GRAID: Enhancing Spatial Reasoning of VLMs Through High-Fidelity Data Generation
作者: Karim Elmaaroufi, Liheng Lai, Justin Svegliato, Yutong Bai, Sanjit A. Seshia, Matei Zaharia
分类: cs.CV, cs.AI
发布日期: 2025-10-25 (更新: 2025-10-28)
备注: 22 pages, 3 figures, 3 tables, project page: https://ke7.github.io/graid/
💡 一句话要点
GRAID:通过高质量数据生成增强视觉语言模型空间推理能力
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting)
关键词: 视觉语言模型 空间推理 数据生成 VQA 2D几何 目标检测 人工验证
📋 核心要点
- 现有视觉语言模型在空间推理方面存在不足,限制了其在许多实际应用中的潜力。
- GRAID利用2D几何基元生成高质量VQA数据,避免了3D重建误差和生成幻觉问题。
- 实验表明,使用GRAID生成的数据训练的模型在空间推理任务上取得了显著的性能提升,并具有良好的泛化能力。
📝 摘要(中文)
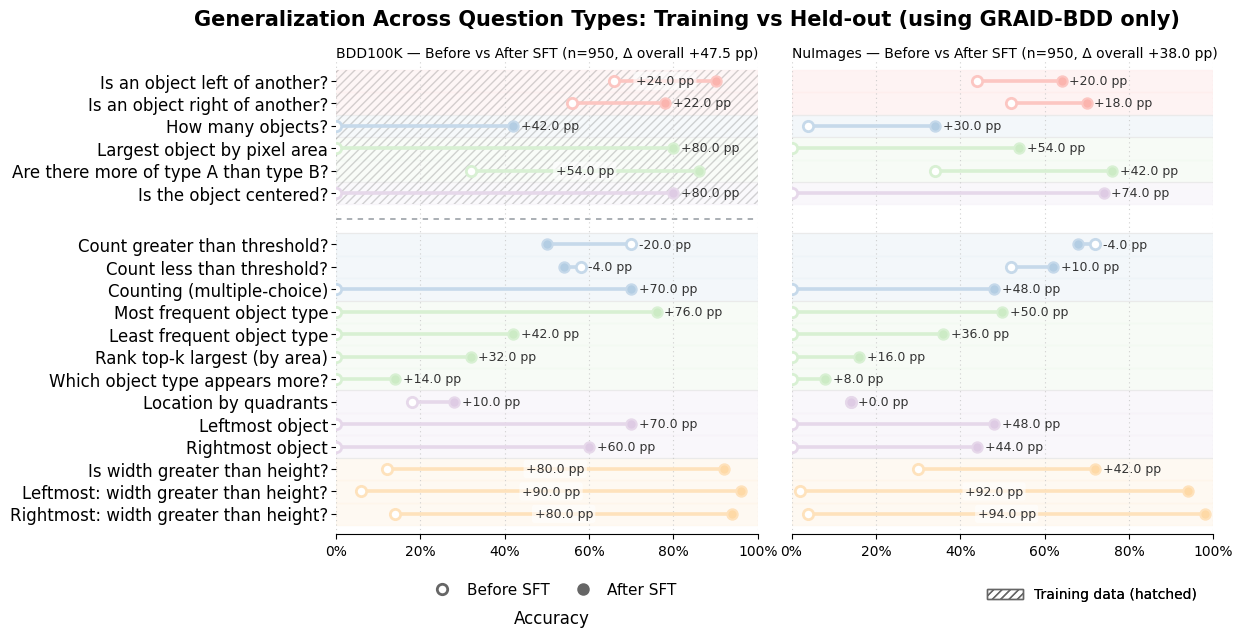
视觉语言模型(VLMs)在许多视觉-语言任务上表现出色,但常常在空间推理方面遇到困难,而空间推理是许多应用的前提。实证研究表明,当前训练数据生成流程产生的数据集的人工验证率仅为57.6%。这种低验证率源于现有方法的局限性:单图像3D重建引入了级联建模误差,需要较大的答案容差;而基于字幕的方法需要超详细的标注,并容易产生生成幻觉。我们提出了GRAID,其核心思想是定性的空间关系可以仅从2D几何基元可靠地确定。通过仅操作来自标准目标检测器的2D边界框,GRAID避免了3D重建误差和生成幻觉,从而产生比现有工具更高质量的数据集,这已通过人工评估验证。我们将我们的框架应用于BDD100k、NuImages和Waymo数据集,生成了超过850万个高质量的VQA对,创建了涵盖空间关系、计数、排序和大小比较的问题。我们评估了其中一个数据集,发现它实现了91.16%的人工验证准确率,而最近一项工作生成的数据集仅为57.6%。至关重要的是,我们证明了当在GRAID数据上训练时,模型学习到的空间推理概念可以泛化:在6种问题类型上微调的模型在超过10种保留类型上有所改进,Llama 3.2B 11B在BDD和NuImages上的准确率分别提高了47.5%和37.9%,并且当在所有问题类型上训练时,在BLINK等多个现有基准上取得了改进。GRAID框架、数据集和其他信息可以在此处找到。
🔬 方法详解
问题定义:现有视觉语言模型在空间推理能力上存在不足,主要原因是训练数据质量不高。现有的数据生成方法,如基于单图像3D重建和基于字幕的方法,分别存在建模误差和生成幻觉的问题,导致生成的数据集质量较低,人工验证率不高。
核心思路:GRAID的核心思路是利用2D几何基元来可靠地确定定性的空间关系。通过直接操作2D边界框,避免了复杂的3D重建过程,从而消除了由此产生的误差。同时,避免使用生成模型,减少了生成幻觉的风险,保证了数据质量。
技术框架:GRAID框架主要包括以下几个阶段:1) 使用标准目标检测器检测图像中的物体,并获得其2D边界框;2) 基于这些边界框,定义各种空间关系,如“在...之上”、“在...之下”、“在...旁边”等;3) 根据定义的空间关系,自动生成VQA对,包括问题和答案;4) 对生成的数据进行人工验证,确保数据质量。
关键创新:GRAID最重要的创新点在于其数据生成方式。它摒弃了传统的3D重建和生成模型,而是直接基于2D几何基元来生成VQA数据。这种方法不仅简单高效,而且能够有效避免建模误差和生成幻觉,从而保证了数据质量。
关键设计:GRAID的关键设计在于其空间关系的定义和问题生成策略。论文中详细描述了如何基于2D边界框来定义各种空间关系,以及如何根据这些关系来生成自然语言问题。此外,论文还采用了人工验证机制,对生成的数据进行筛选,进一步提高了数据质量。具体参数设置和损失函数等细节未在摘要中提及,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用GRAID生成的数据集的人工验证准确率达到了91.16%,相比于现有方法生成的57.6%有了显著提升。此外,在GRAID数据上训练的模型在空间推理任务上取得了显著的性能提升,Llama 3.2B 11B在BDD和NuImages上的准确率分别提高了47.5%和37.9%。这些结果表明,GRAID能够有效提高视觉语言模型的空间推理能力。
🎯 应用场景
GRAID的研究成果可以广泛应用于需要空间推理能力的视觉语言任务中,例如自动驾驶、机器人导航、智能家居等。高质量的VQA数据集可以帮助提升模型对场景的理解能力,从而提高这些应用的安全性和可靠性。此外,该方法还可以用于生成其他类型的视觉语言数据,例如图像描述、视觉对话等,具有广泛的应用前景。
📄 摘要(原文)
Vision Language Models (VLMs) achieve strong performance on many vision-language tasks but often struggle with spatial reasoning$\unicode{x2014}$a prerequisite for many applications. Empirically, we find that a dataset produced by a current training data generation pipeline has a 57.6% human validation rate. These rates stem from current limitations: single-image 3D reconstruction introduces cascading modeling errors and requires wide answer tolerances, while caption-based methods require hyper-detailed annotations and suffer from generative hallucinations. We present GRAID, built on the key insight that qualitative spatial relationships can be reliably determined from 2D geometric primitives alone. By operating exclusively on 2D bounding boxes from standard object detectors, GRAID avoids both 3D reconstruction errors and generative hallucinations, resulting in datasets that are of higher quality than existing tools that produce similar datasets as validated by human evaluations. We apply our framework to the BDD100k, NuImages, and Waymo datasets, generating over 8.5 million high-quality VQA pairs creating questions spanning spatial relations, counting, ranking, and size comparisons. We evaluate one of the datasets and find it achieves 91.16% human-validated accuracy$\unicode{x2014}$compared to 57.6% on a dataset generated by recent work. Critically, we demonstrate that when trained on GRAID data, models learn spatial reasoning concepts that generalize: models fine-tuned on 6 question types improve on over 10 held-out types, with accuracy gains of 47.5% on BDD and 37.9% on NuImages for Llama 3.2B 11B, and when trained on all questions types, achieve improvements on several existing benchmarks such as BLINK. The GRAID framework, datasets, and additional information can be found $\href{this https URL}{here}$.