Grasp Any Region: Towards Precise, Contextual Pixel Understanding for Multimodal LLMs
作者: Haochen Wang, Yuhao Wang, Tao Zhang, Yikang Zhou, Yanwei Li, Jiacong Wang, Jiani Zheng, Ye Tian, Jiahao Meng, Zilong Huang, Guangcan Mai, Anran Wang, Yunhai Tong, Zhuochen Wang, Xiangtai Li, Zhaoxiang Zhang
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-10-21 (更新: 2025-10-22)
💡 一句话要点
提出GAR以解决多模态大语言模型的区域理解问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 区域理解 RoI对齐 特征重放 组合推理 视频理解 智能监控 人机交互
📋 核心要点
- 现有多模态大语言模型在复杂场景的细节分析和对象关系捕捉方面存在不足,主要集中于孤立区域的理解。
- 本文提出的GAR通过RoI对齐特征重放技术,实现了区域级视觉理解,强调全局上下文和多提示间的交互。
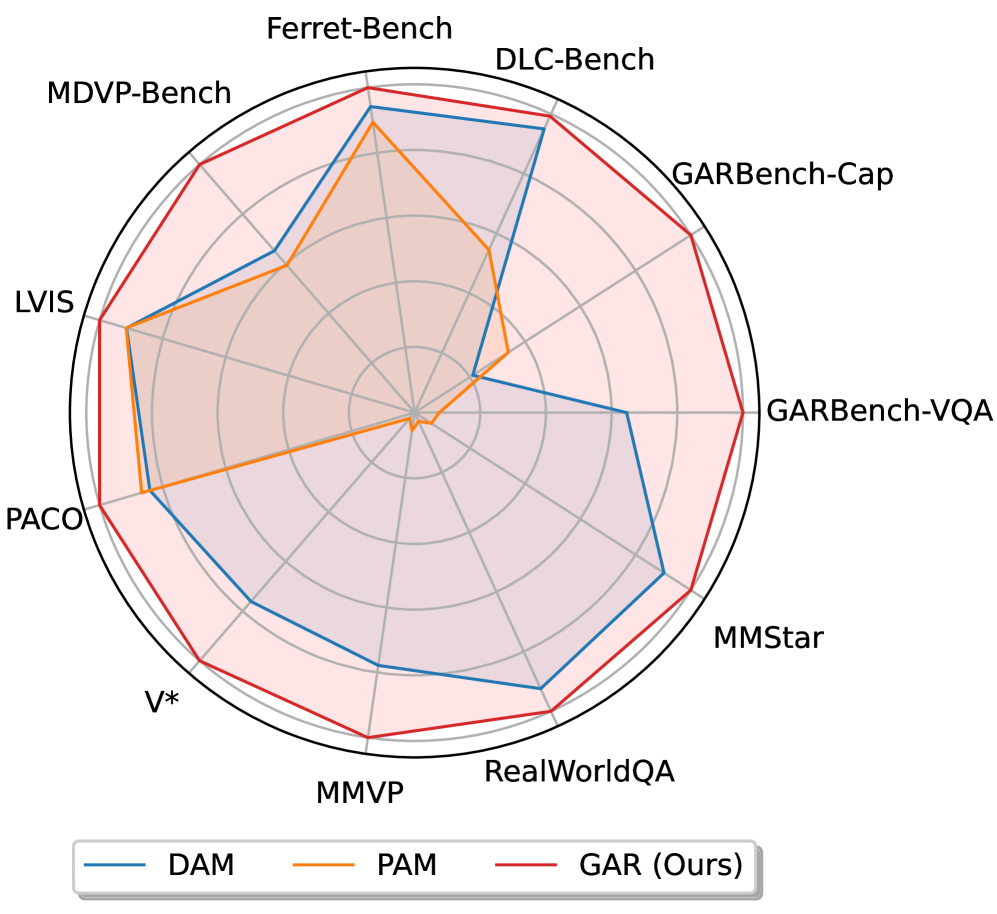
- 实验结果显示,GAR-1B在图像描述能力上超越了现有基线,并在多提示关系建模上表现优异,GAR-8B在视频任务中也展现了强大的迁移能力。
📝 摘要(中文)
尽管多模态大语言模型(MLLMs)在整体理解方面表现优异,但在捕捉复杂场景的细节和对象间关系时仍显不足。区域级MLLMs是一个有前景的方向,但以往方法通常孤立地理解给定区域,忽视了重要的全局上下文。为此,本文提出了Grasp Any Region(GAR),通过有效的RoI对齐特征重放技术,支持精确感知和多提示间的交互建模,从而实现高级组合推理。GAR-Bench的构建不仅提供了单区域理解的准确评估,还衡量了多个区域间的交互和复杂推理。实验表明,GAR-1B在图像描述能力上超越了DAM-3B,并在多提示关系建模上表现出色,GAR-8B在视频理解上也优于VideoRefer-7B。
🔬 方法详解
问题定义:本文旨在解决多模态大语言模型在复杂场景中对区域理解的不足,现有方法往往忽视全局上下文,导致理解能力受限。
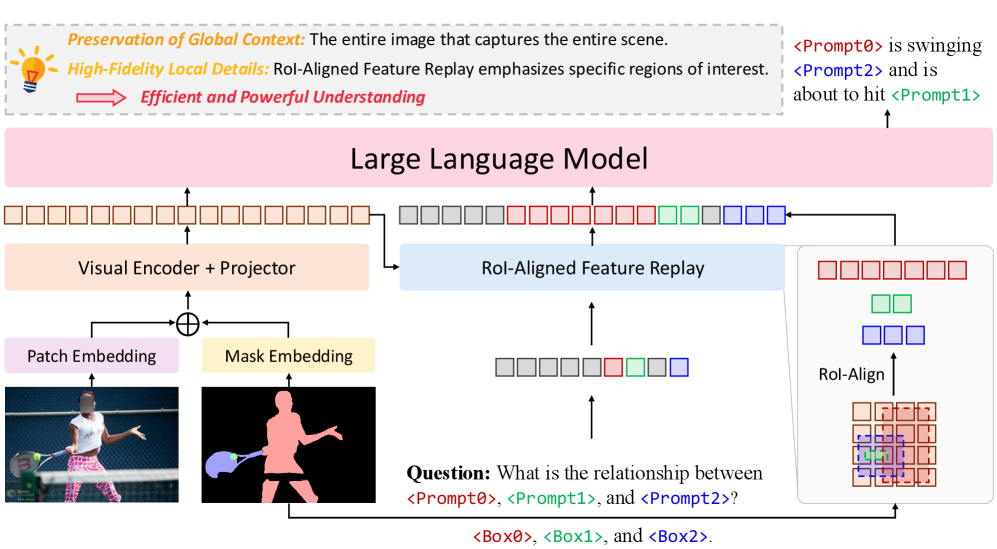
核心思路:GAR通过引入RoI对齐特征重放技术,增强了模型对全局上下文的利用,同时支持多提示间的交互建模,从而实现更精确的区域理解和推理能力。
技术框架:GAR的整体架构包括特征提取、RoI对齐、特征重放和推理模块。特征提取负责从输入图像中提取视觉特征,RoI对齐确保特征与区域的精确对应,特征重放则用于增强全局上下文的利用,最后的推理模块实现对特定问题的回答。
关键创新:GAR的主要创新在于其有效的RoI对齐特征重放技术,使得模型能够在理解区域时充分考虑全局信息和多提示间的关系,这与以往孤立理解区域的方法形成鲜明对比。
关键设计:在模型设计中,GAR采用了特定的损失函数以优化区域理解的准确性,同时在网络结构上引入了多层次的特征融合机制,以增强模型的推理能力。通过这些设计,GAR在处理复杂场景时表现出色。
🖼️ 关键图片

📊 实验亮点
GAR-1B在DLC-Bench上超越了DAM-3B,提升幅度达到4.5分,同时在GAR-Bench-VQA上超越了InternVL3-78B,展现出卓越的多提示关系建模能力。此外,GAR-8B在VideoRefer-BenchQ上超越了VideoRefer-7B,显示出其强大的迁移能力。
🎯 应用场景
GAR的研究成果在多个领域具有广泛的应用潜力,包括智能监控、自动驾驶、机器人视觉和人机交互等。通过提升多模态理解能力,GAR能够帮助系统更好地理解和处理复杂环境中的信息,从而提高决策和响应的准确性。未来,GAR的技术也可能推动视频理解和分析的进步,拓展其在动态场景中的应用价值。
📄 摘要(原文)
While Multimodal Large Language Models (MLLMs) excel at holistic understanding, they struggle in capturing the dense world with complex scenes, requiring fine-grained analysis of intricate details and object inter-relationships. Region-level MLLMs have been a promising step. However, previous attempts are generally optimized to understand given regions in isolation, neglecting crucial global contexts. To address this, we introduce Grasp Any Region (GAR) for comprehen- sive region-level visual understanding. Empowered by an effective RoI-aligned feature replay technique, GAR supports (1) precise perception by leveraging necessary global contexts, and (2) modeling interactions between multiple prompts. Together, it then naturally achieves (3) advanced compositional reasoning to answer specific free-form questions about any region, shifting the paradigm from passive description to active dialogue. Moreover, we construct GAR-Bench, which not only provides a more accurate evaluation of single-region comprehension, but also, more importantly, measures interactions and complex reasoning across multiple regions. Extensive experiments have demonstrated that GAR-1B not only maintains the state-of-the-art captioning capabilities, e.g., outperforming DAM-3B +4.5 on DLC-Bench, but also excels at modeling relationships between multiple prompts with advanced comprehension capabilities, even surpassing InternVL3-78B on GAR-Bench-VQA. More importantly, our zero-shot GAR-8B even outperforms in-domain VideoRefer-7B on VideoRefer-BenchQ, indicating its strong capabilities can be easily transferred to videos.