Embodied Navigation with Auxiliary Task of Action Description Prediction
作者: Haru Kondoh, Asako Kanezaki
分类: cs.CV, cs.RO
发布日期: 2025-10-21
备注: ICCV 2025 Poster
💡 一句话要点
提出基于动作描述预测辅助任务的具身导航方法,提升导航性能和可解释性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身导航 强化学习 动作描述 知识蒸馏 多模态学习 可解释性 视听导航
📋 核心要点
- 现有具身导航系统决策过程复杂,缺乏可解释性,难以保证可靠性,而提升可解释性往往会牺牲导航性能。
- 论文提出将动作描述预测作为辅助任务,融入导航的强化学习中,从而在不牺牲性能的前提下,提升系统的可解释性。
- 实验结果表明,该方法在多种导航任务中表现良好,尤其在语义视听导航任务中取得了state-of-the-art的性能。
📝 摘要(中文)
近年来,室内环境中的多模态机器人导航领域受到了广泛关注。然而,随着任务和方法的日益复杂,动作决策系统往往变得复杂且难以理解。对于一个可靠的系统来说,解释或描述其决策的能力至关重要;然而,可解释的系统在性能上往往不如不可解释的系统。本文提出将用语言描述动作的任务作为辅助任务融入导航的强化学习中。由于缺乏ground-truth数据,现有研究发现很难将描述动作融入强化学习。我们通过利用预训练的描述生成模型(如视觉-语言模型)的知识蒸馏来解决这个问题。我们在各种导航任务中全面评估了我们的方法,证明了它可以在获得高导航性能的同时描述动作。此外,它在特别具有挑战性的语义视听导航多模态导航任务中实现了最先进的性能。
🔬 方法详解
问题定义:论文旨在解决具身导航系统中动作决策缺乏可解释性的问题。现有方法要么是黑盒模型,难以解释其决策过程;要么是可解释性较强但导航性能较差。缺乏ground-truth的动作描述数据是主要痛点。
核心思路:论文的核心思路是将动作描述预测作为一个辅助任务,与导航任务一起进行强化学习。通过让模型学习生成对自身动作的语言描述,从而提高模型的可解释性,同时利用多任务学习提升导航性能。
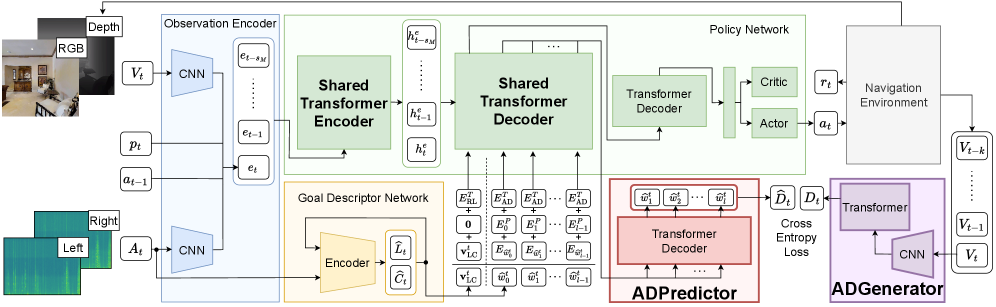
技术框架:整体框架包含一个导航模块和一个动作描述模块。导航模块负责根据环境信息选择动作,动作描述模块负责生成对所选动作的语言描述。这两个模块通过共享底层特征表示进行连接。利用预训练的视觉-语言模型进行知识蒸馏,为动作描述模块提供训练数据。
关键创新:最重要的技术创新点在于将动作描述预测作为辅助任务融入强化学习中,并利用知识蒸馏解决缺乏ground-truth数据的问题。这使得模型能够在获得高导航性能的同时,具备一定的可解释性。
关键设计:论文使用预训练的视觉-语言模型(如CLIP)提取视觉特征,并使用LSTM网络生成动作描述。损失函数包括导航任务的强化学习损失和动作描述预测的交叉熵损失。通过调整两个损失函数的权重,平衡导航性能和可解释性。
🖼️ 关键图片

📊 实验亮点
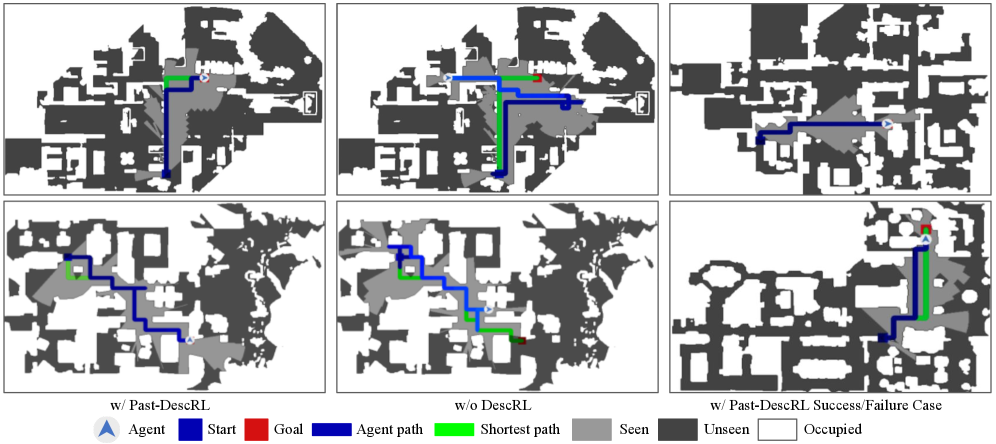
实验结果表明,该方法在多种导航任务中取得了良好的性能,尤其在具有挑战性的语义视听导航任务中,实现了state-of-the-art的性能。这表明该方法不仅能够提高导航性能,还能够提升系统的可解释性,使其更易于理解和信任。
🎯 应用场景
该研究成果可应用于各种需要人机协作的机器人导航场景,例如家庭服务机器人、医疗辅助机器人、工业巡检机器人等。通过提供可解释的动作决策,可以增强用户对机器人的信任感,提高人机协作效率,并降低潜在风险。
📄 摘要(原文)
The field of multimodal robot navigation in indoor environments has garnered significant attention in recent years. However, as tasks and methods become more advanced, the action decision systems tend to become more complex and operate as black-boxes. For a reliable system, the ability to explain or describe its decisions is crucial; however, there tends to be a trade-off in that explainable systems can not outperform non-explainable systems in terms of performance. In this paper, we propose incorporating the task of describing actions in language into the reinforcement learning of navigation as an auxiliary task. Existing studies have found it difficult to incorporate describing actions into reinforcement learning due to the absence of ground-truth data. We address this issue by leveraging knowledge distillation from pre-trained description generation models, such as vision-language models. We comprehensively evaluate our approach across various navigation tasks, demonstrating that it can describe actions while attaining high navigation performance. Furthermore, it achieves state-of-the-art performance in the particularly challenging multimodal navigation task of semantic audio-visual navigation.