Head Pursuit: Probing Attention Specialization in Multimodal Transformers
作者: Lorenzo Basile, Valentino Maiorca, Diego Doimo, Francesco Locatello, Alberto Cazzaniga
分类: cs.CV, cs.CL, cs.LG
发布日期: 2025-10-24 (更新: 2026-01-14)
备注: Accepted at NeurIPS 2025 (spotlight)
💡 一句话要点
通过探究注意力头专业化,理解和控制多模态Transformer模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 注意力机制 可解释性 多模态Transformer 模型编辑 信号处理
📋 核心要点
- 现有语言和视觉-语言模型性能优异,但其内部机制仍不明确,理解模型内部运作是重要挑战。
- 论文提出一种基于信号处理的注意力头分析方法,用于识别和量化各个注意力头在特定语义或视觉属性上的专业化程度。
- 实验表明,通过少量编辑(1%)特定注意力头,即可有效控制模型输出中的目标概念,验证了方法有效性。
📝 摘要(中文)
本文研究了文本生成模型中,各个注意力头如何在特定语义或视觉属性上进行专业化。基于已有的可解释性方法,作者从信号处理的角度重新审视了使用最终解码层探测中间层激活值的做法。这使得能够以规范的方式分析多个样本,并根据注意力头与目标概念的相关性对其进行排序。结果表明,在单模态和多模态Transformer中,注意力头层面上存在一致的专业化模式。值得注意的是,仅编辑少量(1%)通过该方法选择的注意力头,就可以可靠地抑制或增强模型输出中的目标概念。该方法在问答、毒性缓解等语言任务,以及图像分类和图像描述等视觉-语言任务上得到了验证。研究结果突出了注意力层中可解释和可控的结构,为理解和编辑大规模生成模型提供了简单工具。
🔬 方法详解
问题定义:现有大型语言模型和视觉-语言模型虽然在各种任务上表现出色,但其内部机制复杂,难以理解。具体而言,如何确定模型中的哪些部分负责处理特定的语义或视觉属性,以及如何利用这些知识来控制模型的行为,是亟待解决的问题。现有方法通常缺乏对注意力头专业化模式的深入分析,难以实现对模型行为的精确控制。
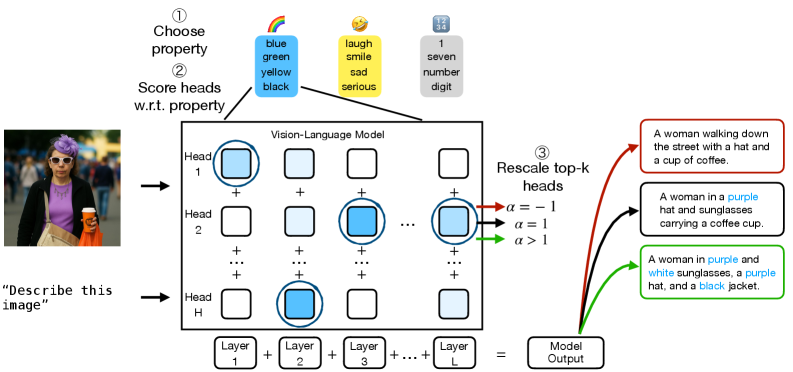
核心思路:论文的核心思路是将注意力头的激活视为信号,并利用信号处理的工具来分析这些信号与特定概念之间的关系。通过这种方式,可以量化每个注意力头对特定概念的贡献程度,并根据其重要性对注意力头进行排序。这种方法允许研究者以一种原则性的方式分析多个样本,并识别出在处理特定概念时具有专业化的注意力头。
技术框架:该方法主要包含以下几个步骤:1) 使用目标概念(例如,特定对象或属性)构建探测任务。2) 通过模型的前向传播,获取中间层注意力头的激活值。3) 将注意力头的激活值视为信号,并使用信号处理技术(例如,相关性分析)来量化这些信号与目标概念之间的关系。4) 根据注意力头与目标概念的相关性对其进行排序。5) 通过编辑(例如,抑制或增强)排名靠前的注意力头,来控制模型输出中的目标概念。
关键创新:该方法的关键创新在于将信号处理的视角引入到Transformer模型的可解释性分析中。通过这种方式,可以更精确地量化注意力头对特定概念的贡献程度,并实现对模型行为的更精细控制。与现有方法相比,该方法能够以一种原则性的方式分析多个样本,并识别出在处理特定概念时具有专业化的注意力头。
关键设计:论文的关键设计包括:1) 使用相关性分析来量化注意力头与目标概念之间的关系。2) 设计了一种基于注意力头重要性的编辑策略,通过抑制或增强排名靠前的注意力头来控制模型输出。3) 在各种语言和视觉-语言任务上验证了该方法的有效性,包括问答、毒性缓解、图像分类和图像描述等。
🖼️ 关键图片
📊 实验亮点
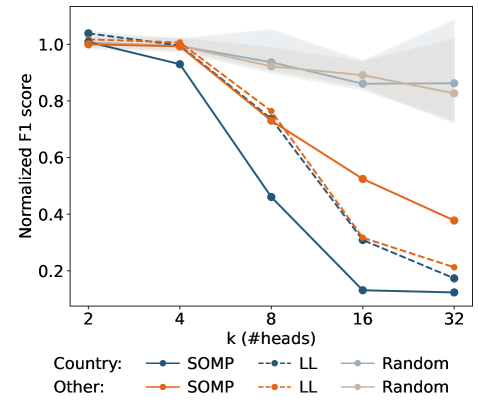
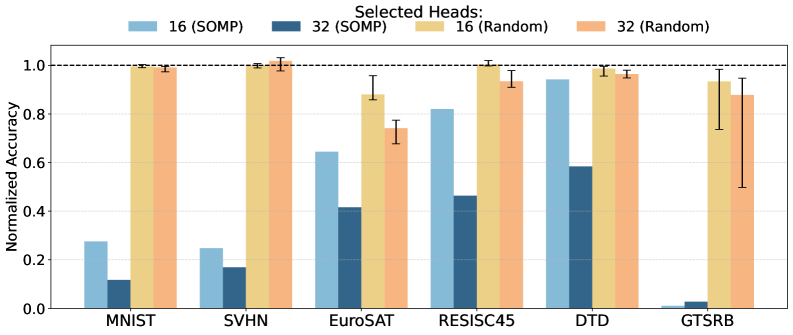
实验结果表明,仅编辑1%的注意力头,即可显著抑制或增强模型输出中的目标概念。例如,在毒性缓解任务中,通过抑制与毒性相关的注意力头,可以有效降低模型输出中的毒性内容。在图像描述任务中,通过增强与特定对象相关的注意力头,可以提高模型生成描述的准确性。
🎯 应用场景
该研究成果可应用于提升大型语言模型和视觉-语言模型的可解释性和可控性。例如,可以用于缓解模型输出中的毒性内容,增强模型对特定概念的理解,或根据用户需求定制模型的行为。此外,该方法还可以用于诊断模型的潜在问题,例如识别模型中的偏见或漏洞。
📄 摘要(原文)
Language and vision-language models have shown impressive performance across a wide range of tasks, but their internal mechanisms remain only partly understood. In this work, we study how individual attention heads in text-generative models specialize in specific semantic or visual attributes. Building on an established interpretability method, we reinterpret the practice of probing intermediate activations with the final decoding layer through the lens of signal processing. This lets us analyze multiple samples in a principled way and rank attention heads based on their relevance to target concepts. Our results show consistent patterns of specialization at the head level across both unimodal and multimodal transformers. Remarkably, we find that editing as few as 1% of the heads, selected using our method, can reliably suppress or enhance targeted concepts in the model output. We validate our approach on language tasks such as question answering and toxicity mitigation, as well as vision-language tasks including image classification and captioning. Our findings highlight an interpretable and controllable structure within attention layers, offering simple tools for understanding and editing large-scale generative models.