PoSh: Using Scene Graphs To Guide LLMs-as-a-Judge For Detailed Image Descriptions
作者: Amith Ananthram, Elias Stengel-Eskin, Lorena A. Bradford, Julia Demarest, Adam Purvis, Keith Krut, Robert Stein, Rina Elster Pantalony, Mohit Bansal, Kathleen McKeown
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-10-21 (更新: 2025-12-05)
备注: 26 pages, 9 figures. Metric/benchmark available at https://github.com/amith-ananthram/posh
💡 一句话要点
提出PoSh,利用场景图引导LLM评估图像描述,并发布DOCENT数据集。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像描述评估 场景图 大型语言模型 DOCENT数据集 视觉-语言模型
📋 核心要点
- 现有图像描述评估指标难以准确评估长文本描述,尤其是在属性和关系理解方面存在不足。
- PoSh利用场景图作为结构化评估标准,引导LLM进行细粒度错误分析,从而实现更准确的图像描述评估。
- DOCENT数据集包含艺术品图像及专家描述,结合人类评估,为图像描述评估和模型训练提供新基准。
📝 摘要(中文)
视觉-语言模型(VLM)在图像描述方面取得了显著进展,但评估仍然是一个挑战。传统的评估指标(如CIDEr、SPICE)是为短文本设计的,并且主要识别现在已经不常见的错误,例如对象误识别。相比之下,长文本需要对属性和关系的依附关系更加敏感,并且需要能够将错误定位到特定文本范围内的分数。本文介绍了一种用于详细图像描述的指标PoSh,它使用场景图作为结构化的评估标准来引导LLM作为裁判,从而产生基于细粒度错误的聚合分数(例如,在组合理解方面的错误)。PoSh是可复制的、可解释的,并且比现有指标(包括GPT4o-as-a-Judge)更能代表人类评估者。为了验证PoSh,我们引入了一个具有挑战性的新数据集DOCENT。这个新基准包含艺术品,以及专家编写的参考描述和模型生成的描述,并附有艺术史学生对它们质量的细粒度和粗粒度判断。因此,DOCENT能够在一个具有挑战性的新领域中评估详细的图像描述指标和详细的图像描述本身。我们表明,PoSh在DOCENT中与人类判断的相关性(Spearman ρ +0.05)高于最佳的开源替代方案,对图像类型具有鲁棒性(使用CapArena,一个现有的网络图像数据集),并且是一个有能力的奖励函数,优于标准的监督微调。然后,使用PoSh,我们描述了开放和封闭模型在描述DOCENT中的绘画、素描和雕像方面的性能,并发现基础模型难以实现对具有丰富场景动态的图像的完整、无错误覆盖,从而建立了一个要求苛刻的新任务来衡量VLM的进展。通过PoSh和DOCENT,我们希望能够促进辅助文本生成等重要领域的进步。
🔬 方法详解
问题定义:现有图像描述评估指标,如CIDEr和SPICE,主要针对短文本设计,无法有效评估长文本描述中复杂的属性和关系理解错误。这些指标对细粒度的错误不够敏感,难以定位到具体的文本范围,并且与人类的判断一致性较差。因此,需要一种更准确、可解释且能反映人类判断的图像描述评估方法。
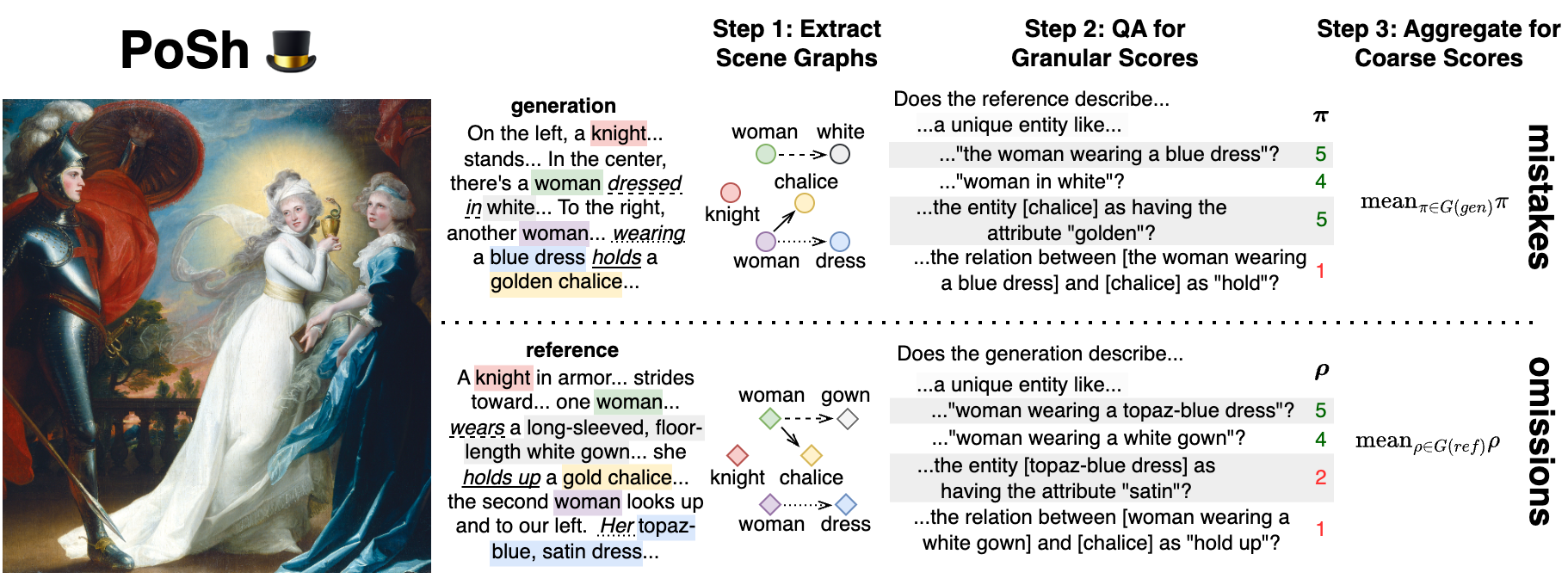
核心思路:PoSh的核心思路是利用场景图作为结构化的评估标准,引导大型语言模型(LLM)作为裁判,对图像描述进行细粒度的错误分析。场景图能够提供图像中对象、属性和关系的结构化表示,从而帮助LLM更准确地识别描述中的错误。通过将评估过程分解为对场景图各个部分的评估,PoSh能够提供可解释的评估结果,并定位到具体的错误位置。
技术框架:PoSh的整体框架包括以下几个主要模块:1) 场景图生成:使用现有的场景图生成模型从图像中提取场景图。2) LLM裁判:使用LLM作为裁判,根据场景图对图像描述进行评估。LLM被提示针对场景图中的每个节点和边,判断图像描述是否准确地描述了相应的对象、属性和关系。3) 分数聚合:将LLM的评估结果聚合为最终的评估分数。聚合过程可以根据不同的需求进行定制,例如,可以对不同的节点和边赋予不同的权重。
关键创新:PoSh最重要的技术创新点在于将场景图作为结构化的评估标准,引导LLM进行细粒度的错误分析。与传统的评估指标相比,PoSh能够更准确地评估长文本描述中复杂的属性和关系理解错误,并且提供可解释的评估结果。此外,PoSh还引入了DOCENT数据集,为图像描述评估和模型训练提供了一个新的基准。
关键设计:PoSh的关键设计包括:1) 场景图生成模型的选择:可以选择不同的场景图生成模型,例如,可以使用基于深度学习的模型或基于规则的模型。2) LLM的选择和提示工程:可以选择不同的LLM作为裁判,并设计合适的提示语,引导LLM进行准确的评估。3) 分数聚合方法:可以选择不同的分数聚合方法,例如,可以使用加权平均或最大池化。4) DOCENT数据集的构建:DOCENT数据集包含艺术品图像、专家编写的参考描述和模型生成的描述,并附有艺术史学生对它们质量的细粒度和粗粒度判断。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PoSh在DOCENT数据集上与人类判断的相关性(Spearman ρ +0.05)优于最佳的开源替代方案。PoSh还表现出对图像类型的鲁棒性,并且可以作为有效的奖励函数,优于标准的监督微调。此外,研究还发现,现有的基础模型在描述具有复杂场景动态的图像时,难以实现完整且无错误的覆盖。
🎯 应用场景
PoSh和DOCENT数据集可应用于辅助文本生成、图像检索、视觉问答等领域。通过更准确的图像描述评估,可以提高文本生成质量,改善图像检索效果,并提升视觉问答系统的性能。此外,该研究对于艺术领域也有潜在价值,可以帮助人们更好地理解和欣赏艺术作品。
📄 摘要(原文)
While vision-language models (VLMs) have advanced into detailed image description, evaluation remains a challenge. Standard metrics (e.g. CIDEr, SPICE) were designed for short texts and tuned to recognize errors that are now uncommon, such as object misidentification. In contrast, long texts require sensitivity to attribute and relation attachments and scores that localize errors to particular text spans. In this work, we introduce PoSh, a metric for detailed image description that uses scene graphs as structured rubrics to guide LLMs-as-a-Judge, producing aggregate scores grounded in fine-grained errors (e.g. mistakes in compositional understanding). PoSh is replicable, interpretable and a better proxy for human raters than existing metrics (including GPT4o-as-a-Judge). To validate PoSh, we introduce a challenging new dataset, DOCENT. This novel benchmark contains artwork, paired with expert-written references, and model-generated descriptions, augmented with granular and coarse judgments of their quality from art history students. Thus, DOCENT enables evaluating both detailed image description metrics and detailed image description itself in a challenging new domain. We show that PoSh achieves stronger correlations (+0.05 Spearman $ρ$) with the human judgments in DOCENT than the best open-weight alternatives, is robust to image type (using CapArena, an existing dataset of web imagery) and is a capable reward function, outperforming standard supervised fine-tuning. Then, using PoSh, we characterize the performance of open and closed models in describing the paintings, sketches and statues in DOCENT and find that foundation models struggle to achieve full, error-free coverage of images with rich scene dynamics, establishing a demanding new task to gauge VLM progress. Through both PoSh and DOCENT, we hope to enable advances in important areas such as assistive text generation.