UniHPR: Unified Human Pose Representation via Singular Value Contrastive Learning
作者: Zhongyu Jiang, Wenhao Chai, Lei Li, Zhuoran Zhou, Cheng-Yen Yang, Jenq-Neng Hwang
分类: cs.CV
发布日期: 2025-10-21
💡 一句话要点
提出UniHPR,通过奇异值对比学习统一多模态人体姿态表征
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人体姿态估计 多模态融合 对比学习 奇异值分解 统一表示 跨模态学习 深度学习
📋 核心要点
- 现有人体姿态表示方法缺乏对多模态数据(图像、2D/3D姿态)的统一建模,限制了跨模态应用。
- UniHPR提出基于奇异值对比学习的统一框架,对齐不同模态的人体姿态嵌入,实现跨模态知识迁移。
- 实验表明,UniHPR在3D人体姿态估计和姿态检索任务上取得了显著的性能提升,验证了其有效性。
📝 摘要(中文)
近年来,开发有效的对齐流程以从不同模态生成统一表示,用于多模态融合和生成,受到了越来越多的关注。作为以人为中心的应用程序的重要组成部分,人体姿态表示在许多下游任务中至关重要,例如人体姿态估计、动作识别、人机交互、目标跟踪等。人体姿态表示或嵌入可以从图像、2D关键点、3D骨骼、网格模型和许多其他模态中提取。然而,使用对比学习范式明确研究所有这些表示之间的相关性的实例有限。在本文中,我们提出了UniHPR,一个统一的人体姿态表示学习流程,它对齐来自图像、2D和3D人体姿态的人体姿态嵌入。为了同时对齐两个以上的数据表示,我们提出了一种新颖的基于奇异值的对比学习损失,它可以更好地对齐不同的模态并进一步提高性能。为了评估对齐表示的有效性,我们选择2D和3D人体姿态估计(HPE)作为我们的评估任务。在我们的评估中,通过一个简单的3D人体姿态解码器,UniHPR在Human3.6M数据集上实现了显著的性能指标:MPJPE为49.9mm,在3DPW数据集上实现了PA-MPJPE为51.6mm,并进行了跨域评估。同时,我们能够在Human3.6M数据集中使用我们统一的人体姿态表示实现2D和3D姿态检索,其中MPJPE的检索误差为9.24mm。
🔬 方法详解
问题定义:现有的人体姿态表示方法通常针对特定模态设计,缺乏对图像、2D/3D姿态等多种模态信息的统一建模。这导致难以进行跨模态的人体姿态理解和应用,例如从图像预测3D姿态,或者利用2D姿态信息辅助3D姿态估计。现有方法难以有效利用不同模态之间的互补信息,限制了性能的进一步提升。
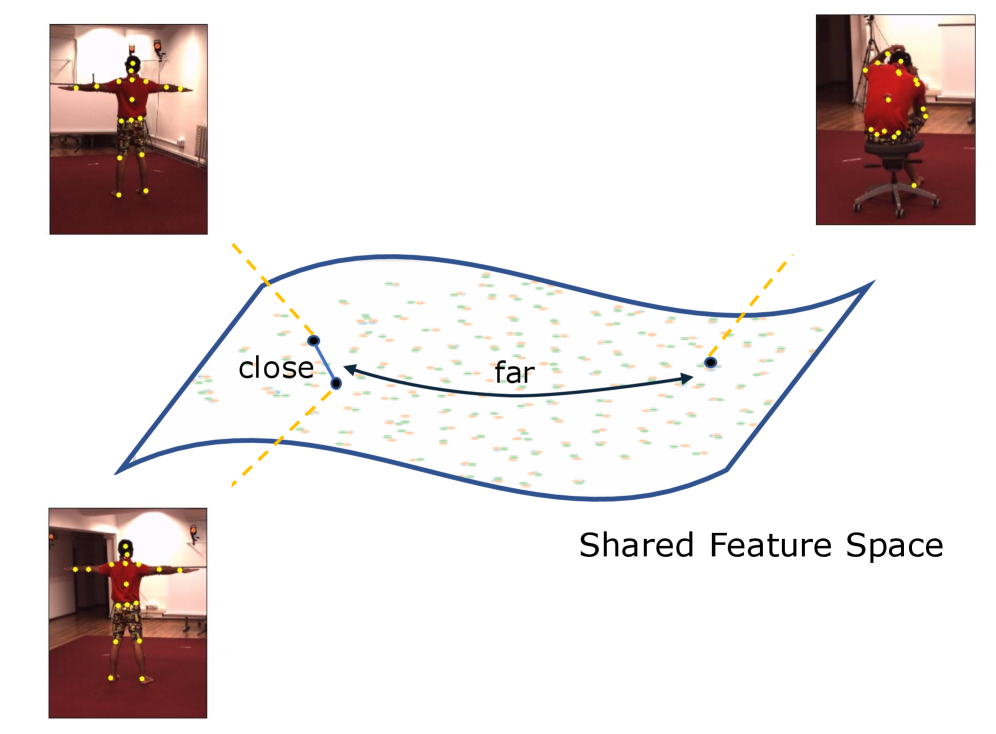
核心思路:UniHPR的核心思路是通过对比学习,将来自不同模态的人体姿态表示映射到一个统一的嵌入空间。在这个空间中,相同人体姿态的不同模态表示应该尽可能接近,而不同人体姿态的表示应该尽可能远离。通过这种方式,UniHPR能够学习到与模态无关的人体姿态表征,从而实现跨模态的知识迁移和融合。
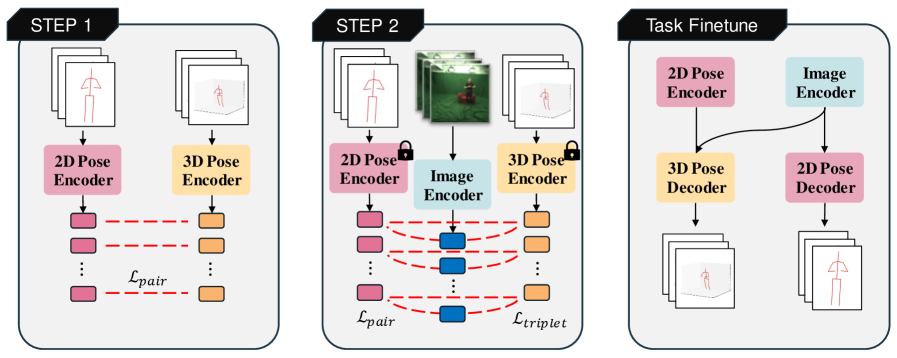
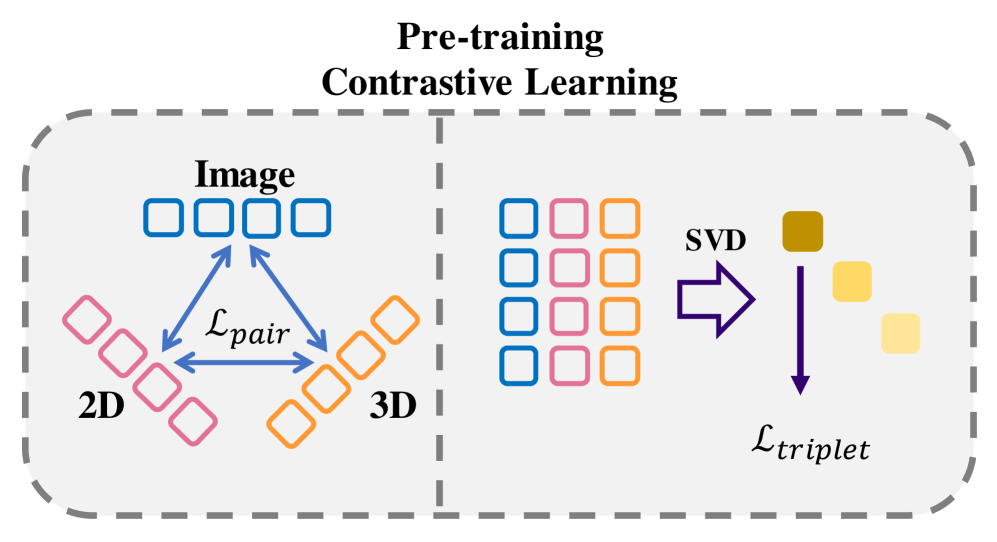
技术框架:UniHPR的整体框架包括三个主要模块:多模态特征提取器、统一嵌入空间和奇异值对比学习损失。首先,多模态特征提取器负责从图像、2D姿态和3D姿态中提取特征。然后,这些特征被映射到统一的嵌入空间。最后,使用奇异值对比学习损失来对齐不同模态的嵌入,使得相同姿态的不同模态表示尽可能接近,不同姿态的表示尽可能远离。
关键创新:UniHPR的关键创新在于提出了基于奇异值的对比学习损失。传统的对比学习损失通常只考虑两两样本之间的关系,而UniHPR利用奇异值分解来捕捉多个模态之间的全局关系。具体来说,它计算不同模态表示矩阵的奇异值,并最小化这些奇异值之间的差异。这种方法能够更好地对齐不同模态的表示,并提高模型的泛化能力。
关键设计:UniHPR的关键设计包括:1) 使用预训练的ResNet作为图像特征提取器;2) 使用MLP将2D/3D姿态映射到嵌入空间;3) 使用基于奇异值的对比学习损失,其中温度系数设置为0.07;4) 在Human3.6M和3DPW数据集上进行训练和评估。
🖼️ 关键图片
📊 实验亮点
UniHPR在Human3.6M数据集上取得了MPJPE 49.9mm的3D人体姿态估计结果,在3DPW数据集上取得了PA-MPJPE 51.6mm的结果,均优于现有方法。此外,UniHPR在Human3.6M数据集上实现了9.24mm的姿态检索误差,表明其学习到的统一姿态表示具有很强的区分能力。
🎯 应用场景
UniHPR具有广泛的应用前景,包括:1) 跨模态人体姿态估计,例如从图像预测3D姿态;2) 动作识别,利用统一的姿态表示提高识别准确率;3) 人机交互,实现更自然的人机交互体验;4) 虚拟现实/增强现实,为虚拟角色提供更逼真的人体姿态动画。该研究有助于推动以人为中心的AI技术发展。
📄 摘要(原文)
In recent years, there has been a growing interest in developing effective alignment pipelines to generate unified representations from different modalities for multi-modal fusion and generation. As an important component of Human-Centric applications, Human Pose representations are critical in many downstream tasks, such as Human Pose Estimation, Action Recognition, Human-Computer Interaction, Object tracking, etc. Human Pose representations or embeddings can be extracted from images, 2D keypoints, 3D skeletons, mesh models, and lots of other modalities. Yet, there are limited instances where the correlation among all of those representations has been clearly researched using a contrastive paradigm. In this paper, we propose UniHPR, a unified Human Pose Representation learning pipeline, which aligns Human Pose embeddings from images, 2D and 3D human poses. To align more than two data representations at the same time, we propose a novel singular value-based contrastive learning loss, which better aligns different modalities and further boosts performance. To evaluate the effectiveness of the aligned representation, we choose 2D and 3D Human Pose Estimation (HPE) as our evaluation tasks. In our evaluation, with a simple 3D human pose decoder, UniHPR achieves remarkable performance metrics: MPJPE 49.9mm on the Human3.6M dataset and PA-MPJPE 51.6mm on the 3DPW dataset with cross-domain evaluation. Meanwhile, we are able to achieve 2D and 3D pose retrieval with our unified human pose representations in Human3.6M dataset, where the retrieval error is 9.24mm in MPJPE.