ZING-3D: Zero-shot Incremental 3D Scene Graphs via Vision-Language Models
作者: Pranav Saxena, Jimmy Chiun
分类: cs.CV, cs.RO
发布日期: 2025-10-24
💡 一句话要点
ZING-3D:利用视觉-语言模型实现零样本增量式3D场景图构建
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D场景图 视觉-语言模型 零样本学习 增量学习 具身智能 开放词汇识别 几何定位
📋 核心要点
- 现有3D场景图生成方法主要局限于单视角,缺乏增量更新能力,且缺乏在3D空间中的显式几何定位,难以应用于具身智能场景。
- ZING-3D利用预训练视觉-语言模型进行开放词汇识别,并生成场景的语义表示,同时支持增量更新和3D几何定位。
- 在Replica和HM3D数据集上的实验表明,ZING-3D能够有效地捕获空间和关系知识,无需特定任务的训练。
📝 摘要(中文)
本文提出ZING-3D,一个利用预训练基础模型知识的框架,用于实现开放词汇识别并以零样本方式生成场景的丰富语义表示。该框架支持增量式更新和3D空间中的几何定位,适用于具身智能场景。ZING-3D利用视觉-语言模型推理生成丰富的2D场景图,并使用深度信息将其定位到3D空间。节点表示具有特征、3D位置和语义上下文的开放词汇对象,边捕获具有对象间距离的空间和语义关系。在Replica和HM3D数据集上的实验表明,ZING-3D能够有效地捕获空间和关系知识,而无需特定于任务的训练。
🔬 方法详解
问题定义:现有3D场景图生成方法在具身智能场景中存在局限性。它们通常依赖于单视角信息,无法随着新观测的到来进行增量更新,并且缺乏在3D空间中的精确几何定位。这些限制阻碍了它们在机器人导航、场景理解等任务中的应用。
核心思路:ZING-3D的核心思路是利用预训练的视觉-语言模型(VLM)的强大语义理解能力,结合深度信息,将2D场景图转化为具有3D几何信息的场景图。通过VLM进行开放词汇识别,并利用深度信息将识别到的对象定位到3D空间中,从而构建一个具有丰富语义和几何信息的3D场景图。增量更新通过融合新的观测数据来实现。
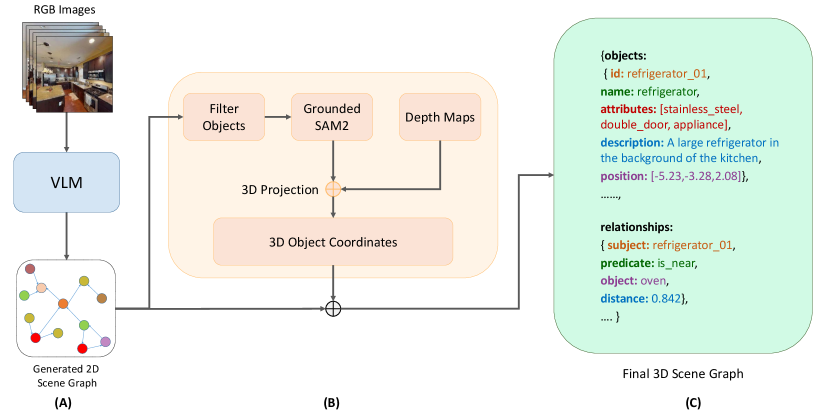
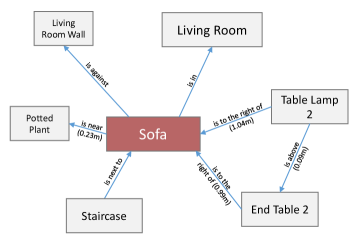
技术框架:ZING-3D框架主要包含以下几个阶段:1) 利用VLM对2D图像进行场景图生成,识别场景中的对象及其关系。2) 使用深度信息将2D场景图中的对象定位到3D空间,得到每个对象的3D位置。3) 构建3D场景图,其中节点表示具有特征、3D位置和语义上下文的对象,边表示对象之间的空间和语义关系。4) 当有新的观测数据到来时,进行增量更新,将新的对象和关系添加到3D场景图中。
关键创新:ZING-3D的关键创新在于:1) 利用预训练的VLM进行开放词汇的3D场景图生成,无需特定任务的训练。2) 实现了3D场景图的增量更新,能够随着新观测的到来不断完善场景表示。3) 将2D场景图与深度信息相结合,实现了3D场景图的几何定位。
关键设计:ZING-3D使用预训练的VLM(具体模型未知)进行2D场景图生成。深度信息的获取方式未知,但用于将2D对象定位到3D空间。节点特征包含对象的视觉特征和语义信息。边表示对象之间的空间关系(如距离)和语义关系(如“在...之上”)。增量更新的具体策略未知,但需要考虑如何融合新的观测数据并保持场景图的一致性。
🖼️ 关键图片

📊 实验亮点
ZING-3D在Replica和HM3D数据集上进行了实验,结果表明,该方法能够有效地捕获空间和关系知识,而无需特定于任务的训练。虽然论文中没有给出具体的性能数据和提升幅度,但强调了ZING-3D在零样本学习和增量更新方面的优势。
🎯 应用场景
ZING-3D可应用于机器人导航、场景理解、增强现实等领域。例如,机器人可以利用ZING-3D构建的3D场景图进行自主导航和物体交互。在AR应用中,可以将虚拟对象与真实场景中的对象进行对齐和交互。未来,该技术有望促进人机协作和智能环境的构建。
📄 摘要(原文)
Understanding and reasoning about complex 3D environments requires structured scene representations that capture not only objects but also their semantic and spatial relationships. While recent works on 3D scene graph generation have leveraged pretrained VLMs without task-specific fine-tuning, they are largely confined to single-view settings, fail to support incremental updates as new observations arrive and lack explicit geometric grounding in 3D space, all of which are essential for embodied scenarios. In this paper, we propose, ZING-3D, a framework that leverages the vast knowledge of pretrained foundation models to enable open-vocabulary recognition and generate a rich semantic representation of the scene in a zero-shot manner while also enabling incremental updates and geometric grounding in 3D space, making it suitable for downstream robotics applications. Our approach leverages VLM reasoning to generate a rich 2D scene graph, which is grounded in 3D using depth information. Nodes represent open-vocabulary objects with features, 3D locations, and semantic context, while edges capture spatial and semantic relations with inter-object distances. Our experiments on scenes from the Replica and HM3D dataset show that ZING-3D is effective at capturing spatial and relational knowledge without the need of task-specific training.