DSI-Bench: A Benchmark for Dynamic Spatial Intelligence
作者: Ziang Zhang, Zehan Wang, Guanghao Zhang, Weilong Dai, Yan Xia, Ziang Yan, Minjie Hong, Zhou Zhao
分类: cs.CV
发布日期: 2025-10-21
💡 一句话要点
提出DSI-Bench基准测试,用于评估动态空间智能,揭示现有VLM在3D动态场景理解上的局限性。
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting)
关键词: 动态空间智能 视觉语言模型 基准测试 3D场景理解 运动推理
📋 核心要点
- 现有视觉语言模型(VLM)在2D和静态场景表现出色,但在理解动态3D场景方面存在不足,无法充分理解观察者和物体的同步运动。
- 论文提出DSI-Bench基准,包含大量动态视频和问题,覆盖多种运动模式,旨在系统评估模型在动态空间推理方面的能力。
- 实验评估了14个VLM和专家模型,揭示了模型在区分观察者和物体运动、避免语义偏差以及推断动态相对关系方面的局限性。
📝 摘要(中文)
本文提出了动态空间智能的概念,并为此构建了一个名为DSI-Bench的基准测试。该基准包含近1000个动态视频和超过1700个手动标注的问题,涵盖了观察者和物体的九种解耦运动模式。通过空间和时间上的对称设计,减少了偏差,并能够系统地评估模型对自身运动和物体运动的推理能力。对14个视觉语言模型(VLM)和专家模型的评估表明,这些模型存在关键局限性:容易混淆观察者和物体的运动,表现出语义偏差,并且无法准确推断动态场景中的相对关系。DSI-Bench为动态空间智能的通用模型和专家模型的未来发展提供了有价值的发现和见解。
🔬 方法详解
问题定义:现有视觉语言模型和视觉专家模型在处理静态2D场景时表现良好,但在理解动态3D场景,特别是涉及观察者和物体同时运动时,能力不足。这些模型难以准确区分观察者和物体的运动,容易受到语义偏差的影响,并且无法有效地推断动态场景中的相对空间关系。因此,需要一个专门的基准来评估模型在动态空间智能方面的能力。
核心思路:论文的核心思路是构建一个包含丰富动态场景的基准测试,该基准需要覆盖多种观察者和物体的运动模式,并且在空间和时间上保持对称性,以减少偏差。通过对模型在基准上的表现进行系统评估,可以揭示模型在动态空间推理方面的优势和不足,从而指导未来的模型设计和训练。
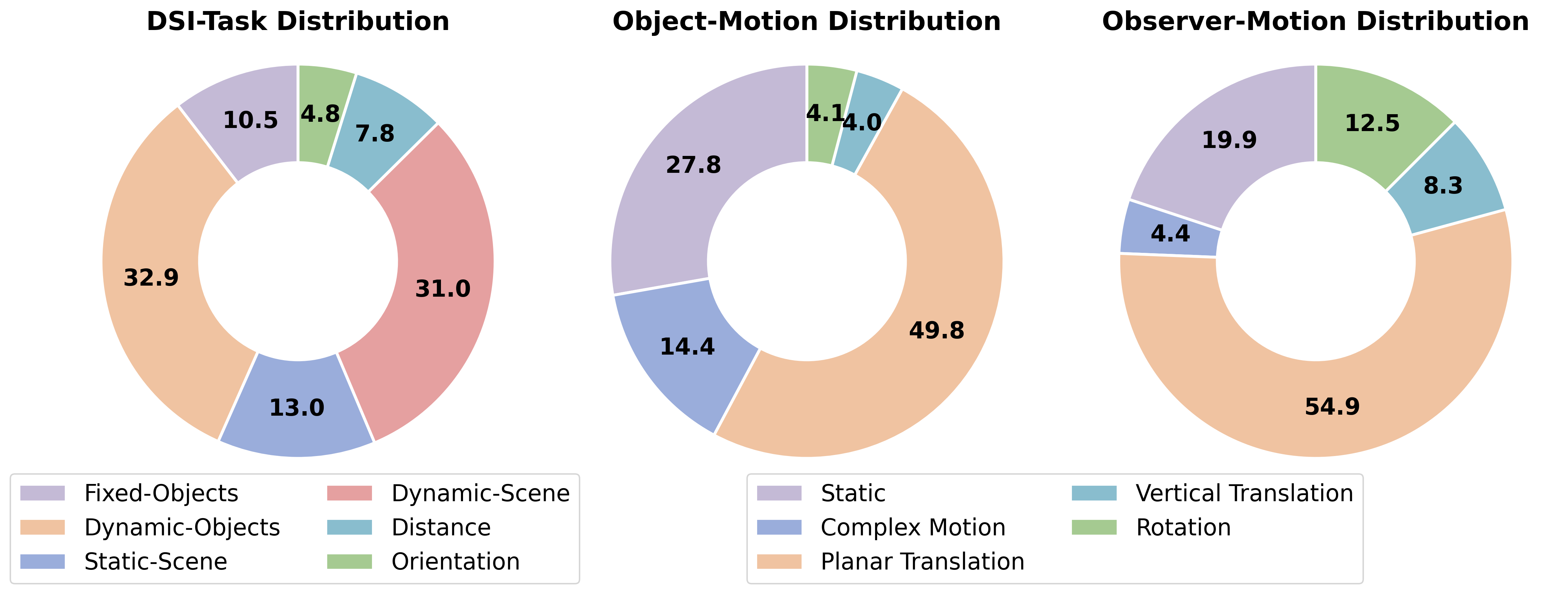
技术框架:DSI-Bench基准测试包含以下几个关键组成部分:1) 动态视频数据集:包含近1000个动态视频,涵盖了观察者和物体的九种解耦运动模式。2) 手动标注的问题:每个视频都配有多个手动标注的问题,用于评估模型对动态空间关系的理解。3) 评估指标:用于衡量模型在回答问题时的准确性和鲁棒性。整体流程是,给定一个动态视频和相关问题,模型需要输出答案,然后根据评估指标对模型的性能进行评估。
关键创新:DSI-Bench的关键创新在于其对动态空间智能的关注以及对基准测试的精心设计。具体来说,它首次提出了动态空间智能的概念,并构建了一个专门用于评估该能力的基准。该基准在运动模式的选择、视频的生成以及问题的标注方面都进行了精心的设计,以确保其能够全面、准确地评估模型的动态空间推理能力。与现有基准相比,DSI-Bench更加关注动态场景,并且在设计上更加注重减少偏差。
关键设计:DSI-Bench的关键设计包括:1) 运动模式的选择:选择了九种解耦的观察者和物体运动模式,以覆盖不同的动态场景。2) 视频的生成:使用程序化生成方法生成视频,以确保视频的多样性和可控性。3) 问题的标注:手动标注问题,以确保问题的质量和相关性。4) 空间和时间对称性:在设计上考虑了空间和时间对称性,以减少偏差。具体的技术细节包括视频的分辨率、帧率、运动速度等参数的设置,以及问题的类型和难度等方面的考虑。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有VLM在DSI-Bench上的表现远低于人类水平,表明其在动态空间推理方面存在显著不足。具体来说,模型在区分观察者和物体运动、避免语义偏差以及推断动态相对关系方面都表现出明显的局限性。例如,模型经常混淆观察者和物体的运动方向,导致错误的推理结果。这些发现为未来的模型设计和训练提供了重要的指导。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、视频监控、增强现实等领域。通过提升模型对动态空间关系的理解能力,可以使机器人在复杂环境中更好地感知和行动,提高其自主性和适应性。未来,该基准可以促进更强大的动态空间智能模型的开发,从而推动相关领域的技术进步。
📄 摘要(原文)
Reasoning about dynamic spatial relationships is essential, as both observers and objects often move simultaneously. Although vision-language models (VLMs) and visual expertise models excel in 2D tasks and static scenarios, their ability to fully understand dynamic 3D scenarios remains limited. We introduce Dynamic Spatial Intelligence and propose DSI-Bench, a benchmark with nearly 1,000 dynamic videos and over 1,700 manually annotated questions covering nine decoupled motion patterns of observers and objects. Spatially and temporally symmetric designs reduce biases and enable systematic evaluation of models' reasoning about self-motion and object motion. Our evaluation of 14 VLMs and expert models reveals key limitations: models often conflate observer and object motion, exhibit semantic biases, and fail to accurately infer relative relationships in dynamic scenarios. Our DSI-Bench provides valuable findings and insights about the future development of general and expertise models with dynamic spatial intelligence.