出,但强调了其在多个数据集上的优越性,证明了其有效性和泛化能力。
🎯 应用场景
CogStereo在自动驾驶、机器人导航、三维重建等领域具有广泛的应用前景。其强大的跨域泛化能力使得它能够适应各种复杂的真实场景,例如城市街道、室内环境等。通过提供准确的深度信息,CogStereo可以帮助自动驾驶系统更好地感知周围环境,从而做出更安全、更可靠的决策。在机器人导航领域,CogStereo可以帮助机器人构建环境地图,实现自主导航。在三维重建领域,CogStereo可以用于生成高质量的三维模型。
📄 摘要(原文)
Deep stereo matching has advanced significantly on benchmark datasets through fine-tuning but falls short of the zero-shot generalization seen in foundation models in other vision tasks. We introduce CogStereo, a novel framework that addresses challenging regions, such as occlusions or weak textures, without relying on dataset-specific priors. CogStereo embeds implicit spatial cognition into the refinement process by using monocular depth features as priors, capturing holistic scene understanding beyond local correspondences. This approach ensures structurally coherent disparity estimation, even in areas where geometry alone is inadequate. CogStereo employs a dual-conditional refinement mechanism that combines pixel-wise uncertainty with cognition-guided features for consistent global correction of mismatches. Extensive experiments on Scene Flow, KITTI, Middlebury, ETH3D, EuRoc, and real-world demonstrate that CogStereo not only achieves state-of-the-art results but also excels in cross-domain generalization, shifting stereo vision towards a cognition-driven approach.