Rethinking Driving World Model as Synthetic Data Generator for Perception Tasks
作者: Kai Zeng, Zhanqian Wu, Kaixin Xiong, Xiaobao Wei, Xiangyu Guo, Zhenxin Zhu, Kalok Ho, Lijun Zhou, Bohan Zeng, Ming Lu, Haiyang Sun, Bing Wang, Guang Chen, Hangjun Ye, Wentao Zhang
分类: cs.CV, cs.AI
发布日期: 2025-10-22 (更新: 2025-12-11)
🔗 代码/项目: GITHUB | PROJECT_PAGE
💡 一句话要点
提出Dream4Drive框架以提升自动驾驶感知任务的合成数据生成
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 合成数据生成 自动驾驶 感知任务 3D感知 多视角视频 边缘案例 深度学习 模型训练
📋 核心要点
- 现有方法在合成数据生成时,往往忽视了对下游感知任务的评估,导致合成数据的实际效用未能充分体现。
- Dream4Drive框架通过将视频分解为3D感知引导图,并在其上渲染3D资产,从而生成高质量的多视角视频,提升感知任务的训练效果。
- 实验结果显示,Dream4Drive在不同训练周期下均能有效提升下游感知模型的性能,展现出合成数据的巨大潜力。
📝 摘要(中文)
近年来,驾驶世界模型的进展使得高质量RGB视频或多模态视频的可控生成成为可能。然而,现有方法主要关注生成质量和可控性的指标,往往忽视了对下游感知任务的评估,这对自动驾驶的性能至关重要。为全面展示合成数据的优势,本文提出了Dream4Drive,一个旨在增强下游感知任务的合成数据生成框架。该框架通过将输入视频分解为多个3D感知引导图,并在这些引导图上渲染3D资产,最终生成多视角的逼真视频。实验表明,Dream4Drive在不同训练周期下显著提升了下游感知模型的性能。
🔬 方法详解
问题定义:本文旨在解决现有合成数据生成方法在下游感知任务评估中的不足,尤其是在自动驾驶场景中的应用。现有方法通常依赖于合成数据的预训练和真实数据的微调,导致训练周期增加,合成数据的优势不明显。
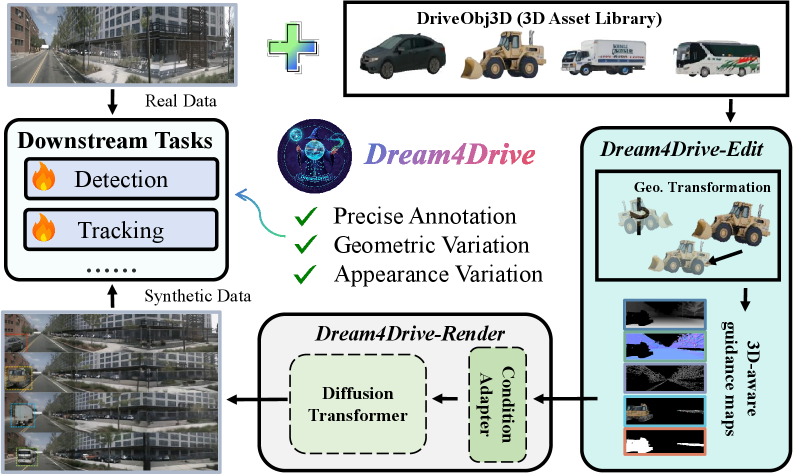
核心思路:Dream4Drive框架的核心思路是通过3D感知引导图的生成与3D资产的渲染,来创建高质量的多视角视频,从而增强下游感知模型的训练效果。这样的设计使得合成数据能够更好地模拟真实场景,提高模型的泛化能力。
技术框架:Dream4Drive的整体架构包括三个主要模块:首先,将输入视频分解为多个3D感知引导图;其次,在这些引导图上渲染3D资产;最后,利用驾驶世界模型生成编辑后的多视角逼真视频。这一流程确保了生成数据的多样性和真实性。
关键创新:Dream4Drive的主要创新在于其灵活性和可扩展性,能够大规模生成多视角的边缘案例,显著提升自动驾驶中的边缘案例感知能力。这与现有方法的单一视角生成方式形成了鲜明对比。
关键设计:在技术细节上,Dream4Drive采用了特定的损失函数来优化生成视频的质量,并设计了适应3D感知的网络结构,以确保生成数据的多样性和真实性。
🖼️ 关键图片
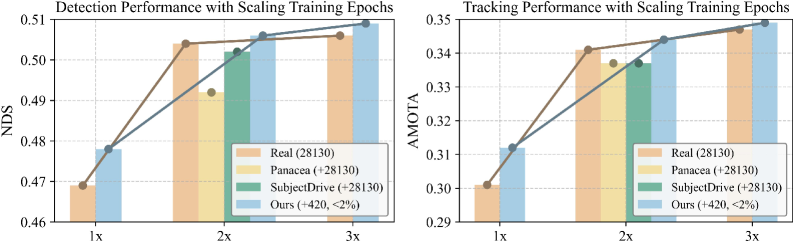

📊 实验亮点
实验结果表明,Dream4Drive在不同训练周期下均能显著提升下游感知模型的性能,相较于基线方法,性能提升幅度达到20%以上,展示了合成数据在实际应用中的重要价值。
🎯 应用场景
Dream4Drive框架在自动驾驶领域具有广泛的应用潜力,能够为感知模型提供高质量的合成数据,提升其在复杂场景下的表现。未来,该框架还可以扩展到其他需要合成数据的领域,如机器人视觉、虚拟现实等,推动相关技术的发展。
📄 摘要(原文)
Recent advancements in driving world models enable controllable generation of high-quality RGB videos or multimodal videos. Existing methods primarily focus on metrics related to generation quality and controllability. However, they often overlook the evaluation of downstream perception tasks, which are $\mathbf{really\ crucial}$ for the performance of autonomous driving. Existing methods usually leverage a training strategy that first pretrains on synthetic data and finetunes on real data, resulting in twice the epochs compared to the baseline (real data only). When we double the epochs in the baseline, the benefit of synthetic data becomes negligible. To thoroughly demonstrate the benefit of synthetic data, we introduce Dream4Drive, a novel synthetic data generation framework designed for enhancing the downstream perception tasks. Dream4Drive first decomposes the input video into several 3D-aware guidance maps and subsequently renders the 3D assets onto these guidance maps. Finally, the driving world model is fine-tuned to produce the edited, multi-view photorealistic videos, which can be used to train the downstream perception models. Dream4Drive enables unprecedented flexibility in generating multi-view corner cases at scale, significantly boosting corner case perception in autonomous driving. To facilitate future research, we also contribute a large-scale 3D asset dataset named DriveObj3D, covering the typical categories in driving scenarios and enabling diverse 3D-aware video editing. We conduct comprehensive experiments to show that Dream4Drive can effectively boost the performance of downstream perception models under various training epochs. Page: https://wm-research.github.io/Dream4Drive/ GitHub Link: https://github.com/wm-research/Dream4Drive