ArtiLatent: Realistic Articulated 3D Object Generation via Structured Latents
作者: Honghua Chen, Yushi Lan, Yongwei Chen, Xingang Pan
分类: cs.CV, cs.GR
发布日期: 2025-10-24
备注: accepted to SIGGRAPH Asia; Project page: https://chenhonghua.github.io/MyProjects/ArtiLatent/
💡 一句话要点
ArtiLatent:通过结构化隐空间生成逼真可动3D物体
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting)
关键词: 可动3D物体生成 隐扩散模型 铰接感知解码 变分自编码器 几何建模 外观建模
📋 核心要点
- 现有方法难以生成具有精细几何、精确铰接和逼真外观的可动3D物体,尤其是在铰接状态变化时外观不一致。
- ArtiLatent通过变分自编码器将部件几何和铰接属性嵌入统一隐空间,并使用隐扩散模型进行采样,保证多样性和物理合理性。
- 该方法提出铰接感知高斯解码器,根据铰接状态调整可见性,并为遮挡区域分配纹理特征,显著提升铰接配置下的视觉真实感。
📝 摘要(中文)
我们提出了ArtiLatent,一个生成框架,用于合成具有精细几何形状、精确铰接和逼真外观的人造3D物体。我们的方法通过变分自编码器将稀疏体素表示和相关的铰接属性(包括关节类型、轴、原点、范围和部件类别)嵌入到统一的隐空间中,从而联合建模部件几何形状和铰接动态。然后,在这个空间上训练一个隐扩散模型,以实现多样化但物理上合理的采样。为了重建逼真的3D形状,我们引入了一个铰接感知高斯解码器,该解码器考虑了铰接相关的可见性变化(例如,打开抽屉时露出内部)。通过将外观解码建立在铰接状态的基础上,我们的方法为静态姿势中通常被遮挡的区域分配合理的纹理特征,从而显著提高了各种铰接配置中的视觉真实感。在PartNet-Mobility和ACD数据集中,对类似家具的物体进行的大量实验表明,ArtiLatent在几何一致性和外观保真度方面优于现有方法。我们的框架为铰接3D物体的合成和操作提供了一个可扩展的解决方案。
🔬 方法详解
问题定义:现有方法在生成可动3D物体时,难以兼顾几何细节、铰接精度和外观真实感。尤其是在物体进行铰接运动时,由于内部结构暴露或遮挡关系变化,外观的一致性难以保证。现有方法通常无法很好地处理这些铰接相关的外观变化,导致生成结果不真实。
核心思路:ArtiLatent的核心思路是将部件的几何形状和铰接属性(如关节类型、轴、原点等)统一编码到一个隐空间中,然后利用隐扩散模型学习这个隐空间的分布,从而实现多样且物理上合理的采样。此外,该方法还引入了铰接感知的解码器,根据铰接状态动态调整物体的可见性,并为通常被遮挡的区域分配合理的纹理特征,从而保证外观的真实性。
技术框架:ArtiLatent框架主要包含三个模块:1) 变分自编码器(VAE),用于将3D物体的几何形状和铰接属性编码到隐空间中;2) 隐扩散模型(Latent Diffusion Model),用于学习隐空间的分布,并生成新的隐向量;3) 铰接感知高斯解码器(Articulation-aware Gaussian Decoder),用于将隐向量解码为3D物体,并根据铰接状态调整外观。整个流程是先通过VAE将训练数据编码到隐空间,然后训练隐扩散模型,最后使用训练好的隐扩散模型生成新的隐向量,并通过铰接感知解码器生成最终的3D物体。
关键创新:ArtiLatent的关键创新在于以下几点:1) 统一建模部件几何形状和铰接属性,使得生成的可动物体具有更高的物理合理性;2) 引入隐扩散模型,提高了生成结果的多样性;3) 提出铰接感知高斯解码器,根据铰接状态动态调整外观,显著提高了视觉真实感。与现有方法相比,ArtiLatent能够更好地处理铰接相关的外观变化,生成更逼真的可动3D物体。
关键设计:在VAE中,使用了稀疏体素表示来编码3D物体的几何形状。铰接感知高斯解码器通过将铰接状态作为条件输入,动态调整高斯分布的参数,从而控制物体的可见性。损失函数包括重建损失、KL散度和对抗损失,用于保证生成结果的质量和多样性。网络结构方面,使用了3D卷积神经网络和Transformer等模块。
🖼️ 关键图片


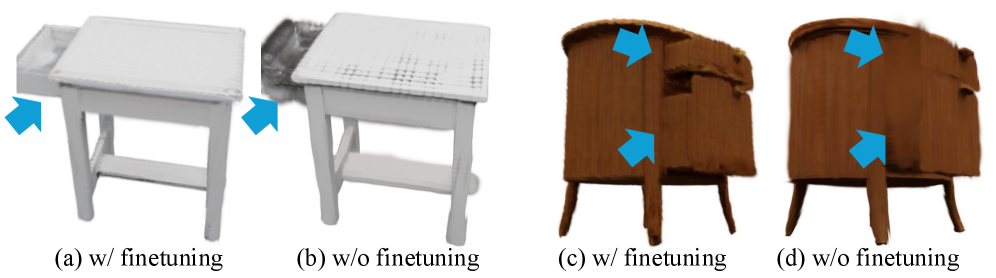
📊 实验亮点
在PartNet-Mobility和ACD数据集上的实验表明,ArtiLatent在几何一致性和外观保真度方面均优于现有方法。例如,在铰接状态变化时,ArtiLatent生成的结果具有更真实的外观,并且能够更好地保持几何形状的一致性。定量指标也显示,ArtiLatent在FID和IS等指标上取得了显著提升。
🎯 应用场景
ArtiLatent在虚拟现实、游戏开发、机器人仿真等领域具有广泛的应用前景。它可以用于生成各种逼真的可动3D物体,例如家具、工具、机械设备等,从而丰富虚拟环境的内容。此外,ArtiLatent还可以用于设计新的可动物体,例如新型机器人或家具,并进行仿真测试,从而加速产品开发过程。
📄 摘要(原文)
We propose ArtiLatent, a generative framework that synthesizes human-made 3D objects with fine-grained geometry, accurate articulation, and realistic appearance. Our approach jointly models part geometry and articulation dynamics by embedding sparse voxel representations and associated articulation properties, including joint type, axis, origin, range, and part category, into a unified latent space via a variational autoencoder. A latent diffusion model is then trained over this space to enable diverse yet physically plausible sampling. To reconstruct photorealistic 3D shapes, we introduce an articulation-aware Gaussian decoder that accounts for articulation-dependent visibility changes (e.g., revealing the interior of a drawer when opened). By conditioning appearance decoding on articulation state, our method assigns plausible texture features to regions that are typically occluded in static poses, significantly improving visual realism across articulation configurations. Extensive experiments on furniture-like objects from PartNet-Mobility and ACD datasets demonstrate that ArtiLatent outperforms existing approaches in geometric consistency and appearance fidelity. Our framework provides a scalable solution for articulated 3D object synthesis and manipulation.