From Far and Near: Perceptual Evaluation of Crowd Representations Across Levels of Detail
作者: Xiaohan Sun, Carol O'Sullivan
分类: cs.CV, cs.GR, cs.HC
发布日期: 2025-10-23
💡 一句话要点
研究不同细节层次下人群表征的感知质量,优化人群渲染策略
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 人群渲染 细节层次 感知评估 神经辐射场 3D高斯
📋 核心要点
- 现有的人群渲染方法在视觉质量和计算效率之间存在权衡,难以兼顾远近距离的感知需求。
- 本文通过感知实验评估不同细节层次的人群表征方法,旨在找到感知质量和计算性能的最佳平衡点。
- 实验结果揭示了不同表征方法在不同观看距离下的感知特性,为人群渲染的LoD策略设计提供指导。
📝 摘要(中文)
本文研究了用户在不同细节层次(LoD)和观看距离下对人群角色表征的视觉质量的感知。几何网格、基于图像的替身(impostors)、神经辐射场(NeRFs)和3D高斯等不同的表征方式,在视觉保真度和计算性能之间表现出不同的权衡。我们的定性和定量结果为指导人群渲染中感知优化的LoD策略设计提供了见解。
🔬 方法详解
问题定义:人群渲染需要在视觉质量和计算效率之间进行权衡。现有的方法,如几何网格,在近距离观看时视觉效果较好,但计算成本高昂;而基于图像的替身(impostors)虽然计算效率高,但在近距离观看时视觉质量较差。因此,如何根据观看距离和细节层次选择合适的表征方法,以优化人群渲染的感知质量,是一个重要的研究问题。
核心思路:本文的核心思路是通过感知实验来评估不同细节层次(LoD)的人群表征方法,包括几何网格、基于图像的替身、神经辐射场(NeRFs)和3D高斯。通过分析实验数据,了解用户对不同表征方法在不同观看距离下的感知质量,从而为人群渲染的LoD策略设计提供依据。
技术框架:本文的技术框架主要包括以下几个阶段:1)选择不同细节层次的人群表征方法,包括几何网格、基于图像的替身、神经辐射场和3D高斯。2)设计感知实验,让用户在不同的观看距离下评估不同表征方法的视觉质量。3)收集实验数据,包括用户的评分和主观评价。4)分析实验数据,找出不同表征方法在不同观看距离下的感知特性。5)根据实验结果,提出感知优化的人群渲染LoD策略。
关键创新:本文的关键创新在于:1)系统地研究了不同细节层次的人群表征方法在不同观看距离下的感知质量。2)通过感知实验,量化了不同表征方法的视觉质量和计算性能之间的权衡。3)提出了感知优化的人群渲染LoD策略,可以根据观看距离和细节层次选择合适的表征方法,从而提高人群渲染的感知质量和计算效率。
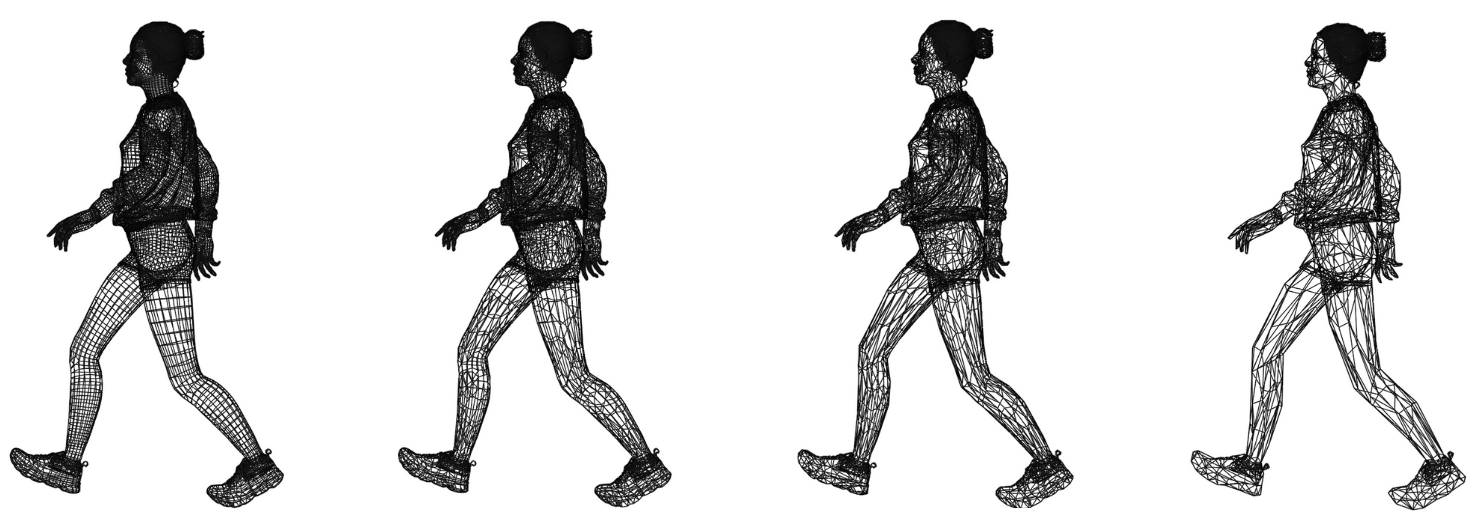
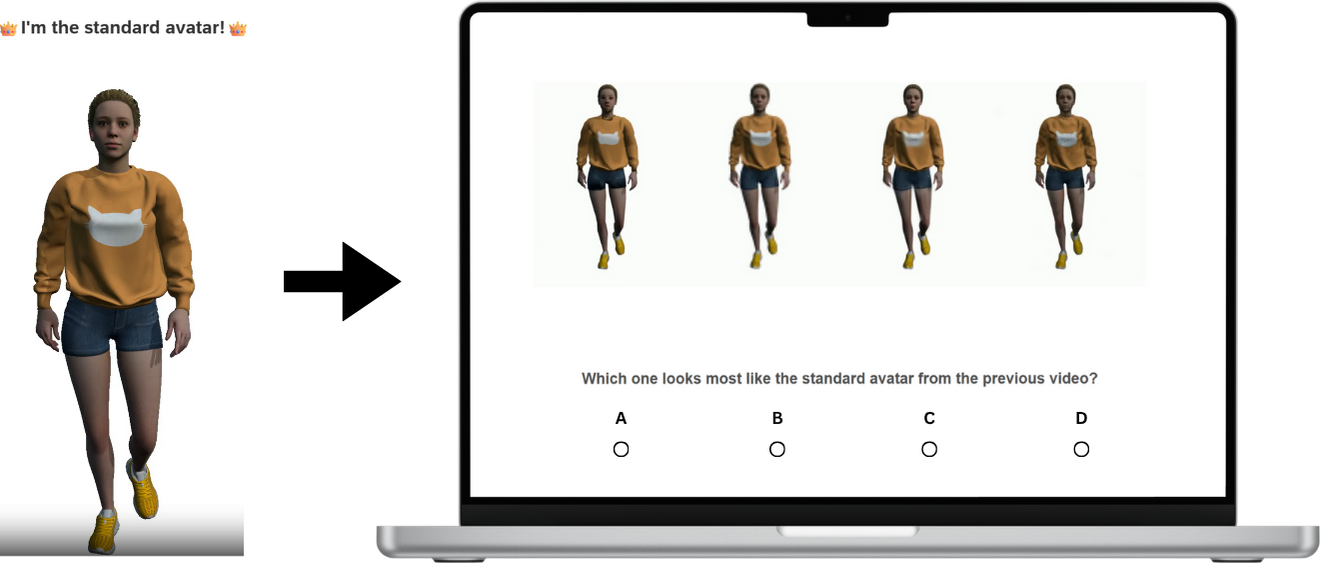
关键设计:实验中,针对每种表征方法,都生成了不同细节层次的模型。例如,对于几何网格,使用了不同数量的三角形来表示人群角色;对于基于图像的替身,使用了不同分辨率的图像。感知实验中,采用了主观评分和成对比较等方法来评估用户的感知质量。此外,还考虑了观看距离、人群密度等因素对感知质量的影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在远距离观看时,基于图像的替身和神经辐射场可以达到与几何网格相似的感知质量,但计算成本更低。在近距离观看时,几何网格的视觉质量明显优于其他方法。通过综合考虑视觉质量和计算性能,可以设计出感知优化的人群渲染LoD策略。
🎯 应用场景
该研究成果可应用于电影、游戏、虚拟现实等领域的人群渲染。通过感知优化的人群渲染LoD策略,可以根据用户的观看距离和设备的计算能力,选择合适的表征方法,从而提高人群渲染的视觉质量和流畅度,增强用户的沉浸感和体验。
📄 摘要(原文)
In this paper, we investigate how users perceive the visual quality of crowd character representations at different levels of detail (LoD) and viewing distances. Each representation: geometric meshes, image-based impostors, Neural Radiance Fields (NeRFs), and 3D Gaussians, exhibits distinct trade-offs between visual fidelity and computational performance. Our qualitative and quantitative results provide insights to guide the design of perceptually optimized LoD strategies for crowd rendering.