See the Text: From Tokenization to Visual Reading
作者: Ling Xing, Alex Jinpeng Wang, Rui Yan, Hongyu Qu, Zechao Li, Jinhui Tang
分类: cs.CV, cs.CL
发布日期: 2025-10-21
💡 一句话要点
提出SeeTok,将文本视为图像,利用多模态LLM实现高效视觉阅读理解。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 多模态学习 低资源语言处理 OCR 文本图像 视觉阅读 跨语言泛化
📋 核心要点
- 现有LLM依赖子词分词,对低资源语言过度分割,产生长且无意义的序列,增加计算负担。
- SeeTok将文本视为图像,利用多模态LLM的视觉理解能力,无需传统分词,更接近人类阅读方式。
- 实验表明,SeeTok在减少计算量的同时,性能与子词分词器相当甚至更好,并提升了跨语言泛化能力。
📝 摘要(中文)
本文挑战了现有大语言模型(LLMs)依赖于子词分词的范式,提出了一种以视觉为中心的方法SeeTok。SeeTok将文本渲染为图像(visual-text),并利用预训练的多模态LLMs来解释它们,复用从大规模多模态训练中学习到的强大的OCR和文本-视觉对齐能力。在三个不同的语言任务中,SeeTok在需要减少4.43倍的tokens和降低70.5%的FLOPs的情况下,匹配或超过了子词分词器的性能,并在跨语言泛化、对印刷噪声的鲁棒性和语言层次结构方面获得了额外的收益。SeeTok标志着从符号分词到类人视觉阅读的转变,并朝着更自然和认知启发的语言模型迈出了一步。
🔬 方法详解
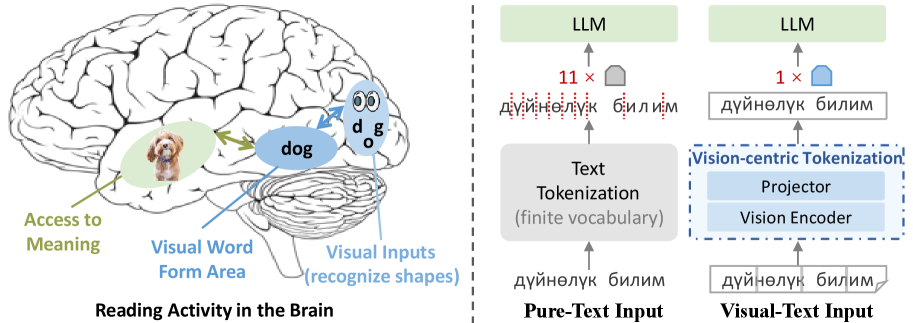
问题定义:现有大语言模型主要依赖于子词分词技术处理文本,这种方法将文本分解成固定词汇表中的片段。虽然对于高资源语言有效,但对于低资源语言,这种方法会导致过度分割,产生冗长且语言意义不明确的序列,从而增加计算成本。此外,这种方法缺乏对文本视觉特征的直接利用,与人类的阅读方式存在差异。
核心思路:SeeTok的核心思路是将文本视为图像,利用预训练的多模态大语言模型(MLLMs)的视觉理解能力来处理文本。通过将文本渲染成图像,模型可以直接利用图像处理技术,例如OCR,来识别文本内容,并利用文本-视觉对齐能力来理解文本的语义。这种方法避免了传统的分词步骤,从而减少了token的数量和计算量。
技术框架:SeeTok的整体框架包括两个主要步骤:1) 文本渲染:将输入的文本渲染成图像,生成visual-text。可以使用各种字体、大小和样式来渲染文本,以增加模型的鲁棒性。2) 多模态LLM处理:将生成的visual-text输入到预训练的多模态LLM中进行处理。MLLM利用其视觉编码器提取图像特征,并利用其语言模型生成文本输出。整个过程无需显式分词。
关键创新:SeeTok最重要的创新点在于它将文本处理从传统的符号分词范式转变为视觉阅读范式。与现有方法相比,SeeTok直接利用文本的视觉信息,避免了分词带来的信息损失和计算负担。此外,SeeTok还能够更好地处理印刷噪声和跨语言文本,因为它依赖于视觉特征而不是语言规则。
关键设计:SeeTok的关键设计包括:1) 文本渲染策略:选择合适的字体、大小和样式来渲染文本,以增加模型的鲁棒性。2) 多模态LLM的选择:选择具有强大的OCR和文本-视觉对齐能力的预训练MLLM。3) 训练策略:可以使用对比学习或生成式学习来训练MLLM,以提高其视觉理解能力。具体的损失函数和网络结构取决于所选择的MLLM。
🖼️ 关键图片

📊 实验亮点
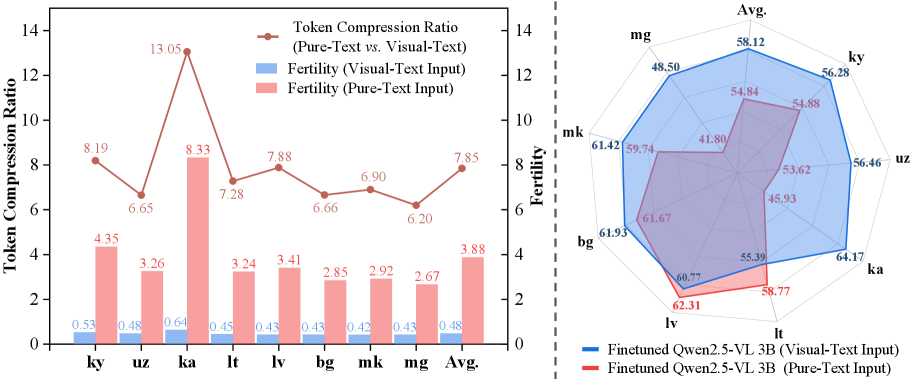
SeeTok在三个不同的语言任务中,在token数量减少4.43倍和FLOPs降低70.5%的情况下,性能匹配或超过了子词分词器。此外,SeeTok在跨语言泛化、对印刷噪声的鲁棒性和语言层次结构方面也表现出优势。这些结果表明SeeTok是一种高效且通用的文本处理方法。
🎯 应用场景
SeeTok具有广泛的应用前景,包括低资源语言处理、跨语言信息检索、文档图像理解、以及对印刷错误或噪声文本的鲁棒性处理。它还可以应用于开发更自然和认知启发的语言模型,提升人机交互体验。未来,SeeTok有望推动多模态学习和视觉语言理解领域的发展。
📄 摘要(原文)
People see text. Humans read by recognizing words as visual objects, including their shapes, layouts, and patterns, before connecting them to meaning, which enables us to handle typos, distorted fonts, and various scripts effectively. Modern large language models (LLMs), however, rely on subword tokenization, fragmenting text into pieces from a fixed vocabulary. While effective for high-resource languages, this approach over-segments low-resource languages, yielding long, linguistically meaningless sequences and inflating computation. In this work, we challenge this entrenched paradigm and move toward a vision-centric alternative. Our method, SeeTok, renders text as images (visual-text) and leverages pretrained multimodal LLMs to interpret them, reusing strong OCR and text-vision alignment abilities learned from large-scale multimodal training. Across three different language tasks, SeeTok matches or surpasses subword tokenizers while requiring 4.43 times fewer tokens and reducing FLOPs by 70.5%, with additional gains in cross-lingual generalization, robustness to typographic noise, and linguistic hierarchy. SeeTok signals a shift from symbolic tokenization to human-like visual reading, and takes a step toward more natural and cognitively inspired language models.