Deep Learning-Powered Visual SLAM Aimed at Assisting Visually Impaired Navigation
作者: Marziyeh Bamdad, Hans-Peter Hutter, Alireza Darvishy
分类: cs.CV, cs.RO
发布日期: 2025-10-23
备注: 8 pages, 7 figures, 4 tables
💡 一句话要点
提出SELM-SLAM3,利用深度学习增强视觉SLAM,辅助视障人士导航。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉SLAM 深度学习 特征提取 特征匹配 视障辅助导航
📋 核心要点
- 现有SLAM技术在低纹理、运动模糊等复杂环境下鲁棒性不足,影响视障人士导航等应用。
- SELM-SLAM3框架通过集成SuperPoint和LightGlue,增强特征提取和匹配的鲁棒性,提升SLAM性能。
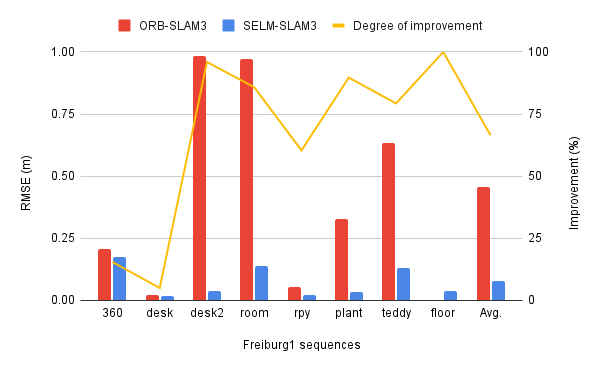
- 实验结果表明,SELM-SLAM3在多个数据集上显著优于ORB-SLAM3和其他先进RGB-D SLAM系统。
📝 摘要(中文)
本文提出了一种基于深度学习的视觉SLAM框架SELM-SLAM3,旨在解决在低纹理、运动模糊或复杂光照等挑战性条件下SLAM的鲁棒性问题。这些问题在视障人士辅助导航等应用中尤为常见,会降低定位精度和跟踪稳定性,从而影响导航的可靠性和安全性。SELM-SLAM3集成了SuperPoint和LightGlue,以实现稳健的特征提取和匹配。在TUM RGB-D、ICL-NUIM和TartanAir数据集上的评估结果表明,SELM-SLAM3的性能优于传统的ORB-SLAM3,平均提升87.84%,并且超过了最先进的RGB-D SLAM系统36.77%。该框架在低纹理场景和快速运动等挑战性条件下表现出增强的性能,为开发视障人士导航辅助工具提供了一个可靠的平台。
🔬 方法详解
问题定义:论文旨在解决视觉SLAM在低纹理、运动模糊和光照变化等挑战性环境中鲁棒性不足的问题。现有方法在这些条件下容易出现特征提取和匹配失败,导致定位精度下降和跟踪丢失,严重影响了SLAM系统的可靠性,尤其是在视障人士导航等安全攸关的应用中。
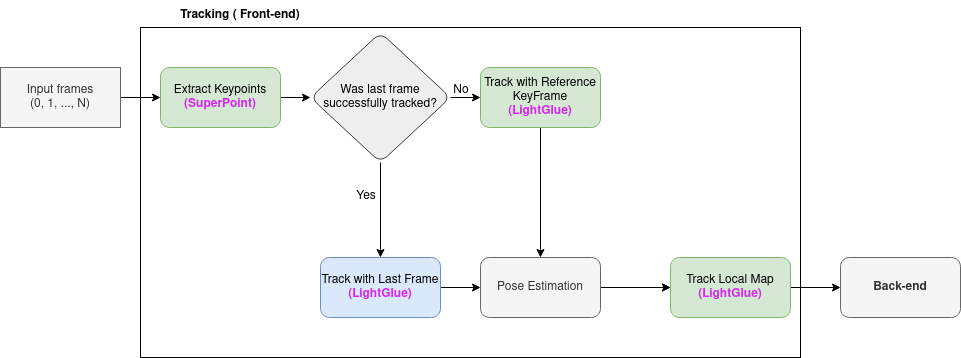
核心思路:论文的核心思路是利用深度学习强大的特征提取和匹配能力,替代传统手工设计的特征提取器和匹配算法。通过学习对环境变化具有不变性的特征表示,提高SLAM系统在复杂环境下的鲁棒性和准确性。具体而言,采用SuperPoint进行特征点提取,并使用LightGlue进行特征匹配。
技术框架:SELM-SLAM3的整体框架基于ORB-SLAM3,主要改进在于特征提取和匹配模块。首先,使用SuperPoint网络提取图像中的特征点,该网络能够提供更稳定和鲁棒的特征。然后,使用LightGlue网络进行特征匹配,该网络利用注意力机制学习特征之间的关系,从而提高匹配的准确性。最后,将匹配后的特征点输入到ORB-SLAM3的后端进行位姿估计和地图构建。
关键创新:该论文的关键创新在于将SuperPoint和LightGlue深度学习模型集成到ORB-SLAM3框架中,显著提升了SLAM系统在挑战性环境下的鲁棒性。与传统方法相比,SuperPoint和LightGlue能够提取更具判别性的特征,并实现更准确的特征匹配,从而提高了SLAM系统的定位精度和跟踪稳定性。
关键设计:SuperPoint网络采用自监督学习方法进行训练,能够提取对光照、尺度和旋转变化具有不变性的特征。LightGlue网络利用图神经网络和注意力机制,学习特征之间的几何关系和上下文信息,从而实现更准确的特征匹配。论文中没有明确提及对SuperPoint和LightGlue的参数进行特殊调整,而是直接使用了预训练的模型。损失函数方面,SuperPoint使用Homographic Adaptation进行自监督训练,LightGlue使用最优传输损失进行匹配优化。
🖼️ 关键图片
📊 实验亮点
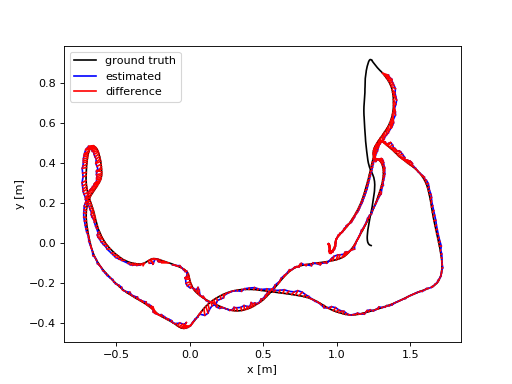
实验结果表明,SELM-SLAM3在TUM RGB-D、ICL-NUIM和TartanAir数据集上显著优于ORB-SLAM3和其他先进的RGB-D SLAM系统。具体而言,SELM-SLAM3的性能平均优于ORB-SLAM3 87.84%,并且超过了最先进的RGB-D SLAM系统36.77%。这些结果表明,SELM-SLAM3在低纹理场景和快速运动等挑战性条件下具有显著的优势。
🎯 应用场景
该研究成果可应用于视障人士辅助导航、机器人自主导航、增强现实和虚拟现实等领域。通过提高SLAM系统在复杂环境下的鲁棒性和准确性,可以为视障人士提供更安全可靠的导航辅助,帮助他们在日常生活中更好地行动。此外,该技术还可以应用于机器人自主导航,使其能够在各种复杂环境中安全可靠地执行任务。在AR/VR领域,该技术可以提供更精确的定位和跟踪,从而提升用户体验。
📄 摘要(原文)
Despite advancements in SLAM technologies, robust operation under challenging conditions such as low-texture, motion-blur, or challenging lighting remains an open challenge. Such conditions are common in applications such as assistive navigation for the visually impaired. These challenges undermine localization accuracy and tracking stability, reducing navigation reliability and safety. To overcome these limitations, we present SELM-SLAM3, a deep learning-enhanced visual SLAM framework that integrates SuperPoint and LightGlue for robust feature extraction and matching. We evaluated our framework using TUM RGB-D, ICL-NUIM, and TartanAir datasets, which feature diverse and challenging scenarios. SELM-SLAM3 outperforms conventional ORB-SLAM3 by an average of 87.84% and exceeds state-of-the-art RGB-D SLAM systems by 36.77%. Our framework demonstrates enhanced performance under challenging conditions, such as low-texture scenes and fast motion, providing a reliable platform for developing navigation aids for the visually impaired.