Vision Foundation Models Can Be Good Tokenizers for Latent Diffusion Models
作者: Tianci Bi, Xiaoyi Zhang, Yan Lu, Nanning Zheng
分类: cs.CV, cs.LG
发布日期: 2025-10-21 (更新: 2025-11-03)
备注: v2 note: Corrected numerical values in Table 2 and Figure 4 due to a minor calculation error in v1. The overall conclusions remain unchanged. Code and models available at: https://github.com/tianciB/VFM-VAE
💡 一句话要点
提出VFM-VAE,直接利用视觉基础模型作为潜在扩散模型的tokenizer,显著提升生成质量与效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 潜在扩散模型 视觉基础模型 变分自编码器 图像生成 多尺度融合
📋 核心要点
- 现有方法通过蒸馏将视觉基础模型(VFM)集成到潜在扩散模型(LDM)中,但蒸馏过程会降低与原始VFM的对齐鲁棒性。
- 提出VFM-VAE,一种直接利用VFM特征的变分自编码器,避免了蒸馏过程,从而保持了与VFM的语义一致性。
- 通过多尺度潜在融合和渐进式分辨率重建,VFM-VAE能够从粗糙的VFM特征中实现高质量的图像重建,并加速模型收敛。
📝 摘要(中文)
潜在扩散模型(LDMs)的性能严重依赖于其视觉tokenizer的质量。虽然最近的工作探索了通过蒸馏来整合视觉基础模型(VFMs),但我们发现这种方法存在一个根本缺陷:它不可避免地削弱了与原始VFM对齐的鲁棒性,导致对齐的潜在变量在分布偏移下产生语义偏差。在本文中,我们通过提出一种更直接的方法来绕过蒸馏:视觉基础模型变分自编码器(VFM-VAE)。为了解决VFM的语义关注点与像素级保真度需求之间的内在张力,我们重新设计了VFM-VAE解码器,采用多尺度潜在融合和渐进式分辨率重建块,从而能够从空间粗糙的VFM特征中实现高质量重建。此外,我们对扩散训练期间的表示动态进行了全面分析,引入了提出的SE-CKNNA指标作为更精确的诊断工具。这种分析使我们能够开发一种联合tokenizer-diffusion对齐策略,从而大大加快了收敛速度。我们在tokenizer设计和训练策略方面的创新带来了卓越的性能和效率:我们的系统仅在80个epoch内就达到了2.20的gFID(无CFG)(比之前的tokenizer快10倍)。通过继续训练到640个epoch,它进一步达到了1.62的gFID(无CFG),从而确立了直接VFM集成作为LDM的卓越范例。
🔬 方法详解
问题定义:现有潜在扩散模型(LDM)的视觉tokenizer通常采用独立的训练方式,与视觉基础模型(VFM)的语义信息关联较弱。通过蒸馏方式将VFM融入tokenizer虽然可行,但会损失VFM的语义表达能力,导致生成图像在分布偏移下出现语义偏差。因此,如何有效利用VFM的强大语义表征能力,同时保证图像重建质量,是本文要解决的关键问题。
核心思路:本文的核心思路是直接将VFM作为LDM的tokenizer,避免蒸馏过程带来的信息损失。为了解决VFM特征的空间粗糙性与图像像素级重建需求之间的矛盾,设计了专门的解码器结构,以实现高质量的图像重建。同时,通过分析扩散训练过程中的表示动态,提出了联合tokenizer-diffusion对齐策略,加速模型收敛。
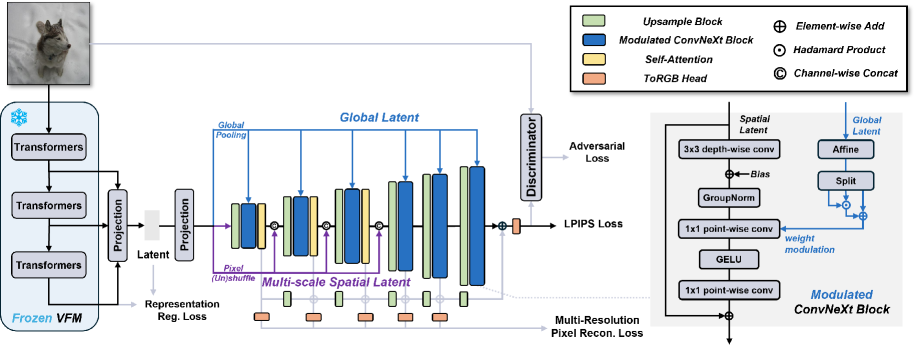
技术框架:VFM-VAE由VFM编码器和重新设计的解码器组成。VFM编码器直接提取输入图像的VFM特征。解码器采用多尺度潜在融合(Multi-Scale Latent Fusion)和渐进式分辨率重建(Progressive Resolution Reconstruction)块,将粗糙的VFM特征逐步重建为高分辨率图像。此外,还提出了SE-CKNNA指标来分析扩散训练过程中的表示动态,并据此调整tokenizer和diffusion模型的对齐策略。
关键创新:本文最重要的创新点在于直接利用VFM作为LDM的tokenizer,避免了蒸馏过程带来的信息损失,从而更好地利用了VFM的语义表征能力。此外,多尺度潜在融合和渐进式分辨率重建块的设计,以及SE-CKNNA指标的提出,也为高质量图像重建和模型训练提供了有效的技术手段。
关键设计:解码器中的多尺度潜在融合模块将不同尺度的VFM特征进行融合,以获取更丰富的语义信息。渐进式分辨率重建模块逐步提升图像分辨率,从而实现高质量的图像重建。SE-CKNNA指标用于衡量tokenizer和diffusion模型之间的对齐程度,并据此调整训练策略。损失函数包括重建损失和KL散度损失,用于保证图像重建质量和潜在空间的平滑性。
🖼️ 关键图片
📊 实验亮点
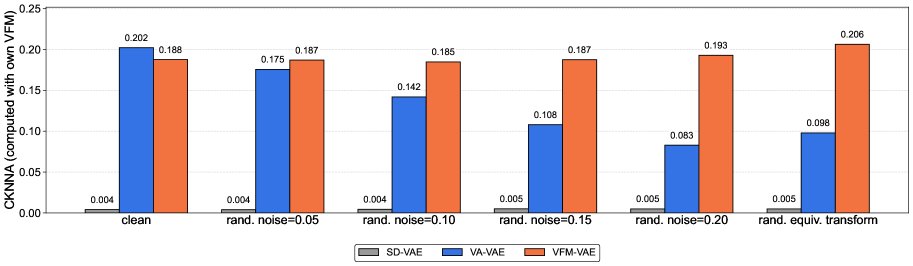
实验结果表明,VFM-VAE在图像生成任务上取得了显著的性能提升。在80个epoch的训练后,gFID(无CFG)达到了2.20,比之前的tokenizer快10倍。继续训练到640个epoch后,gFID(无CFG)进一步降低到1.62,证明了直接VFM集成作为LDM的卓越范例。
🎯 应用场景
该研究成果可广泛应用于图像生成、图像编辑、图像修复等领域。通过利用视觉基础模型的强大语义表征能力,可以生成更高质量、更符合语义信息的图像。此外,该方法还可以应用于其他生成模型,例如文本到图像生成模型,从而提升生成模型的性能和泛化能力。
📄 摘要(原文)
The performance of Latent Diffusion Models (LDMs) is critically dependent on the quality of their visual tokenizer. While recent works have explored incorporating Vision Foundation Models (VFMs) via distillation, we identify a fundamental flaw in this approach: it inevitably weakens the robustness of alignment with the original VFM, causing the aligned latents to deviate semantically under distribution shifts. In this paper, we bypass distillation by proposing a more direct approach: Vision Foundation Model Variational Autoencoder (VFM-VAE). To resolve the inherent tension between the VFM's semantic focus and the need for pixel-level fidelity, we redesign the VFM-VAE decoder with Multi-Scale Latent Fusion and Progressive Resolution Reconstruction blocks, enabling high-quality reconstruction from spatially coarse VFM features. Furthermore, we provide a comprehensive analysis of representation dynamics during diffusion training, introducing the proposed SE-CKNNA metric as a more precise tool for this diagnosis. This analysis allows us to develop a joint tokenizer-diffusion alignment strategy that dramatically accelerates convergence. Our innovations in tokenizer design and training strategy lead to superior performance and efficiency: our system reaches a gFID (w/o CFG) of 2.20 in merely 80 epochs (a 10x speedup over prior tokenizers). With continued training to 640 epochs, it further attains a gFID (w/o CFG) of 1.62, establishing direct VFM integration as a superior paradigm for LDMs.