Activating Visual Context and Commonsense Reasoning through Masked Prediction in VLMs
作者: Jiaao Yu, Shenwei Li, Mingjie Han, Yifei Yin, Wenzheng Song, Chenghao Jia, Man Lan
分类: cs.CV, cs.AI
发布日期: 2025-10-21
备注: 9 pages
💡 一句话要点
提出基于掩码预测的上下文常识激活方法,提升视觉语言模型在多模态场景下的推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 多模态推理 掩码预测 上下文学习 常识推理 强化微调 泛化能力 MPCC Eval
📋 核心要点
- 现有视觉语言模型在多模态推理方面存在不足,无法充分利用视觉上下文和常识知识。
- 论文提出基于上下文和常识的掩码预测微调任务,促使模型学习整合视觉信息和常识。
- 通过MPCC Eval基准测试和基于先验采样的强化微调,提升了模型在OOD和跨任务场景下的泛化推理能力。
📝 摘要(中文)
当前推理模型在大型语言模型中取得了显著进展,尤其是在可验证奖励的任务上。然而,由于过度关注单模态语言环境,它们在真实世界多模态场景(尤其是视觉语言任务)中的适应性仍然存在显著差距。尽管已经出现了将强化学习技术从自然语言处理移植到视觉语言模型中的尝试,但这些方法通常局限于以感知为中心的任务,或者将图像简化为文本摘要,未能充分利用视觉上下文和常识知识,最终限制了推理能力在不同多模态环境中的泛化。为了解决这一局限性,我们引入了一种新的微调任务,即基于上下文和常识的掩码预测,它通过重建被遮挡图像中语义上有意义的内容,迫使模型整合视觉上下文和常识推理,从而为广义推理奠定基础。为了系统地评估模型在广义推理中的性能,我们开发了一个专门的评估基准MPCC Eval,并采用各种微调策略来指导推理。其中,我们引入了一种创新的训练方法,即基于先验采样的强化微调,它不仅提高了模型性能,还提高了其在OOD和跨任务场景中的广义推理能力。
🔬 方法详解
问题定义:现有视觉语言模型(VLMs)在处理真实世界的多模态场景时,推理能力不足。主要痛点在于,现有方法要么过于依赖单模态语言环境,要么无法充分利用视觉上下文和常识知识,导致模型在复杂视觉语言任务中的泛化能力受限。已有的强化学习方法在VLMs上的应用,也常常局限于感知任务或将图像简化为文本,未能有效挖掘视觉信息的潜力。
核心思路:论文的核心思路是通过一种新的微调任务,迫使模型学习整合视觉上下文和常识知识。具体而言,通过掩码预测的方式,让模型根据周围的视觉信息和常识来重建被遮挡的图像内容。这种方式能够有效地激活模型对视觉信息的理解和推理能力,从而提升其在多模态场景下的泛化性能。
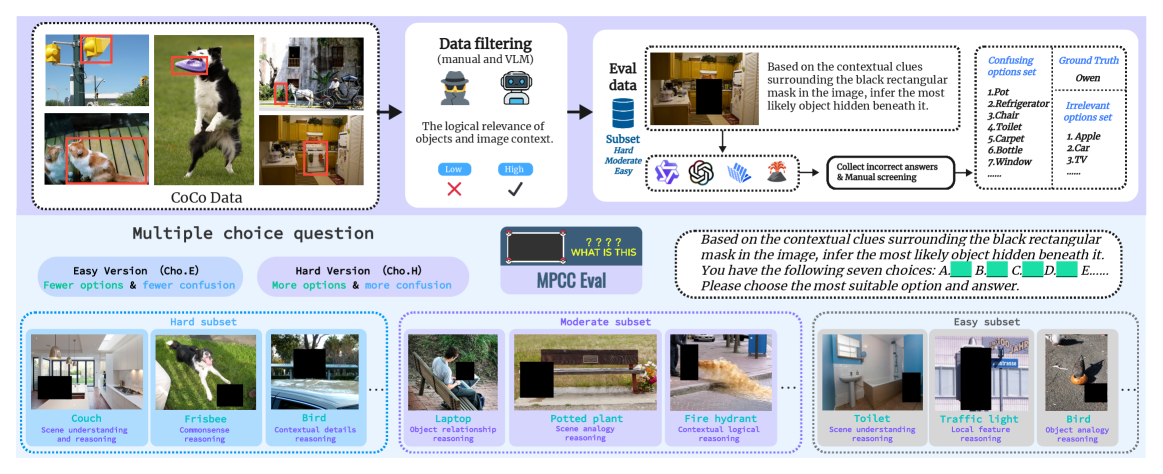
技术框架:整体框架包含两个主要部分:一是Masked Prediction via Context and Commonsense (MPCC)微调任务,二是MPCC Eval评估基准。MPCC微调任务通过遮挡图像的部分区域,并要求模型预测被遮挡的内容,从而训练模型整合视觉上下文和常识知识。MPCC Eval基准用于系统地评估模型在广义推理方面的性能,包括OOD(Out-of-Distribution)和跨任务场景。此外,论文还提出了一种基于先验采样的强化微调方法,进一步提升模型性能。
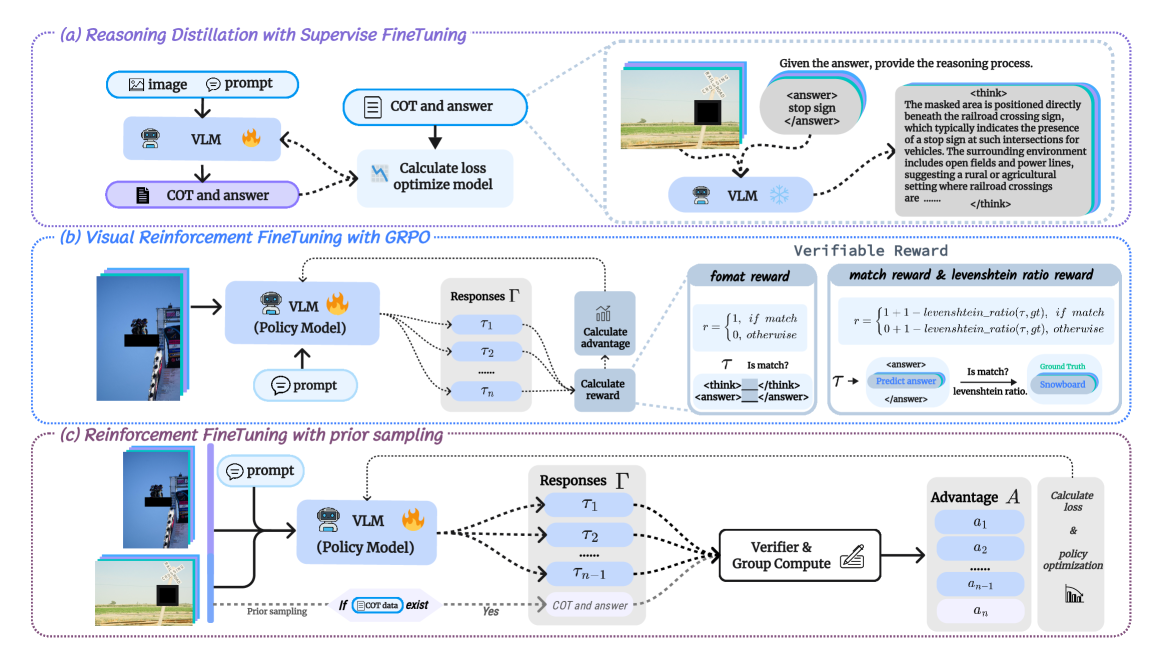
关键创新:论文的关键创新在于提出了MPCC微调任务和基于先验采样的强化微调方法。MPCC微调任务通过掩码预测的方式,有效地激活了模型对视觉上下文和常识知识的利用,而基于先验采样的强化微调方法则能够更好地指导模型的训练,提升其在复杂场景下的推理能力。与现有方法相比,该方法更注重视觉信息的利用,并能够更好地泛化到不同的多模态任务中。
关键设计:MPCC微调任务的关键设计在于如何选择被遮挡的区域以及如何设计预测目标。论文可能采用了语义分割或目标检测等技术来选择具有语义意义的区域进行遮挡,并使用交叉熵损失或类似的损失函数来衡量预测结果与真实标签之间的差距。基于先验采样的强化微调方法,可能使用了策略梯度算法或类似的强化学习算法,并根据模型在MPCC Eval上的表现来调整模型的参数。具体的参数设置、损失函数和网络结构等技术细节,需要参考论文原文。
🖼️ 关键图片

📊 实验亮点
论文提出了MPCC Eval评估基准,并在此基准上验证了所提出的微调方法的有效性。通过实验表明,基于上下文和常识的掩码预测微调以及基于先验采样的强化微调,能够显著提升模型在OOD和跨任务场景下的泛化推理能力。具体的性能提升数据(例如,在MPCC Eval上的准确率提升)需要在论文原文中查找。
🎯 应用场景
该研究成果可应用于智能机器人、自动驾驶、图像理解、视觉问答等领域。通过提升视觉语言模型的推理能力,可以使机器更好地理解真实世界的多模态信息,从而实现更智能、更可靠的应用。例如,在自动驾驶中,模型可以根据视觉信息和常识推理出周围环境的潜在风险,从而做出更安全的决策。
📄 摘要(原文)
Recent breakthroughs in reasoning models have markedly advanced the reasoning capabilities of large language models, particularly via training on tasks with verifiable rewards. Yet, a significant gap persists in their adaptation to real world multimodal scenarios, most notably, vision language tasks, due to a heavy focus on single modal language settings. While efforts to transplant reinforcement learning techniques from NLP to VLMs have emerged, these approaches often remain confined to perception centric tasks or reduce images to textual summaries, failing to fully exploit visual context and commonsense knowledge, ultimately constraining the generalization of reasoning capabilities across diverse multimodal environments. To address this limitation, we introduce a novel fine tuning task, Masked Prediction via Context and Commonsense, which forces models to integrate visual context and commonsense reasoning by reconstructing semantically meaningful content from occluded images, thereby laying the foundation for generalized reasoning. To systematically evaluate the model performance in generalized reasoning, we developed a specialized evaluation benchmark, MPCC Eval, and employed various fine tuning strategies to guide reasoning. Among these, we introduced an innovative training method, Reinforcement Fine tuning with Prior Sampling, which not only enhances model performance but also improves its generalized reasoning capabilities in OOD and cross task scenarios.