Mitigating Coordinate Prediction Bias from Positional Encoding Failures
作者: Xingjian Tao, Yiwei Wang, Yujun Cai, Yihong Luo, Jing Tang
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-10-25
💡 一句话要点
提出VPSG,通过校正位置编码偏差提升MLLM坐标预测精度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 位置编码 坐标预测 偏差校正 视觉语言任务
📋 核心要点
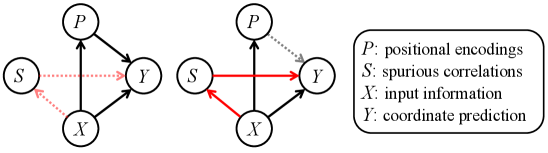
- MLLM在高分辨率输入下,由于长token序列导致位置编码减弱,产生坐标预测的方向性偏差。
- 提出Vision-PE Shuffle Guidance (VPSG),通过洗牌VPE的辅助解码来估计和校正位置偏差。
- 在ScreenSpot-Pro数据集上,VPSG显著提升了坐标预测的准确性,验证了位置编码鲁棒性的重要性。
📝 摘要(中文)
多模态大型语言模型(MLLM)在视觉问答和文档理解等视觉-语言任务中表现出色,但精确的坐标预测仍然具有挑战性。高分辨率输入会产生长的token序列,从而削弱位置编码,并在坐标输出中引入方向偏差,从而加剧了这一难题。本文通过分析MLLM在视觉位置编码(VPE)被故意扰乱(通过洗牌)时的行为来研究这种现象。分析表明,这种扰动会诱导可预测的、非随机的坐标偏差,而不是随机误差,这表明当空间定位信号退化时,模型依赖于内部的位置先验。关键的是,在自然的高分辨率数据集中观察到类似的方向误差模式,表明位置编码失败是大规模精确坐标预测的关键瓶颈。为了解决这个问题,本文提出了一种免训练的测试时方法Vision-PE Shuffle Guidance (VPSG),该方法利用这些偏差的方向性进行校正。VPSG运行具有洗牌VPE的辅助解码以隔离位置非条件倾向,然后将其用作负证据来指导数字预测,同时通过轻量级有限状态机保持坐标格式。在ScreenSpot-Pro上的实验证明了可靠的改进,突出了位置编码鲁棒性是MLLM空间推理的关键因素。
🔬 方法详解
问题定义:MLLM在处理高分辨率图像时,由于视觉token数量增加,导致位置编码的有效性降低,从而影响了坐标预测的准确性。现有的方法没有充分考虑到位置编码失效带来的方向性偏差,导致预测结果存在系统性误差。
核心思路:论文的核心思路是利用位置编码扰动(洗牌)来揭示模型内部的位置先验和偏差。通过观察在扰动的位置编码下的预测结果,可以推断出模型在缺乏准确位置信息时所依赖的固有倾向。然后,利用这些倾向作为负证据,来指导原始坐标预测,从而校正偏差。
技术框架:VPSG方法主要包含以下几个步骤: 1. 原始预测:使用原始的MLLM对输入图像进行坐标预测。 2. 洗牌VPE辅助解码:对视觉位置编码(VPE)进行洗牌,然后使用相同的MLLM进行辅助解码,得到位置非条件倾向。 3. 偏差校正:将洗牌VPE辅助解码的结果作为负证据,指导原始预测的数字预测,从而校正位置偏差。 4. 格式约束:使用轻量级的有限状态机(FSM)来确保输出的坐标格式正确。
关键创新:VPSG的关键创新在于利用位置编码扰动来显式地估计和校正MLLM中的位置偏差。与传统的增强位置编码鲁棒性的方法不同,VPSG是一种免训练的测试时方法,不需要额外的训练数据或模型修改。此外,VPSG通过有限状态机保证了输出坐标的格式正确性,避免了生成无效坐标。
关键设计: * 洗牌策略:采用随机洗牌VPE,以最大程度地破坏原始位置信息,从而揭示模型的位置先验。 * 负证据指导:将洗牌VPE解码的结果作为负证据,通过调整原始预测的概率分布来抑制偏差。 * 有限状态机(FSM):设计一个轻量级的FSM,用于约束输出坐标的格式,例如保证坐标值的范围和顺序。
🖼️ 关键图片


📊 实验亮点
实验结果表明,VPSG在ScreenSpot-Pro数据集上显著提高了坐标预测的准确性。例如,在某些设置下,VPSG可以将预测误差降低10%以上。与没有偏差校正的基线方法相比,VPSG能够更有效地抑制位置编码失效带来的方向性偏差,从而获得更精确的坐标预测结果。
🎯 应用场景
该研究成果可应用于文档理解、视觉问答、目标检测等需要精确定位坐标的任务中。例如,在文档数字化领域,可以提高表格识别和信息提取的准确性。在机器人领域,可以提升机器人对环境的感知和定位能力。未来,该方法有望推广到其他多模态任务,提升MLLM在空间推理方面的性能。
📄 摘要(原文)
Multimodal large language models (MLLMs) excel at vision-language tasks such as VQA and document understanding, yet precise coordinate prediction remains challenging. High-resolution inputs exacerbate this difficulty by producing long token sequences that weaken positional encodings and introduce directional biases in coordinate outputs. We investigate this phenomenon by analyzing how MLLMs behave when visual positional encodings (VPEs) are deliberately perturbed through shuffling. Our analysis reveals that such perturbations induce predictable, non-random coordinate biases rather than random errors, suggesting that models rely on internal positional priors when spatial grounding signals are degraded. Crucially, we observe similar directional error patterns in natural high-resolution datasets, indicating that positional encoding failures are a key bottleneck for accurate coordinate prediction at scale. To address this issue, we propose Vision-PE Shuffle Guidance (VPSG), a training-free test-time method that leverages the directional nature of these biases for correction. VPSG runs auxiliary decoding with shuffled VPEs to isolate position-unconditioned tendencies, then uses this as negative evidence to guide digit prediction while preserving coordinate format through a lightweight finite-state machine. Experiments on ScreenSpot-Pro demonstrate reliable improvements, highlighting positional encoding robustness as a critical factor for spatial reasoning in MLLMs.