Think with 3D: Geometric Imagination Grounded Spatial Reasoning from Limited Views
作者: Zhangquan Chen, Manyuan Zhang, Xinlei Yu, Xufang Luo, Mingze Sun, Zihao Pan, Yan Feng, Peng Pei, Xunliang Cai, Ruqi Huang
分类: cs.CV, cs.AI
发布日期: 2025-10-21
备注: 12 pages, 4 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出3DThinker,从有限视角实现基于几何想象的空间推理
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D空间推理 视觉-语言模型 几何信息 3D心智建模 多模态学习
📋 核心要点
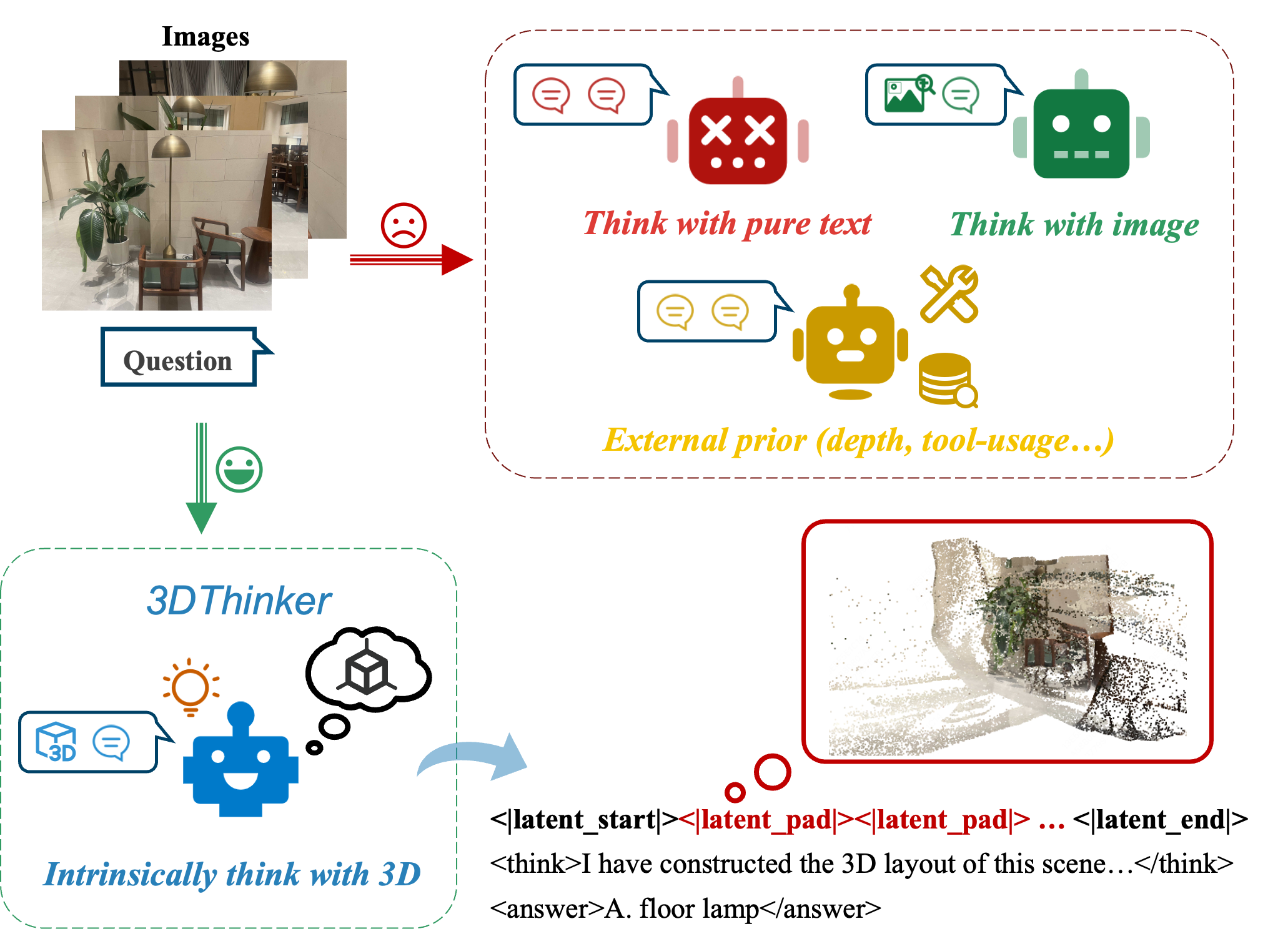
- 现有方法在理解有限视角下的3D空间关系时,依赖文本或2D线索,缺乏3D空间想象能力。
- 3DThinker通过在推理过程中利用图像中的几何信息,实现无需3D先验知识的3D心智建模。
- 实验表明,3DThinker在多个基准测试中优于现有方法,为多模态推理融合3D表示提供了新思路。
📝 摘要(中文)
尽管视觉-语言模型(VLM)在多模态任务中取得了显著进展,但从有限视角理解3D空间关系仍然是一个重大挑战。以往的推理方法通常依赖于纯文本(如拓扑认知地图)或2D视觉线索,其有限的表征能力阻碍了在需要3D空间想象的特定任务中的性能。为了解决这一局限性,我们提出了3DThinker,该框架能够像人类一样,在推理时有效地利用图像中嵌入的丰富几何信息。我们的框架是第一个在没有任何3D先验输入的情况下,在推理过程中实现3D心智建模的框架,并且不依赖于显式标记的3D数据进行训练。具体来说,我们的训练包括两个阶段。首先,我们执行监督训练,以对齐VLM在推理时生成的3D潜在空间与3D基础模型(如VGGT)的3D潜在空间。然后,我们仅基于结果信号优化整个推理轨迹,从而改进底层的3D心智建模。在多个基准上的大量实验表明,3DThinker始终优于强大的基线,并为将3D表示统一到多模态推理中提供了一个新的视角。我们的代码将在https://github.com/zhangquanchen/3DThinker上提供。
🔬 方法详解
问题定义:论文旨在解决视觉-语言模型在有限视角下进行3D空间关系推理的难题。现有方法主要依赖于文本或2D视觉信息,缺乏对3D几何信息的有效利用,导致在需要空间想象的任务中表现不佳。这些方法无法像人类一样,仅凭有限的视角就能构建对3D场景的理解和推理。
核心思路:论文的核心思路是让模型在推理过程中进行3D心智建模,即模拟人类在头脑中构建3D场景的能力。通过学习图像中蕴含的几何信息,模型能够在没有显式3D数据的情况下,生成对场景的3D理解,从而提升空间推理能力。这种方法模拟了人类的认知过程,更符合直觉。
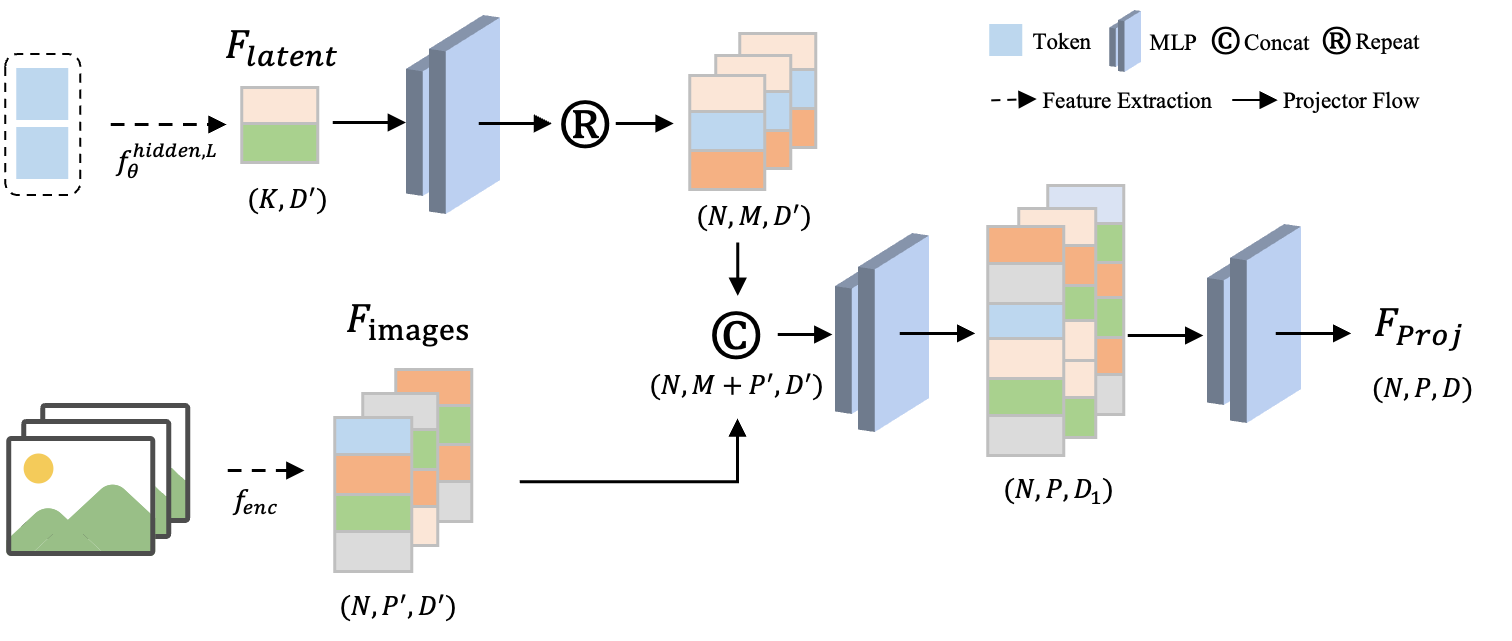
技术框架:3DThinker框架包含两个主要的训练阶段。第一阶段是监督训练,目的是将视觉-语言模型(VLM)在推理过程中生成的3D潜在空间与3D基础模型(如VGGT)的3D潜在空间对齐。这使得VLM能够学习到有效的3D表示。第二阶段是基于结果信号的优化,即仅根据推理结果来调整整个推理轨迹,从而进一步提升3D心智建模的能力。整个框架无需显式3D标注数据。
关键创新:该论文的关键创新在于提出了一个无需3D先验知识,也无需显式3D标注数据,即可进行3D心智建模的框架。这是首次尝试在推理过程中引入3D mentaling,并将其与视觉-语言模型相结合。与现有方法相比,3DThinker能够更好地利用图像中的几何信息,从而提升空间推理能力。
关键设计:在第一阶段的监督训练中,使用了对比学习损失来对齐VLM和3D基础模型的3D潜在空间。在第二阶段的优化中,使用了强化学习或类似的策略梯度方法,根据推理结果来调整模型的参数。具体的网络结构和参数设置取决于所使用的VLM和3D基础模型,但核心思想是利用这两个阶段的训练来提升模型的3D理解和推理能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,3DThinker在多个空间推理基准测试中显著优于现有方法。具体性能提升幅度未知,但论文强调了其在多个基准测试中表现的一致性超越,证明了3D心智建模在空间推理中的有效性。该方法无需3D数据训练,更具实用性。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、虚拟现实、增强现实等领域。例如,机器人可以在仅有少量视觉信息的情况下,更好地理解周围环境,进行路径规划和物体操作。在VR/AR中,可以提升用户与虚拟环境的交互体验,使其更加自然和真实。该研究为多模态智能体理解和操作3D世界提供了新的思路。
📄 摘要(原文)
Though recent advances in vision-language models (VLMs) have achieved remarkable progress across a wide range of multimodal tasks, understanding 3D spatial relationships from limited views remains a significant challenge. Previous reasoning methods typically rely on pure text (e.g., topological cognitive maps) or on 2D visual cues. However, their limited representational capacity hinders performance in specific tasks that require 3D spatial imagination. To address this limitation, we propose 3DThinker, a framework that can effectively exploits the rich geometric information embedded within images while reasoning, like humans do. Our framework is the first to enable 3D mentaling during reasoning without any 3D prior input, and it does not rely on explicitly labeled 3D data for training. Specifically, our training consists of two stages. First, we perform supervised training to align the 3D latent generated by VLM while reasoning with that of a 3D foundation model (e.g., VGGT). Then, we optimize the entire reasoning trajectory solely based on outcome signals, thereby refining the underlying 3D mentaling. Extensive experiments across multiple benchmarks show that 3DThinker consistently outperforms strong baselines and offers a new perspective toward unifying 3D representations into multimodal reasoning. Our code will be available at https://github.com/zhangquanchen/3DThinker.