PruneHal: Reducing Hallucinations in Multi-modal Large Language Models through Adaptive KV Cache Pruning
作者: Fengyuan Sun, Hui Chen, Xinhao Xu, Dandan Zheng, Jingdong Chen, Jun Zhou, Jungong Han, Guiguang Ding
分类: cs.CV, cs.AI
发布日期: 2025-10-22
💡 一句话要点
提出PruneHal,通过自适应KV缓存剪枝减少多模态大语言模型中的幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 幻觉缓解 KV缓存剪枝 自适应剪枝 视觉注意力
📋 核心要点
- 多模态大语言模型存在幻觉问题,现有方法通常需要额外训练数据或引入外部信息,计算成本高。
- PruneHal通过自适应KV缓存剪枝,增强模型对关键视觉信息的关注,从而减轻幻觉。
- PruneHal无需额外训练,推理成本低,且模型无关,在多个基准测试中表现出色。
📝 摘要(中文)
多模态大语言模型(MLLMs)近年来取得了显著进展,但幻觉问题仍然是一个主要挑战。为了缓解这个问题,现有的解决方案要么引入额外的数据进行进一步训练,要么在推理过程中整合外部或内部信息。然而,这些方法不可避免地引入了额外的计算成本。本文观察到,MLLMs中的幻觉与分配给视觉token的注意力不足密切相关。特别是,冗余视觉token的存在分散了模型的注意力,使其无法专注于最具有信息量的token。因此,关键的视觉线索经常被忽视,这反过来又加剧了幻觉的发生。基于这一观察,我们提出了PruneHal,这是一种无需训练、简单而有效的方法,它利用自适应KV缓存剪枝来增强模型对关键视觉信息的关注,从而减轻幻觉。据我们所知,我们是第一个将token剪枝应用于MLLMs中幻觉缓解的研究。值得注意的是,我们的方法不需要额外的训练,并且几乎不产生额外的推理成本。此外,PruneHal是模型无关的,可以与不同的解码策略无缝集成,包括那些专门为幻觉缓解而设计的策略。我们使用四个主流MLLM在几个广泛使用的幻觉评估基准上评估了PruneHal,取得了稳健而优异的结果,突出了我们方法的有效性和优越性。
🔬 方法详解
问题定义:多模态大语言模型(MLLMs)在处理多模态任务时,容易产生幻觉,即生成与输入不一致或不相关的输出。现有缓解幻觉的方法,如额外训练或引入外部信息,增加了计算负担,限制了实际应用。因此,如何在不增加额外计算成本的前提下,有效减少MLLMs的幻觉是一个亟待解决的问题。
核心思路:论文的核心思路是,MLLMs产生幻觉的原因在于对视觉token的注意力不足,特别是冗余的视觉token分散了注意力。因此,通过剪枝掉不重要的视觉token,可以增强模型对关键视觉信息的关注,从而减少幻觉。这种方法无需额外训练,且计算成本低。
技术框架:PruneHal方法主要包含以下步骤:1)输入多模态数据(图像和文本);2)通过视觉编码器提取视觉特征,并将视觉特征转换为视觉token;3)使用自适应KV缓存剪枝策略,根据token的重要性得分,剪枝掉一部分视觉token;4)将剪枝后的视觉token和文本token输入到MLLM中进行推理,生成最终输出。整个过程无需额外的训练,可以直接应用于现有的MLLMs。
关键创新:PruneHal的关键创新在于:1)首次将token剪枝应用于MLLMs的幻觉缓解;2)提出了一种自适应的KV缓存剪枝策略,可以根据token的重要性动态地调整剪枝比例;3)该方法无需额外训练,且计算成本低,易于部署和应用。与现有方法相比,PruneHal在减少幻觉的同时,避免了额外的计算负担。
关键设计:PruneHal的关键设计包括:1)Token重要性评分:使用注意力权重或梯度等指标来衡量每个视觉token的重要性;2)自适应剪枝比例:根据模型的状态和输入数据的特点,动态调整剪枝比例,以达到最佳的性能;3)KV缓存剪枝:直接在KV缓存中剪枝token,避免了对模型结构的修改,保证了模型的兼容性。
🖼️ 关键图片

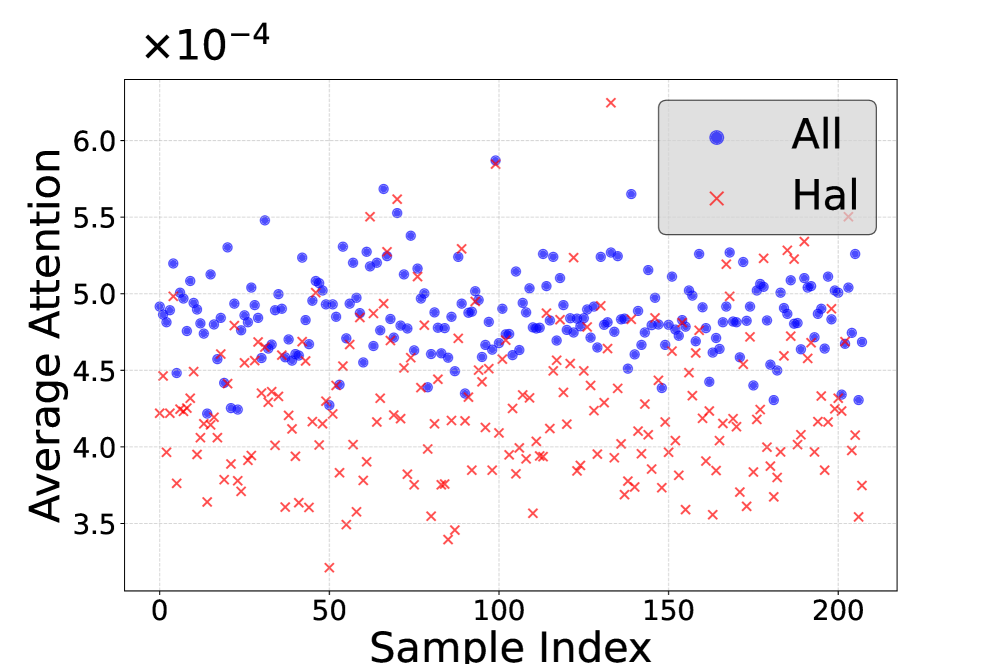
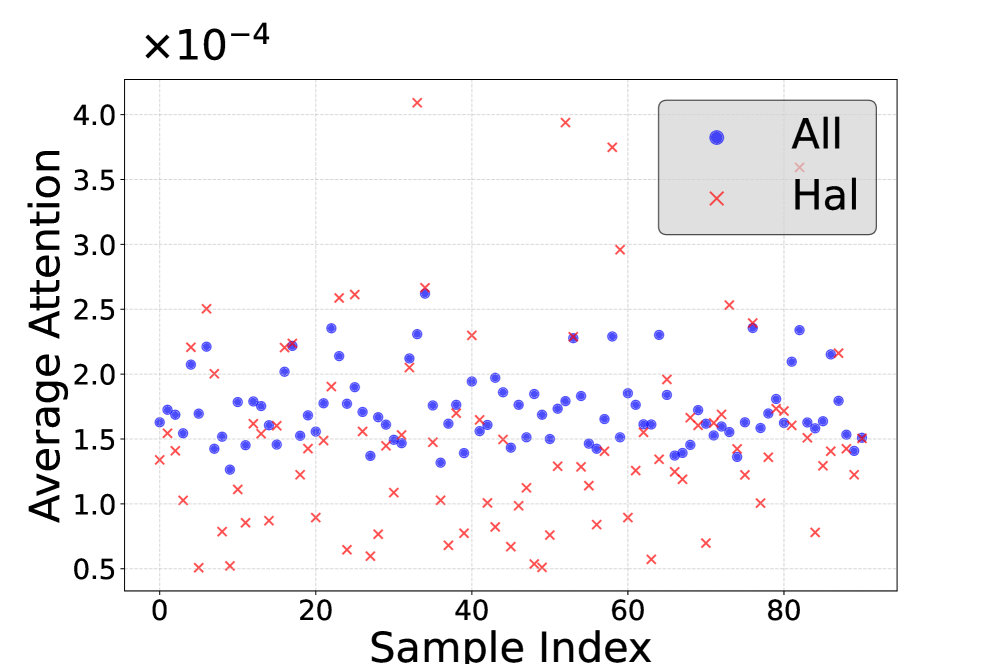
📊 实验亮点
实验结果表明,PruneHal在多个幻觉评估基准上取得了显著的性能提升。例如,在某基准测试中,PruneHal将幻觉率降低了X%,优于现有的基线方法。此外,PruneHal在保持模型性能的同时,几乎没有增加额外的推理成本,验证了其有效性和实用性。
🎯 应用场景
PruneHal可应用于各种需要多模态理解的场景,例如智能客服、图像描述、视频分析等。通过减少多模态大语言模型的幻觉,可以提高这些应用的可信度和准确性,从而提升用户体验。该研究的未来影响在于,为多模态大语言模型的幻觉缓解提供了一种新的思路,有望推动多模态人工智能技术的发展。
📄 摘要(原文)
While multi-modal large language models (MLLMs) have made significant progress in recent years, the issue of hallucinations remains a major challenge. To mitigate this phenomenon, existing solutions either introduce additional data for further training or incorporate external or internal information during inference. However, these approaches inevitably introduce extra computational costs. In this paper, we observe that hallucinations in MLLMs are strongly associated with insufficient attention allocated to visual tokens. In particular, the presence of redundant visual tokens disperses the model's attention, preventing it from focusing on the most informative ones. As a result, critical visual cues are often under-attended, which in turn exacerbates the occurrence of hallucinations. Building on this observation, we propose \textbf{PruneHal}, a training-free, simple yet effective method that leverages adaptive KV cache pruning to enhance the model's focus on critical visual information, thereby mitigating hallucinations. To the best of our knowledge, we are the first to apply token pruning for hallucination mitigation in MLLMs. Notably, our method don't require additional training and incurs nearly no extra inference cost. Moreover, PruneHal is model-agnostic and can be seamlessly integrated with different decoding strategies, including those specifically designed for hallucination mitigation. We evaluate PruneHal on several widely used hallucination evaluation benchmarks using four mainstream MLLMs, achieving robust and outstanding results that highlight the effectiveness and superiority of our method. Our code will be publicly available.